Python获取信息
斜月 人气:01 前言
前面文章Python爬虫获取基金列表、Python爬虫获取基金基本信息我们已经介绍了怎么获取基金列表以及怎么获取基金基本信息,本文我们继续前面的内容,获取基金的变动信息。这次获取信息的方式将组合使用页面数据解析和api接口调用的方式进行。
2 抓取变动信息
我们通过观察基金基本信息页面,我们可以发现有关基金变动信息的页面可以包含以下4个部分:
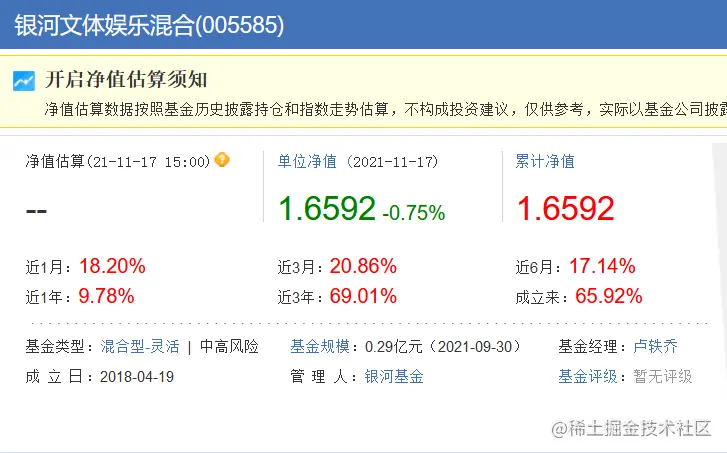
接下来说一下我们抓取数据的思路,在第一个图中我们已经得到了基金的基本信息,变动信息和阶段涨幅,但是阶段涨幅已经在第2个图中得到了展示,所以在这个图中,我们只需要获取实时的涨跌以及前一日的基金净值即可。
2.1 基金的变动信息获取
# 基金的变动信息,我们还是从一个简单的连接开始,其他基金的获取方式是和这个类似, # 访问地址换上其他的基金代码即可。 http://fund.eastmoney.com/005585.html
这里获取变动分为两个部分,一部分是实时获取基金的变动新,会发现净值估算是过一段时间会发生变化,通过监控浏览器的访问请求记录,抓取到了这样一个api访问,瞬间就乐开了花。
// http://fundgz.1234567.com.cn/js/005585.js
{
'fundcode': '005585',
'name': '银河文体娱乐混合',
'jzrq': '2021-11-16',
'dwjz': '1.6718',
'gsz': '1.6732',
'gszzl': '0.08',
'gztime': '2021-11-17 15:00'
}
基金代码和基金名称可以根据json返回的内容可以知道,但是 jzrq,dwjz,gsz,gszzl,gztime都是什么意思呢,我仔细研究了很长时间,结合页面上展示的内容,再加上dfcf编码中文拼音的首字母的习惯,我猜这些字段的意思大致是净值日期、单位净值、估算值、估算增长率、估算时间。我都有点儿沾沾自喜了,竟然破解出来了其中的奥义。
第二部分是获取基金的单位净值,这个通过分析发现数据是包含在一个<dl class="dataItem02"> 的 html 元素中的,我们获取的方式是通过 bs4的方式解析返回页面信息来抓取元素解析dom树来获取。
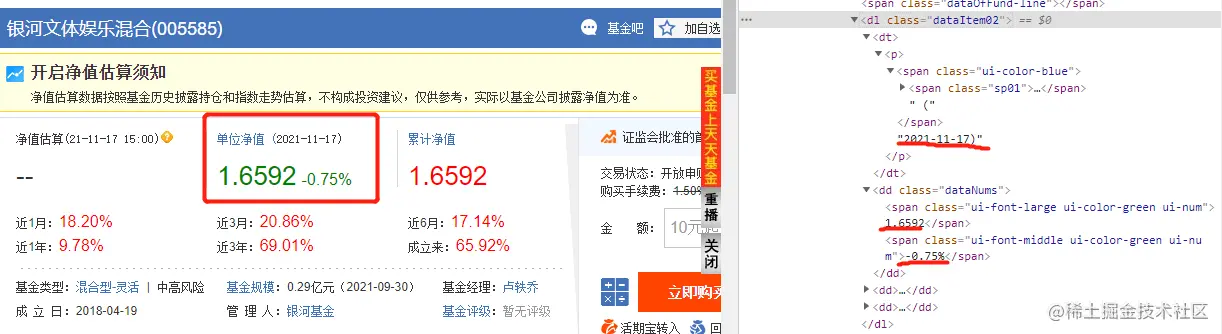
