Python获取信息
斜月 人气:21 前言
上篇文章Python爬虫获取基金列表我们已经讲述了如何从基金网站上获取基金的列表信息。这一骗我们延续上一篇,继续分享如何抓取基金的基本信息做展示。展示的内容包括基金的基本信息,诸如基金公司,基金经理,创建时间以及追踪标、持仓明细等信息。
2 如何抓取基本信息
# 在这里我就直接贴地址了,这个地址的获取是从基金列表跳转,然后点基金概况就可以获取到了。 http://fundf10.eastmoney.com/jbgk_005585.html
基金的详情页面和基金的基本信息页面:
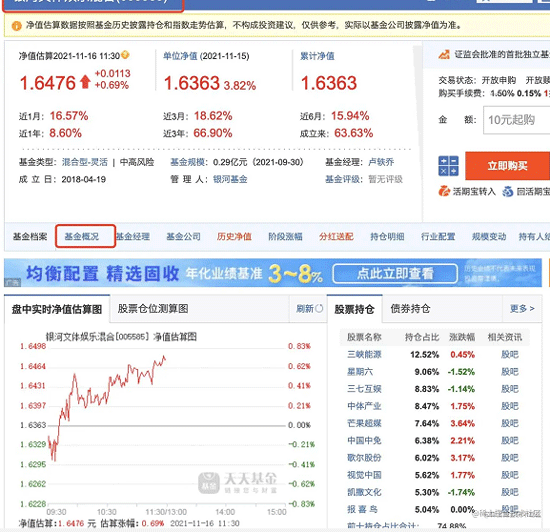

现在我们需要做的事情就是怎么把基金的基本概况数据抓取下来,很遗憾,这个工作不像上次那样可以直接通过接口调用的方式获取结果,而是需要我们解析页面html,通过获取元素来解析我们所需要的信息。这时我们就需要使用xpath来获取所需要的元素。
3 xpath 获取数据
解析html 数据,我们通常使用 xpath 来获取页面的数据,在这里我们也首选这个 xpath,那么怎么使用呢?首先需要安装相关的类库。
# 安装 lxml pip install lxml
使用浏览器打开,然后点击[检查]使用选择基金基本信息,然后如图所示选择[copy XPath],可以获取到数据所在的表格位置
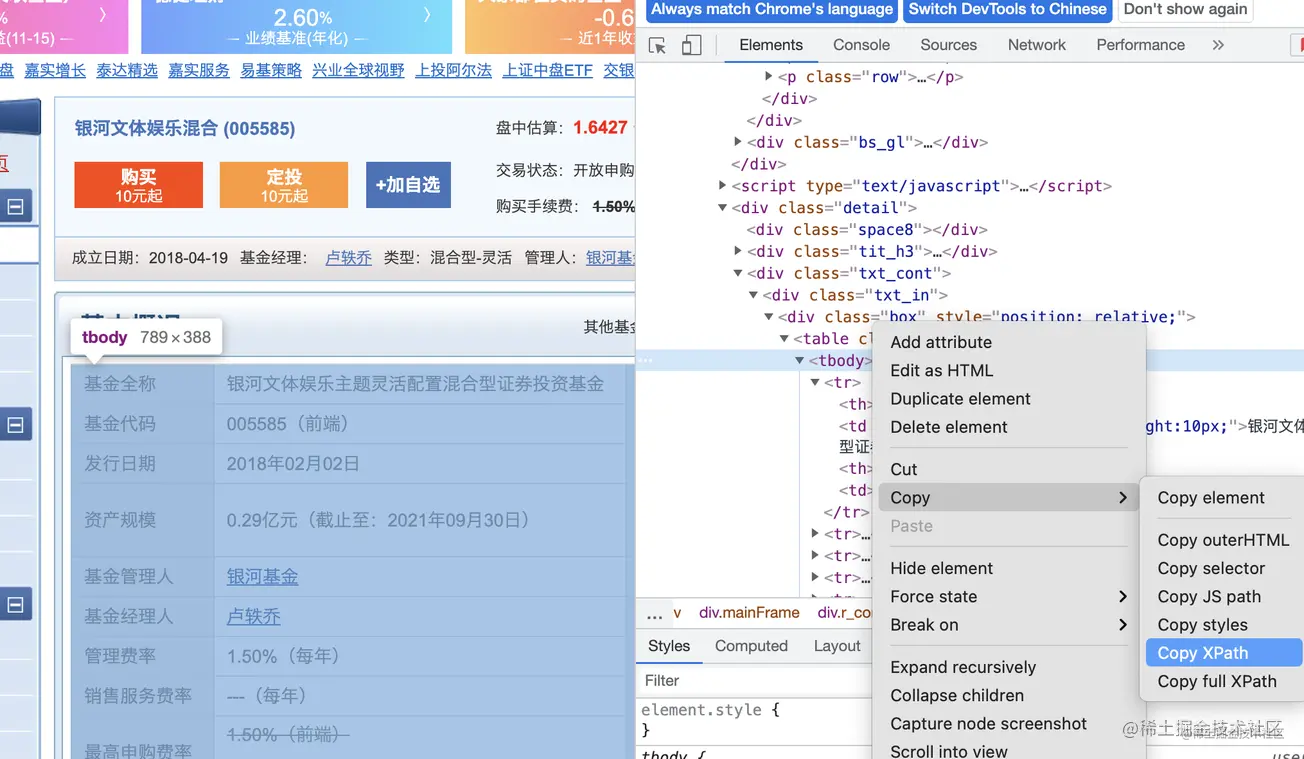
from lxml import etree
# ...
# 将返回的数据结果进行解析,形成 html 文档
html = etree.HTML(resp_body)
result = etree.tostring(html, pretty_print=True)
# 打印获取到的结果
print(result)
# 抓取数据的位置,这个地方的数据是通过浏览器的 xpath 定位来确定的
table_body = html.xpath('//*[@id="bodydiv"]/div[8]/div[3]/div[2]/div[3]/div/div[1]/table/tbody')
# 打印数据结果
print(table_body)按照常理来说,这里应该可以获取到基金基本新的结果,但是万万没想到呀,竟然失算了,获取到的结果竟然为空,百思不得其解。我还以为是api使用的不够熟练,不能正确的获取,直到我仔细研究了返回的页面信息,才看到根本没有 tbody 这个元素,可能是浏览器渲染后导致的结果,也就是说通过 xpath 来定位元素位置来获取数据这条路可能不行。事实上也确实是如此,基金基本信息的数据是放在页面的 scripts 标签里面的,所以这个条真的就行不通了。可能通过xpath是配合Selenium一起使用做页面自动化测试的,这个有机会再去研究吧。
4 bs4 获取数据
既然直接获取页面元素的方式行不通,那么就只有解析返回页面来获取数据了,java 语言的话可以使用 joup来解析获取数据,但是python又如何来操作呢?这就需要使用 bs4 来解决了。安装方式如下:
# 简称bs4,python解析html非常好用的第三方类库 pip install beautifulsoup4
其主要使用的解析方法如下图所示,接下来我们使用lxml来解析html数据,如何使用html5lib的话,需要先进行安装才能使用 pip install html5lib。
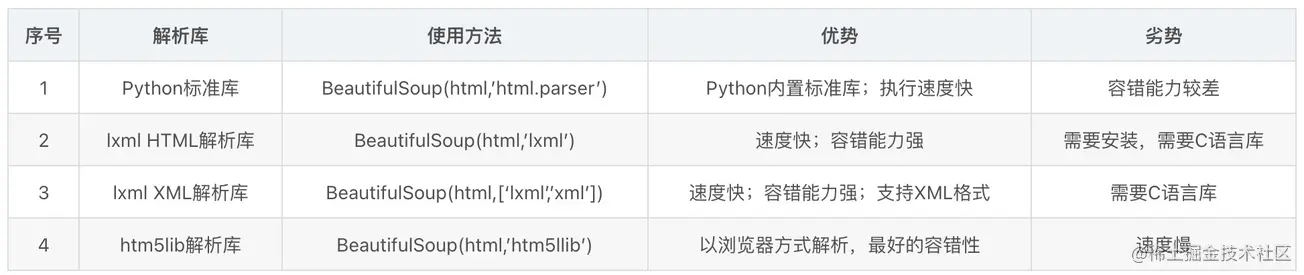
解析数据的思路是这样的,我们看到浏览器返回的结果是包含 table>tr>td 这样的结构,我们先获取到基金对应信息的table,然后获取到table中的 td,因为这个表格展示内容是固定的,我们选取对应的数据下标即可获取对应的数据。
# 解析返回的报文
soup = BeautifulSoup(resp_body, 'lxml')
# 获取数据的table标签所有数据
body_list = soup.find_all("table")
# 基金信息对应的是第二个
basic_info = body_list[1]
# 打印结果并循环输出td的内容
print(basic_info)
td_list = basic_info.find_all("td")
for node in td_list:
print(node.get_text())这里涉及两个方法find_all和get_text,第一个是元素选择器,可以根据标签class进行搜索,第二个是获取元素中的内容。

