python利用json和pyecharts画折线图实例代码
阳862 人气:0
注:本次实验的数据在文章最后面,我已上传至百度网盘
一.json模块对数据进行处理

上面三个txt文本是这三个国家疫情爆发相关的数据
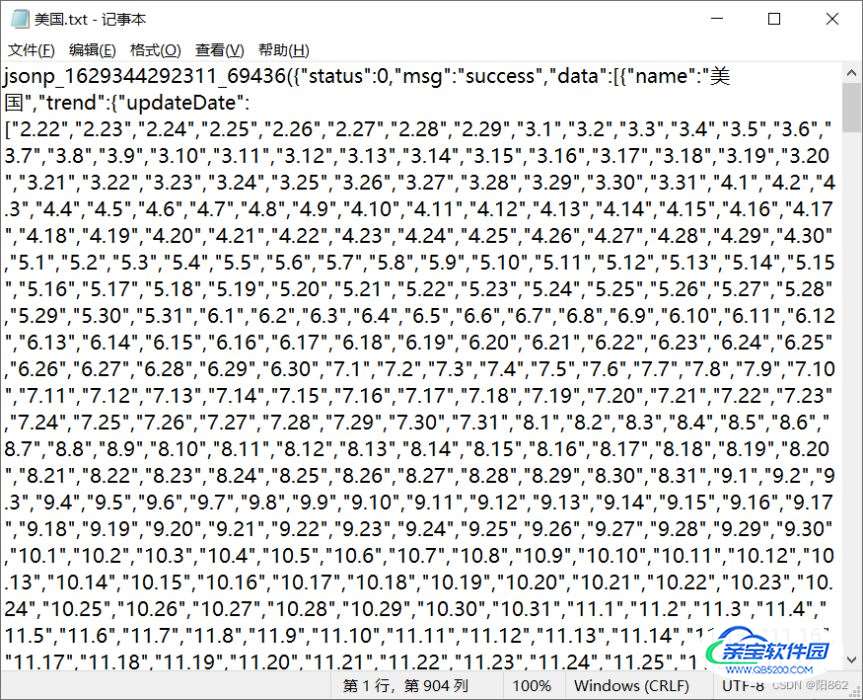
我们先以美国为例
我们可以看到,这文件里面有些地方不符合json格式,所以在用改文件之前就需要我们去处理

处理json格式的数据我们需要借用json在线解析工具
我这里用的是:

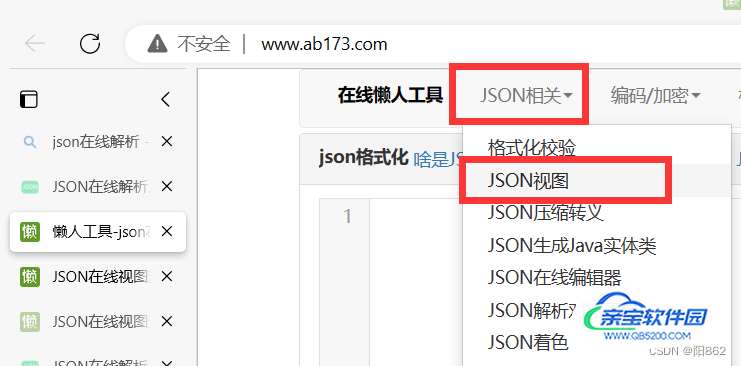

将正确格式复制粘贴到“json数据”中,然后再点击“视图”
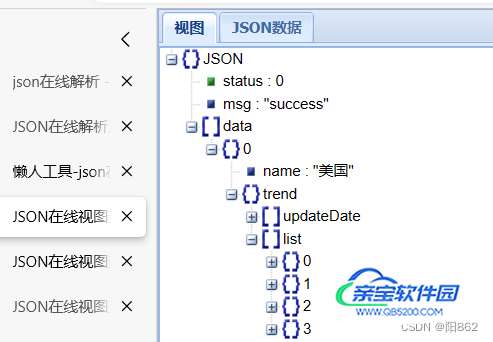
这里就会给我们一个流程图
这里我们就要开始分析:
我们需要的是,美国疫情确诊人随时间的变化,我们依次打开就可以找到

这两个部分就是我们需要的 ,我们可以知道这里json是一个字典类型,那么我们就是先要从json中找到data这个key,data是一个列表嵌套一个字典,所以我们用data[0]就可以取得列表里面的内容,从列表里面找到trend这个key,然后同理,再从trend这个字典中找出updateData和data
代码如下
import json
from pyecharts.charts import Line
from pyecharts.options import TitleOpts
#处理数据
f_us=open("D:/美国.txt","r",encoding="utf-8")
us_data=f_us.read()
#去掉不合json规范的开头
us_data=us_data.replace("jsonp_1629344292311_69436(","")
#去掉不合JSON规范的结尾
us_data=us_data[:-2]
#json转python字典
us_dict = json.loads(us_data)
#获取trend key
trend_data=us_dict["data"][0]["trend"]
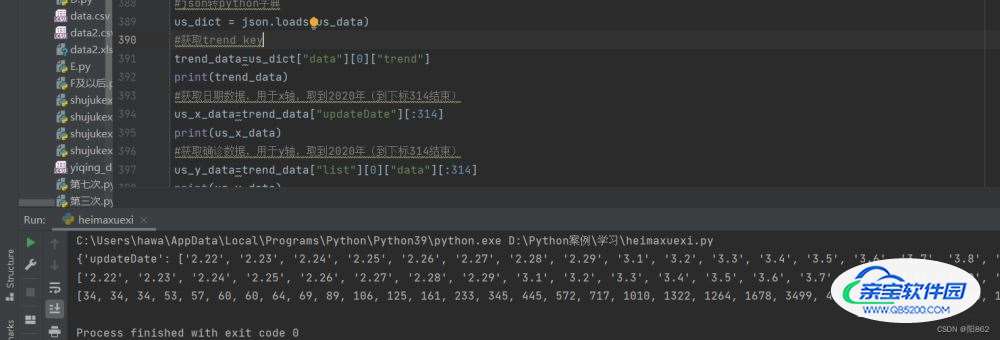
print(trend_data)
#获取日期数据,用于x轴,取到2020年(到下标314结束)
