Python实现计算信息熵的示例代码
顾城沐心 人气:0一:数据集准备
如博主使用的是:
多层感知机(MLP)实现考勤预测二分类任务(sklearn)对应数据集
导入至工程下
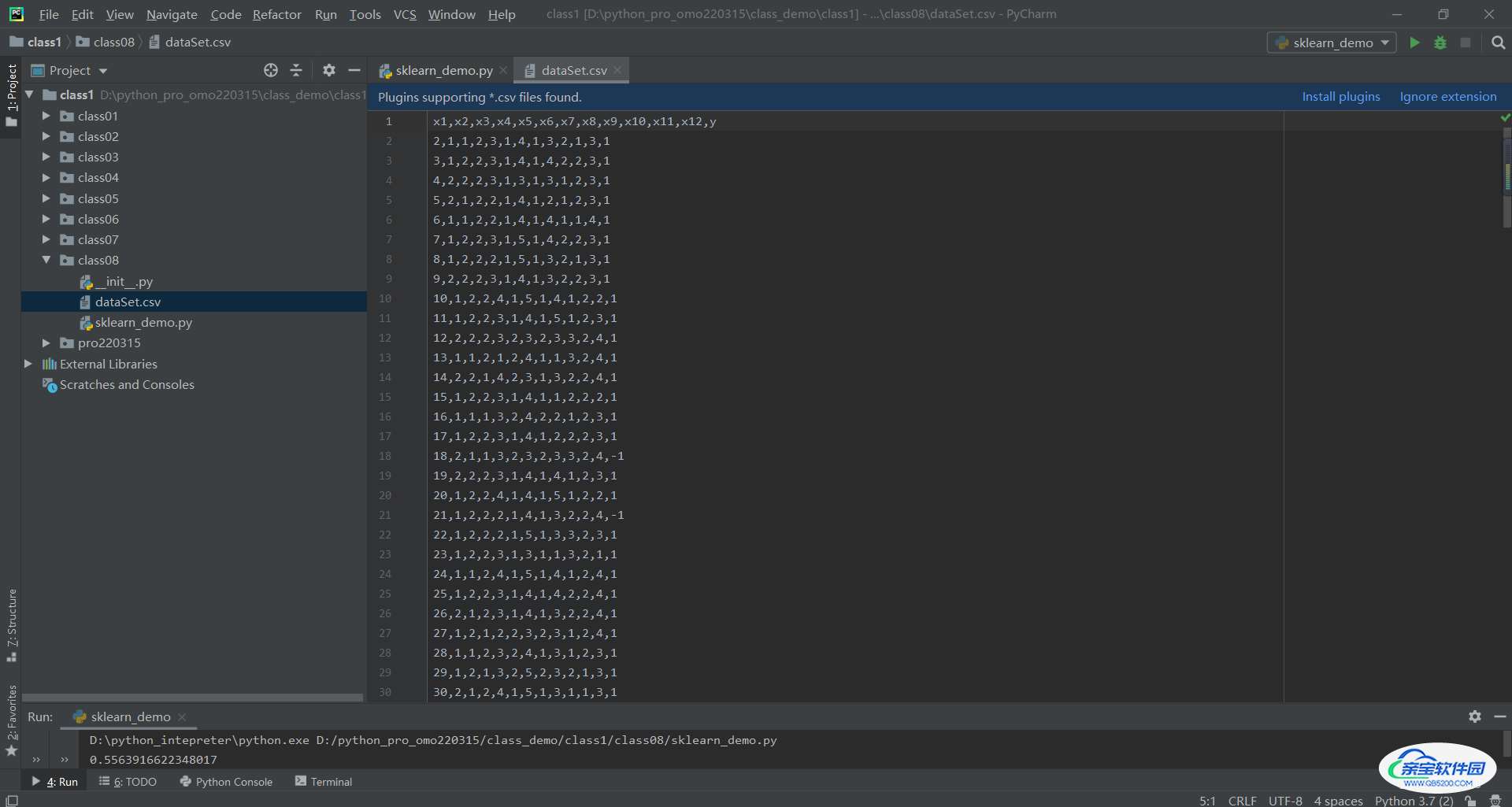
二:信息熵计算
1 导包
from math import log import pandas as pd
2 读取数据集
dataSet = pd.read_csv('dataSet.csv', header=None).values.tolist()
3 数据统计
numEntries = len(dataSet) # 数据集大小
labelCounts = {}
for featVec in dataSet: #
currentLabel = featVec[-1] # 获取分类标签
if currentLabel not in labelCounts.keys(): labelCounts[currentLabel] = 0 # 字典值不等于0???
