基于SpringBoot 使用 Flink 收发Kafka消息的示例详解
dk168 人气:0前言
这周学习下Flink相关的知识,学习到一个读写Kafka消息的示例, 自己动手实践了一下,别人示例使用的是普通的Java Main方法,没有用到spring boot. 我们在实际工作中会使用spring boot。 因此我做了些加强, 把流程打通了,过程记录下来。
准备工作
首先我们通过docker安装一个kafka服务,参照Kafka的官方知道文档
https://developer.confluent.io/tutorials/kafka-console-consumer-producer-basics/kafka.html主要的是有个docker-compose.yml文件
---
version: '2'
services:
zookeeper:
image: confluentinc/cp-zookeeper:7.3.0
hostname: zookeeper
container_name: zookeeper
ports:
- "2181:2181"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
broker:
image: confluentinc/cp-kafka:7.3.0
hostname: broker
container_name: broker
depends_on:
- zookeeper
ports:
- "29092:29092"
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: 'zookeeper:2181'
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://broker:9092,PLAINTEXT_HOST://localhost:29092
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0docker compose up -d
就可以把kafka docker 环境搭起来,
使用以下命令,创建一个flink.kafka.streaming.source的topic
docker exec -t broker kafka-topics --create --topic flink.kafka.streaming.source --bootstrap-server broker:9092
然后使用命令,就可以进入到kafka机器的命令行
docker exec -it broker bash
官方文档示例中没有-it, 运行后没有进入broker的命令行,加上来才可以。这里说明下
Flink我们打算直接采用开发工具运行,暂时未搭环境,以体验为主。
开发阶段
首先需要引入的包POM文件
<properties>
<jdk.version>1.8</jdk.version>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<spring-boot.version>2.7.7</spring-boot.version>
<flink.version>1.16.0</flink.version>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>${spring-boot.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
</dependencies>这里我们使用Java8, 本来想使用Spring Boot 3的,但是Spring Boot 3 最低需要Java17了, 目前Flink支持Java8和Java11,所以我们使用Spring Boot 2, Java 8来开发。
spring-boot-starter 我们就一个命令行程序,所以用这个就够了
lombok 用来定义model
flink-java, flink-clients, flink-streaming-java 是使用基本组件, 缺少flink-clients编译阶段不会报错,运行的时候会报java.lang.IllegalStateException: No ExecutorFactory found to execute the application.
flink-connector-kafka 是连接kafka用
我们这里把provided, 打包的时候不用打包flink相关组件,由运行环境提供。但是IDEA运行的时候会报java.lang.NoClassDefFoundError: org/apache/flink/streaming/util/serialization/DeserializationSchema,
在运行的configuration上面勾选上“add dependencies with provided scope to classpath”可以解决这个问题。
主要代码
@Component
@Slf4j
public class KafkaRunner implements ApplicationRunner
{
@Override
public void run(ApplicationArguments args) throws Exception {
try{
/****************************************************************************
* Setup Flink environment.
****************************************************************************/
// Set up the streaming execution environment
final StreamExecutionEnvironment streamEnv
= StreamExecutionEnvironment.getExecutionEnvironment();
/****************************************************************************
* Read Kafka Topic Stream into a DataStream.
****************************************************************************/
//Set connection properties to Kafka Cluster
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "localhost:29092");
properties.setProperty("group.id", "flink.learn.realtime");
//Setup a Kafka Consumer on Flnk
FlinkKafkaConsumer<String> kafkaConsumer =
new FlinkKafkaConsumer<>
("flink.kafka.streaming.source", //topic
new SimpleStringSchema(), //Schema for data
properties); //connection properties
//Setup to receive only new messages
kafkaConsumer.setStartFromLatest();
//Create the data stream
DataStream<String> auditTrailStr = streamEnv
.addSource(kafkaConsumer);
//Convert each record to an Object
DataStream<Tuple2<String, Integer>> userCounts
= auditTrailStr
.map(new MapFunction<String,Tuple2<String,Integer>>() {
@Override
public Tuple2<String,Integer> map(String auditStr) {
System.out.println("--- Received Record : " + auditStr);
AuditTrail at = new AuditTrail(auditStr);
return new Tuple2<String,Integer>(at.getUser(),at.getDuration());
}
})
.keyBy(0) //By user name
.reduce((x,y) -> new Tuple2<String,Integer>( x.f0, x.f1 + y.f1));
//Print User and Durations.
userCounts.print();
/****************************************************************************
* Setup data source and execute the Flink pipeline
****************************************************************************/
//Start the Kafka Stream generator on a separate thread
System.out.println("Starting Kafka Data Generator...");
Thread kafkaThread = new Thread(new KafkaStreamDataGenerator());
kafkaThread.start();
// execute the streaming pipeline
streamEnv.execute("Flink Windowing Example");
}
catch(Exception e) {
e.printStackTrace();
}
}
}
简单说明下程序
DataStream auditTrailStr = streamEnv
.addSource(kafkaConsumer);
就是接通了Kafka Source
Thread kafkaThread = new Thread(new KafkaStreamDataGenerator());
kafkaThread.start();这段代码是另外开一个线程往kafka里面去发送文本消息
我们在这个示例中就是一个线程发,然后flink就读出来,然后统计出每个用户的操作时间。
auditTrailStr.map 就是来进行统计操作。
运行效果
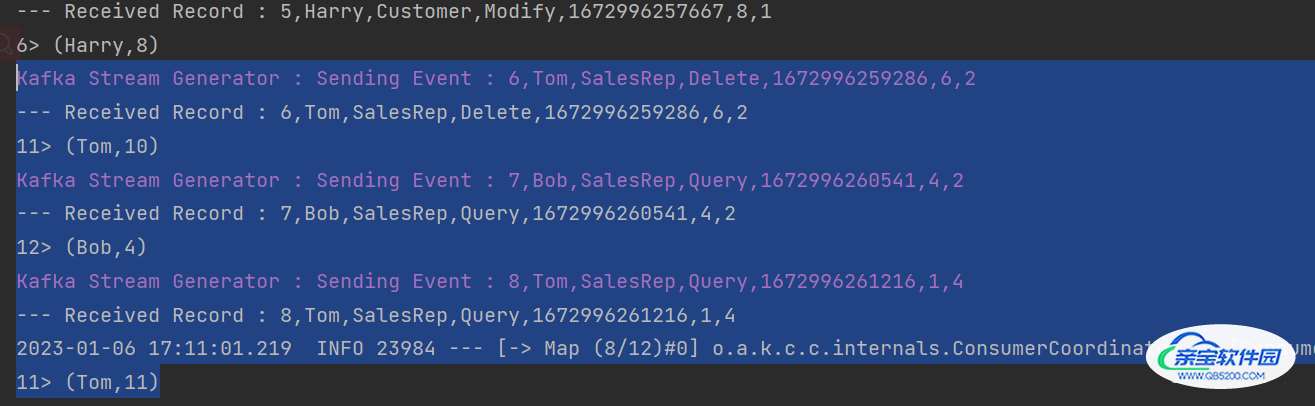
可以看到Kafka一边发送,然后我们就一边读出来,然后就统计出了每个用户的时间。
总结
本文只是简单的打通了几个环节,对于flink的知识没有涉及太多,算是一个环境入门。后面学习更多的以后我们再深入些来记录flink. 示例代码会放到 https://github.com/dengkun39/redisdemo.git spring-boot-flink 文件夹。
加载全部内容