us_x_data=trend_data["updateDate"][:314]
print(us_x_data)
#获取确诊数据,用于y轴,取到2020年(到下标314结束)
us_y_data=trend_data["list"][0]["data"][:314]
print(us_y_data)结果是
二.利用pyecharts画折线图
import json
from pyecharts.charts import Line
from pyecharts.options import TitleOpts
#处理数据
f_us=open("D:/美国.txt","r",encoding="utf-8")
us_data=f_us.read()
#去掉不合json规范的开头
us_data=us_data.replace("jsonp_1629344292311_69436(","")
#去掉不合JSON规范的结尾
us_data=us_data[:-2]
#json转python字典
us_dict = json.loads(us_data)
#获取trend key
trend_data=us_dict["data"][0]["trend"]
print(trend_data)
#获取日期数据,用于x轴,取到2020年(到下标314结束)
us_x_data=trend_data["updateDate"][:314]
print(us_x_data)
#获取确诊数据,用于y轴,取到2020年(到下标314结束)
us_y_data=trend_data["list"][0]["data"][:314]
print(us_y_data)
#生成图表
line=Line()#构建折线图对象
#添加x轴对象
line.add_xaxis(us_x_data)
#添加y周数据
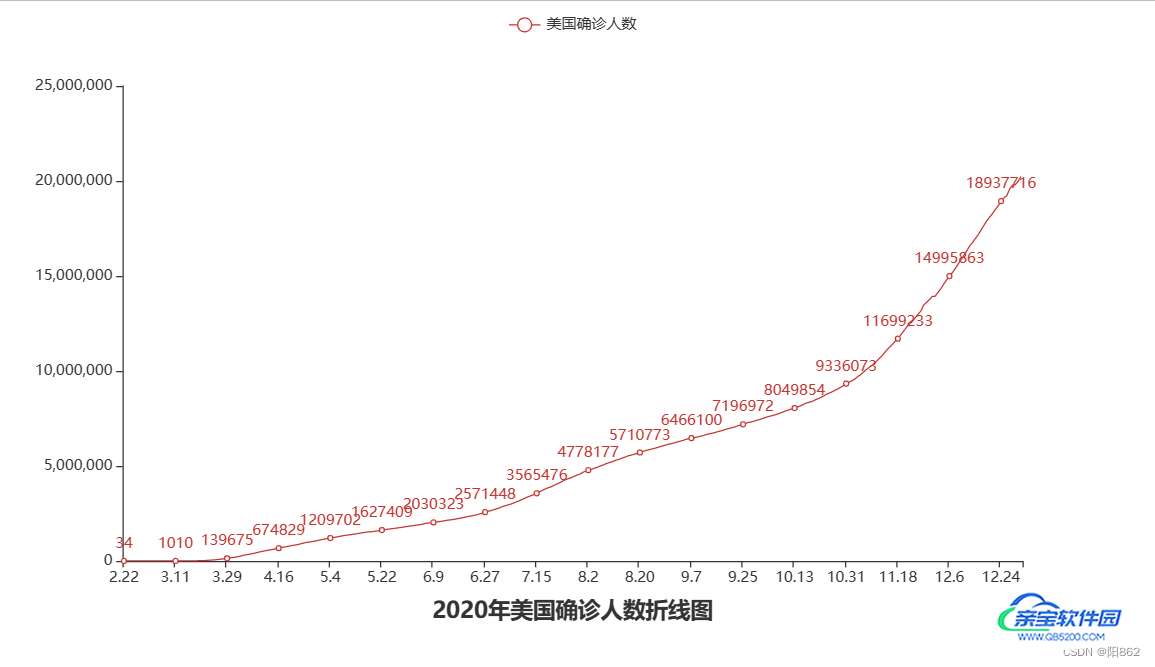
line.add_yaxis("美国确诊人数",us_y_data)
#设置全局变量
line.set_global_opts(
title_opts=TitleOpts(title="2020年美国确诊人数折线图",pos_left="center",pos_bottom="1%")
)
#调用render方法,生成图表