总结一下就是我们通过 api 接口调用来获取基金的实时变动信息,通过解析返回的 html,解析dom树来获取基金的单位净值信息。以下是第一部分抓取信息的代码。
# 抓取基金实时变动信息
resp = requests.get("http://fundgz.1234567.com.cn/js/{}.js".format(code))
# 去除js的呢绒方便进行数据的json转化
data = resp.text.replace("jsonpgz(", "").replace(");", "")
body = json.loads(data)
# 输出获取到的结果数据
print("{} {} 估算值 {} 估算涨跌 {} 估算时间 {}".format(body["fundcode"], body["name"], body["gsz"], body["gszzl"], body["gztime"]))
# 请求获取基金页面的信息
response = requests.get("http://fund.eastmoney.com/{}.html".format(code))
# 打印原始的请求返回报文编码方式
# print(response.apparent_encoding)
# 设置请求的返回内容编码方式,避免出现控制台乱码的情况
response.encoding = "UTF-8"
resp_body = response.text
# 进行数据的转换和解析
soup = BeautifulSoup(resp_body, 'lxml')
# 因为确定了只有一个元素,因此可以使用 find 发放来获取数据,这个就是查找 dl标签,class=dataItem02 的元素
dl_con = soup.find("dl", class_="dataItem02")
# 获取基金净值的更新时间
value_date = dl_con.find("p").get_text()
# 只提取基金数据的时间即可
value_date = value_date.replace("单位净值", "").replace("(", "").replace(")", "")
# 净值数据和涨跌百分比数据是在dd标签下的两个p标签中
value_con = dl_con.find("dd", class_="dataNums")
data_list = value_con.find_all("span")
val_data = data_list[0].get_text()
per_data = data_list[1].get_text()