labelCounts[currentLabel] += 1 # 每个类中数据个数统计
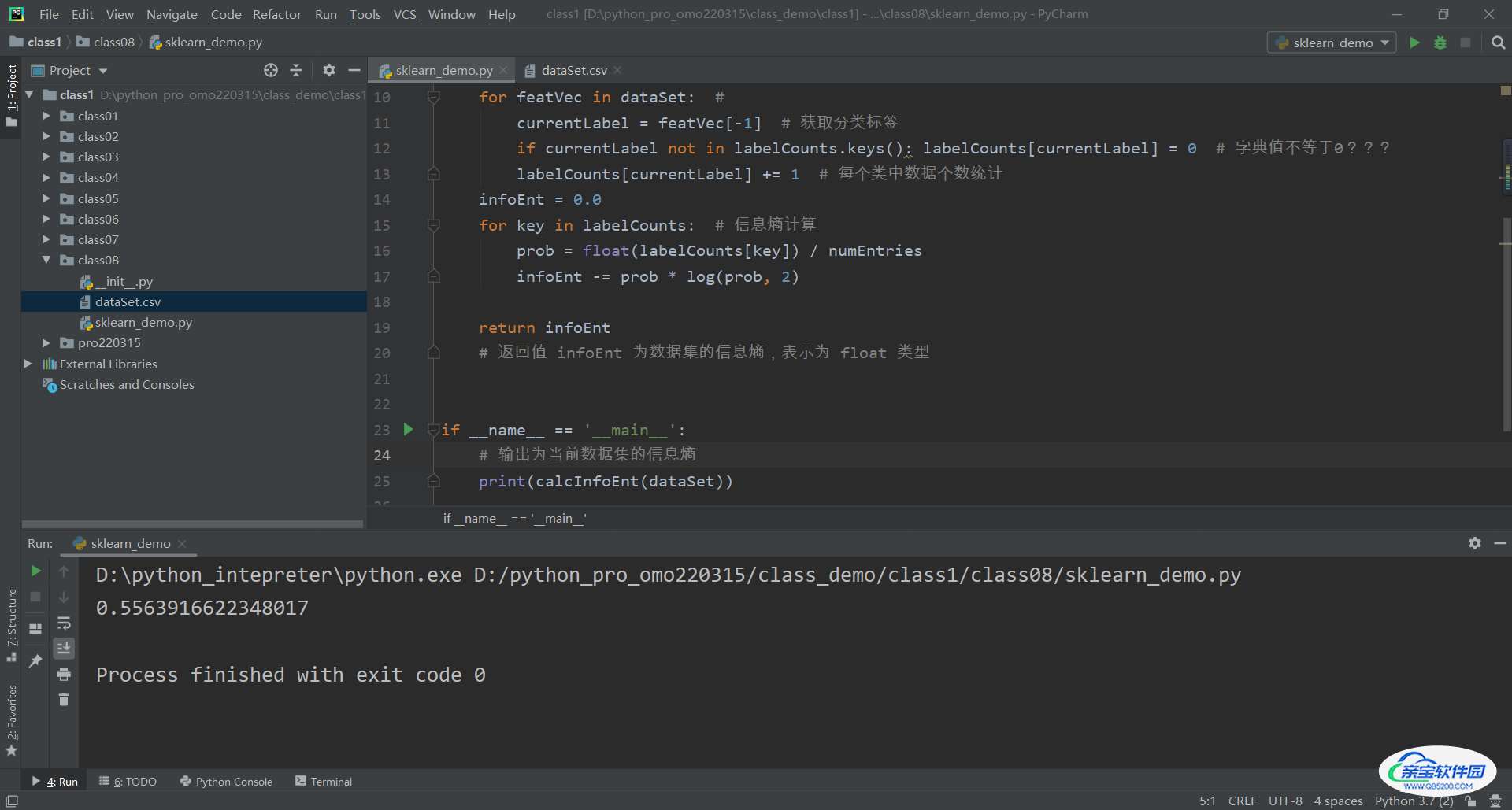
4 信息熵计算
infoEnt = 0.0
for key in labelCounts: # 信息熵计算
prob = float(labelCounts[key]) / numEntries
infoEnt -= prob * log(prob, 2)
return infoEnt
# 返回值 infoEnt 为数据集的信息熵,表示为 float 类型
测试运行,得到 多层感知机(MLP)实现考勤预测二分类任务(sklearn)对应数据集 信息熵为0.5563916622348017
三:完整源码分享
from math import log
import pandas as pd
dataSet = pd.read_csv('dataSet.csv', header=None).values.tolist()
def calcInfoEnt(dataSet):
numEntries = len(dataSet) # 数据集大小
labelCounts = {}
for featVec in dataSet: #
currentLabel = featVec[-1] # 获取分类标签
if currentLabel not in labelCounts.keys(): labelCounts[currentLabel] = 0 # 字典值不等于0???