line.render()
#关闭文件
f_us.close()
结果是
三.利用pyecharts画美、日、印三国家折线图
日本和印度的数据处理部分,跟美国的处理方法是一样的,代码如下:
import json
from pyecharts.charts import Line
from pyecharts.options import TitleOpts
#处理数据
f_us=open("D:/美国.txt","r",encoding="utf-8")
f_jp=open("D:/日本.txt","r",encoding="utf-8")
f_in=open("D:/印度.txt","r",encoding="utf-8")
us_data=f_us.read()
jp_data=f_jp.read()
in_data=f_in.read()
#去掉不合json规范的开头
us_data=us_data.replace("jsonp_1629344292311_69436(","")
jp_data=jp_data.replace("jsonp_1629350871167_29498(","")
in_data=in_data.replace("jsonp_1629350745930_63180(","")
#去掉不合JSON规范的结尾
us_data=us_data[:-2]
jp_data=jp_data[:-2]
in_data=in_data[:-2]
#json转python字典
us_dict = json.loads(us_data)
jp_dict = json.loads(jp_data)
in_dict = json.loads(in_data)
#获取trend key
us_trend_data=us_dict["data"][0]["trend"]
jp_trend_data=jp_dict["data"][0]["trend"]
in_trend_data=in_dict["data"][0]["trend"]
#获取日期数据,用于x轴,取到2020年(到下标314结束)
us_x_data=us_trend_data["updateDate"][:314]
jp_x_data=jp_trend_data["updateDate"][:314]