print("基金净值日期 {} 净值数据 {} 涨跌百分比 {}".format(value_date, val_data, per_data))最终,我们通过以上的操作,就可以获取到基金的变动信息。
2.2 基金阶段信息的抓取
基金的阶段信息抓取也是采用 bs4 解析页面数据的方式进行操作,这里分为三个图,第一个图展示的是阶段的涨跌信息,第二个和第三个是季度和年度的涨跌信息,因为最后我们要进行格式化的存储,对于第一个图我们可以进行结构化行模式存储,可以做到每天的变化展示,但是二和三我们要采用列模式的存储,作为一种统计数据进行查询。因为两种方式的解析方式不同,一图中的表头字段在数据库中是作为字段存在的,所以我们不需要关心,二和三需要获取表格的表头进行存储,统计的事件也是我们存储的数据。再有就是我们不仅要得到基金的基本信息,还要获取到沪深300的相关信息,以后方便在做筛选时作为一个强度指标进行基准判断,所以沪深300的数据也需要进行抓取,这一部分的操作难度不大,主要是在于分析获取的数据方式以及后续进行存储思路。
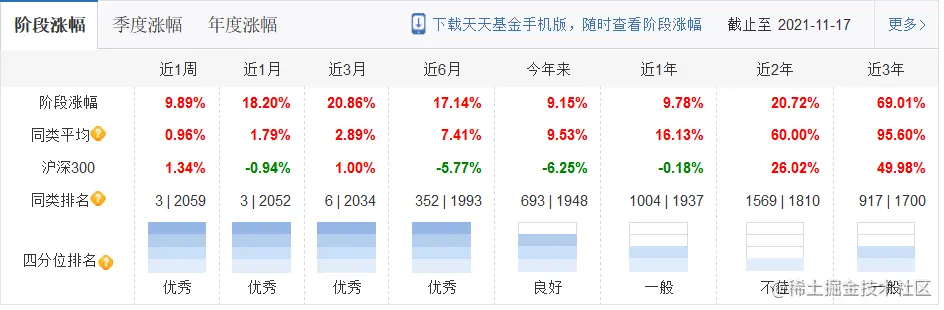
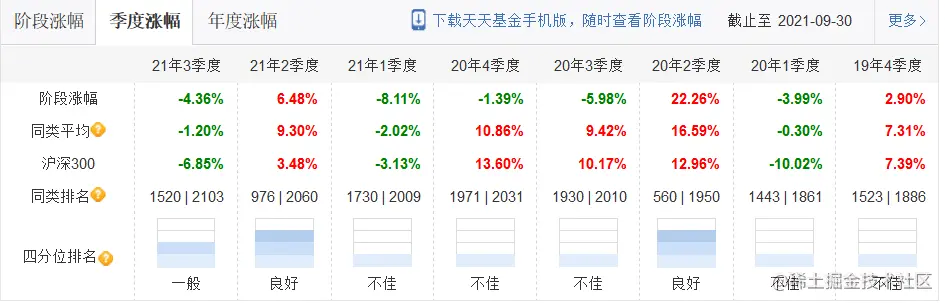
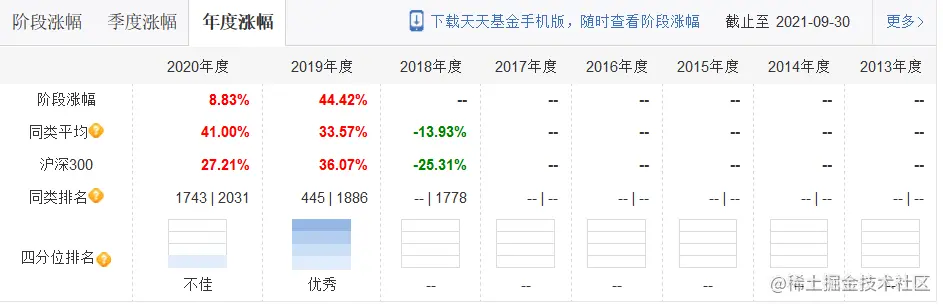
我这里是直接获取页面所有的table 元素,然后进行循环输出结果,然后获取需要抓取的数据在那个下标。
这里我就直接贴一下代码进行说明:
# 打印表格
def print_table(head, body):
tb = PrettyTable() # 生成表格对象
tb.field_names = head # 定义表头
tb.add_row(body)
print(tb)
# 查询季度 年度数据
def query_year_quarter(data_list, num):
stage_list = data_list.find_all("tr")[0].find_all("th")
head_list = []
for nd in stage_list:
val = nd.get_text().strip()
val = val.replace("季度", "").replace("年度", "").replace("年", "-")
if val:
# print(nd.get_text())
head_list.append(val)