5 最终结果展现
经常不断的尝试,最终的最简版代码如下所示:
from lxml import etree
import requests
from prettytable import PrettyTable
import datetime
# 使用BeautifulSoup解析网页
from bs4 import BeautifulSoup
# 获取基金基本信息
def query_fund_basic(code):
# http://fundf10.eastmoney.com/jbgk_005585.html
response = requests.get("http://fundf10.eastmoney.com/jbgk_{}.html".format(code))
resp_body = response.text
soup = BeautifulSoup(resp_body, 'lxml')
body_list = soup.find_all("table")
basic_info = body_list[1]
# print(basic_info)
tr_list = basic_info.find_all("td")
# 暂存一下列表
tmp_list = []
tmp_list.append(tr_list[2].get_text().replace("(前端)", ""))
tmp_list.append(tr_list[1].get_text())
tmp_list.append(tr_list[8].get_text())
tmp_list.append(tr_list[10].get_text())
tmp_list.append(tr_list[5].get_text().split("/")[0].strip())
tmp_list.append(tr_list[5].get_text().split("/")[1].strip().replace("亿份", ""))
tmp_list.append(tr_list[3].get_text())
tmp_list.append(tr_list[18].get_text())
tmp_list.append(tr_list[19].get_text())
return tmp_list
if __name__ == '__main__':
print("start analyze !")
code_list = ["005585", "000362"]
# 需要关注的基本信息如右所示 基金代码 基金名称 基金公司 基金经理 创建时间
# 基金份额 基金类型 业绩基准 跟踪标的
head_list = ["code", "name", "company", "manager", "create_time",
"fund_share", "fund_type", "comp_basic", "idx_target"]
# 生成表格对象
tb = PrettyTable()
tb.field_names = head_list # 定义表头
for node in code_list:
tb.add_row(query_fund_basic(node))
# 输出表格
print(tb)
reslt = str(tb).replace("+", "|")
print(reslt)最终打印的结果如下所示,感觉很期待:

接来下我们会利用数据库进行存储基金的基本信息,然后基于此才能抓取基金的变动信息进行分析,距离激动人心的时刻已经很近了。
加载全部内容