in_x_data=in_trend_data["updateDate"][:314]
#获取确诊数据,用于y轴,取到2020年(到下标314结束)
us_y_data=us_trend_data["list"][0]["data"][:314]
jp_y_data=jp_trend_data["list"][0]["data"][:314]
in_y_data=in_trend_data["list"][0]["data"][:314]
#生成图表
line=Line()#构建折线图对象
#添加x轴对象
line.add_xaxis(us_x_data)#因为x轴都是一样的,所以就用一个就可
#添加y周数据
line.add_yaxis("美国确诊人数",us_y_data)
line.add_yaxis("日本确诊人数",jp_y_data)
line.add_yaxis("印度确诊人数",in_y_data)
#设置全局变量
line.set_global_opts(
title_opts=TitleOpts(title="2020年美国、日本、印度确诊人数折线图",pos_left="center",pos_bottom="1%")
)
#调用render方法,生成图表
line.render()
#关闭文件
f_us.close()
f_jp.close()
f_in.close()
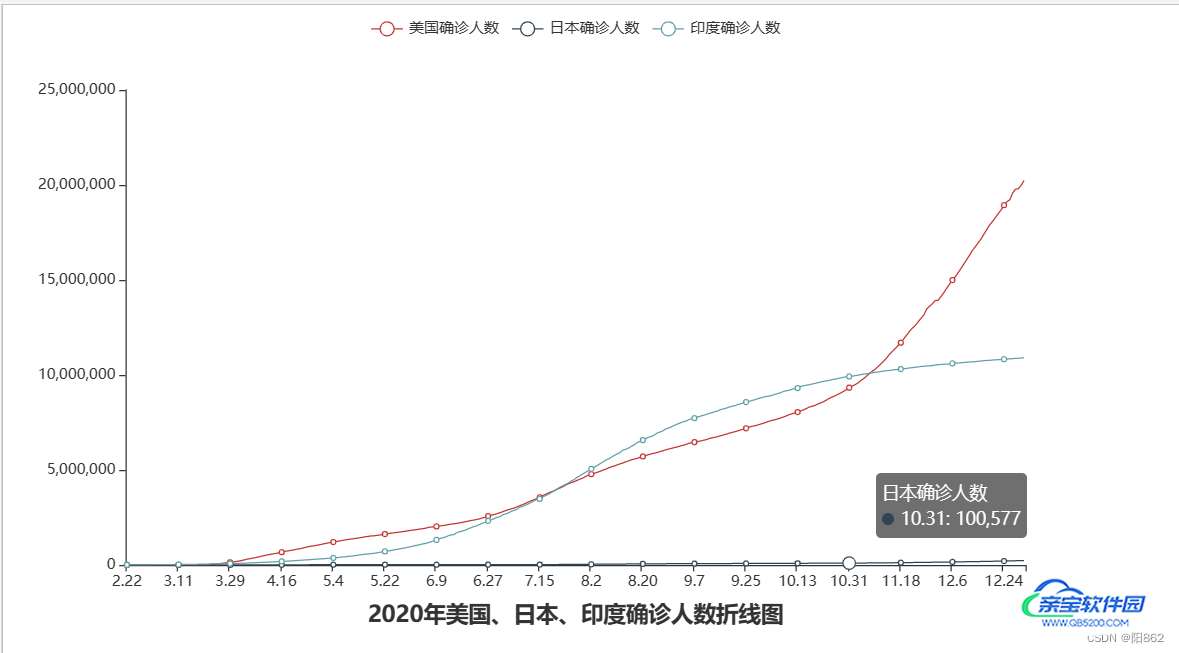
结果是

还有一个下问题:很多数字重叠了
我们可以利用全局选项中的图例来解决,让其不显示
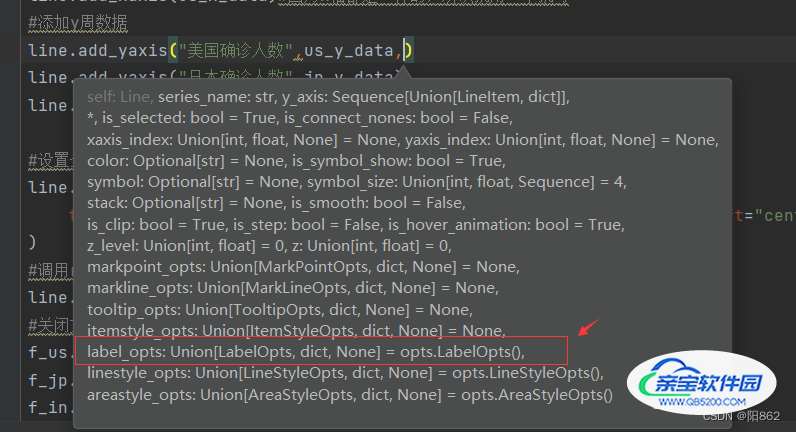
按下Ctrl+p就会显示有哪些位置参数,label_opts就是控制图例的
#添加y周数据
line.add_yaxis("美国确诊人数",us_y_data,label_opts=False)
line.add_yaxis("日本确诊人数",jp_y_data,label_opts=False)
line.add_yaxis("印度确诊人数",in_y_data,label_opts=False)结果是
四.本文数据集
链接: http://pan.baidu.com/s/1L1Z-lkErmUZqgJxlGW_xAQ?pwd=7par
提取码: 7par
加载全部内容