body_list = []
stage_list = data_list.find_all("tr")[num].find_all("td")
for nd in stage_list:
val = nd.get_text()
if "阶段涨幅" in val or "沪深300" in val:
continue
body_list.append(val.replace("%", ""))
# 打印表格
print_table(head_list, body_list)
# 获取基金基本信息这里只是贴了部分代码,需要把获取净值部分的信息进行组合才能够运行
def query_fund_basic(code="005585", hsFlag=False):
# 阶段涨幅表头
stage_head_list = ["stage_week", "stage_month", "stage_month3", "stage_month6", "stage_year", "stage_year1","stage_year2", "stage_year3", ]
stage_list = body_list[11].find_all("tr")
# 获取第2个是基金情况 获取第4个是hs300情况
num = 1
if hsFlag:
num = 3
tmp_list = []
for nd in stage_list[num].find_all("td"):
val = nd.get_text()
if "阶段涨幅" in val or "沪深300" in val:
continue
tmp_list.append(val.replace("%", ""))
# 打印阶段幅度表格
print("\t------阶段涨跌------")
print_table(stage_head_list, tmp_list)
print("\t------季度涨跌------")
query_year_quarter(body_list[12], num)
print("\t------年度涨跌------")
query_year_quarter(body_list[13], num)3 最终结果展现
由于篇幅有限,本次代码就不在文内进行展示,后续我会把内容维护在github上进行提供。

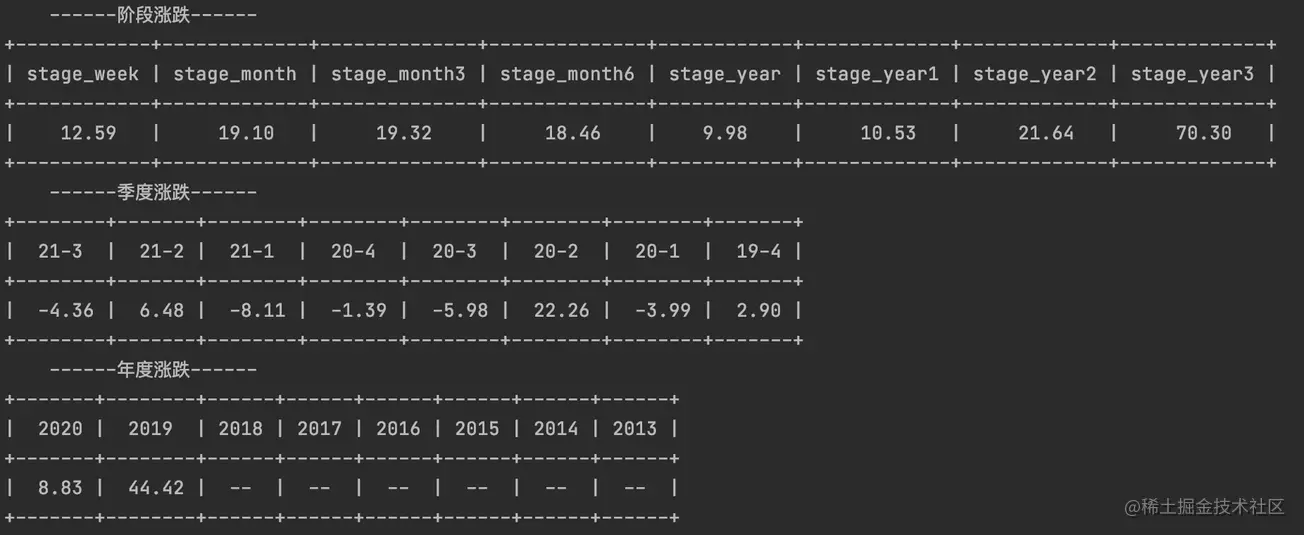
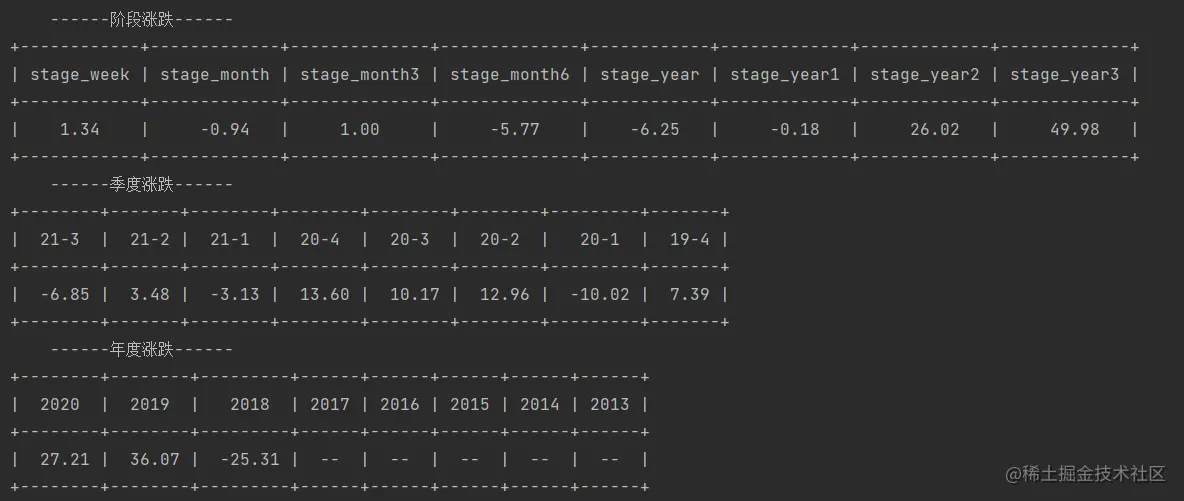
加载全部内容