labelCounts[currentLabel] += 1 # 每个类中数据个数统计
infoEnt = 0.0
for key in labelCounts: # 信息熵计算
prob = float(labelCounts[key]) / numEntries
infoEnt -= prob * log(prob, 2)
return infoEnt
# 返回值 infoEnt 为数据集的信息熵,表示为 float 类型
if __name__ == '__main__':
# 输出为当前数据集的信息熵
print(calcInfoEnt(dataSet))四:方法补充
熵,在信息论中是用来刻画信息混乱程度的一种度量。熵最早源于热力学,后应广泛用于物理、化学、信息论等领域。1850年,德国物理学家鲁道夫·克劳修斯首次提出熵的概念,用来表示任何一种能量在空间中分布的均匀程度。1948年,Shannon在Bell System Technical Journal上发表文章“A Mathematical Theory of Communication”,将信息熵的概念引入信息论中。本文所说的熵就是Shannon熵,即信息熵,解决了对信息的量化度量问题。
下面是小编为大家收集的计算信息熵的另一种方法,希望对大家有所帮助
import math
#以整型数据为例,给出其信息熵的计算程序。
###########################################
'''统计已知数据中的不同数据及其出现次数'''
###########################################
def StatDataInf( data ):
dataArrayLen = len( data )
diffData = [];
diffDataNum = [];
dataCpy = data;
for i in range( dataArrayLen ):
count = 0;
j = i
if( dataCpy[j] != '/' ):
temp = dataCpy[i]
diffData.append( temp )
while( j < dataArrayLen ):
if( dataCpy[j] == temp ):
count = count + 1
dataCpy[j] = '/'
j = j + 1
diffDataNum.append( count )
return diffData, diffDataNum
###########################################
'''计算已知数据的熵'''
###########################################
def DataEntropy( data, diffData, diffDataNum ):
dataArrayLen = len( data )
diffDataArrayLen = len( diffDataNum )
entropyVal = 0;
for i in range( diffDataArrayLen ):
proptyVal = diffDataNum[i] / dataArrayLen
entropyVal = entropyVal - proptyVal * math.log2( proptyVal )
return entropyVal
def main():
data = [1, 2, 1, 2, 1, 2, 1, 2, 1, 2 ]
[diffData, diffDataNum] = StatDataInf( data )
entropyVal = DataEntropy( data, diffData, diffDataNum )
print( entropyVal )
data = [1, 2, 1, 2, 2, 1, 2, 1, 1, 2, 1, 1, 1, 1, 1 ]
[diffData, diffDataNum] = StatDataInf( data )
entropyVal = DataEntropy( data, diffData, diffDataNum )
print( entropyVal )
data = [1, 2, 3, 4, 2, 1, 2, 4, 3, 2, 3, 4, 1, 1, 1 ]
[diffData, diffDataNum] = StatDataInf( data )
entropyVal = DataEntropy( data, diffData, diffDataNum )
print( entropyVal )
data = [1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4 ]
[diffData, diffDataNum] = StatDataInf( data )
entropyVal = DataEntropy( data, diffData, diffDataNum )
print( entropyVal )
data = [1, 2, 3, 4, 5, 1, 2, 3, 4, 5, 1, 2, 3, 4, 5, 1, 2, 3, 4, 5, 1, 2, 3, 4, 1, 2, 3, 4, 5 ]
[diffData, diffDataNum] = StatDataInf( data )
entropyVal = DataEntropy( data, diffData, diffDataNum )
print( entropyVal )
if __name__ == '__main__':
main()
###########################################
#运行结果
1.0
0.9182958340544896
1.965596230357602
2.0
2.3183692540329317加载全部内容