AVX2指令集浮点数组求和
concyclics 人气:0一、AVX2指令集介绍
AVX2是SIMD(单指令多数据流)指令集,支持在一个指令周期内同时对256位内存进行操作。包含乘法,加法,位运算等功能。下附Intel官网使用文档。
我们本次要用到的指令有 __m256i _mm256_add_pd(__m256i a, __m256i b), __m256i _mm256_add_ps等,(p代表精度precision,s代表single,d代表double)
它们可以一次取256位的内存,并按32/64位一个浮点进行加法运算。下附官网描述。
Synopsis
__m256d _mm256_add_pd (__m256d a, __m256d b)
#include <immintrin.h>
Instruction: vaddpd ymm, ymm, ymm
CPUID Flags: AVX
Description
Add packed double-precision (64-bit) floating-point elements in a and b, and store the results in dst.
Operation
FOR j := 0 to 3 i := j*64 dst[i+63:i] := a[i+63:i] + b[i+63:i] ENDFOR dst[MAX:256] := 0
Performance
| Architecture | Latency | Throughput (CPI) |
|---|---|---|
| Icelake | 4 | 0.5 |
| Skylake | 4 | 0.5 |
| Broadwell | 3 | 1 |
| Haswell | 3 | 1 |
| Ivy Bridge | 3 | 1 |
二、代码实现
0. 数据生成
为了比较结果,我们生成从1到N的等差数列。这里利用模版兼容不同数据类型。由于AVX2指令集一次要操作多个数据,为了防止访存越界,我们将大小扩展到256的整数倍位比特,也就是32字节的整数倍。
uint64_t lowbit(uint64_t x)
{
return x & (-x);
}
uint64_t extTo2Power(uint64_t n, int i)//arraysize datasize
{
while(lowbit(n) < i)
n += lowbit(n);
return n;
}
template <typename T>
T* getArray(uint64_t size)
{
uint64_t ExSize = extTo2Power(size, 32/sizeof(T));
T* arr = new T[ExSize];
for (uint64_t i = 0; i < size; i++)
arr[i] = i+1;
for (uint64_t i = size; i < ExSize; i++)
arr[i] = 0;
return arr;
}
1. 普通数组求和
为了比较性能差异,我们先实现一份普通的数组求和。这里也使用模版。
template <typename T>
T simpleSum(T* arr, uint64_t size)
{
T sum = 0;
for (uint64_t i = 0; i < size; i++)
sum += arr[i];
return sum;
}
2. AVX2指令集求和:单精度浮点(float)
这里我们预开一个avx2的整形变量,每次从数组中取8个32位浮点,加到这个变量上,最后在对这8个32位浮点求和。
float avx2Sum(float* arr, uint64_t size)
{
float sum[8] = {0};
__m256 sum256 = _mm256_setzero_ps();
__m256 load256 = _mm256_setzero_ps();
for (uint64_t i = 0; i < size; i += 8)
{
load256 = _mm256_loadu_ps(&arr[i]);
sum256 = _mm256_add_ps(sum256, load256);
}
sum256 = _mm256_hadd_ps(sum256, sum256);
sum256 = _mm256_hadd_ps(sum256, sum256);
_mm256_storeu_ps(sum, sum256);
sum[0] += sum[4];
return sum[0];
}
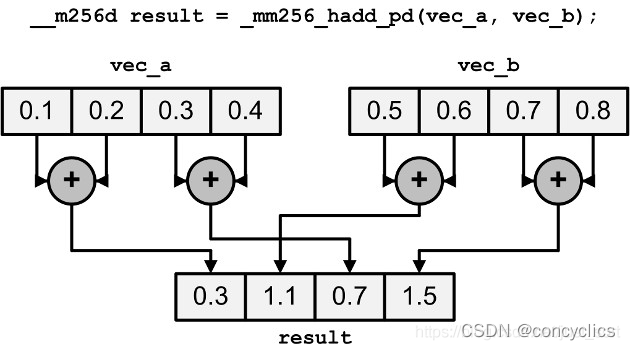
这里的hadd是横向加法,具体实现类似下图,可以帮我们实现数组内求和:
3. AVX2指令集求和:双精度浮点(double)
double avx2Sum(double* arr, uint64_t size)
{
double sum[4] = {0};
__m256d sum256 = _mm256_setzero_pd();
__m256d load256 = _mm256_setzero_pd();
for (uint64_t i = 0; i < size; i += 4)
{
load256 = _mm256_loadu_pd(&arr[i]);
sum256 = _mm256_add_pd(sum256, load256);
}
sum256 = _mm256_hadd_pd(sum256, sum256);
_mm256_storeu_pd(sum, sum256);
sum[0] += sum[2];
return sum[0];
}
三、性能测试
测试环境
| Device | Description |
|---|---|
| CPU | Intel Core i9-9880H 8-core 2.3GHz |
| Memory | DDR4-2400MHz Dual-Channel 32GB |
| complier | Apple Clang-1300.0.29.30 |
计时方式
利用chrono库获取系统时钟计算运行时间,精确到毫秒级
uint64_t getTime()
{
uint64_t timems = std::chrono::duration_cast<std::chrono::milliseconds>(std::chrono::system_clock::now().time_since_epoch()).count();
return timems;
}
测试内容
对1到1e9求和,答案应该为500000000500000000, 分别测试float和double。
uint64_t N = 1e9;
// compare the performance of normal add and avx2 add
uint64_t start, end;
// test float
cout << "compare float sum: " << endl;
float* arr3 = getArray<float>(N);
start = getTime();
float sum3 = simpleSum(arr3, N);
end = getTime();
cout << "float simpleSum time: " << end - start << endl;
cout << "float simpleSum sum: " << sum3 << endl;
start = getTime();
sum3 = avx2Sum(arr3, N);
end = getTime();
cout << "float avx2Sum time: " << end - start << endl;
cout << "float avx2Sum sum: " << sum3 << endl;
delete[] arr3;
cout << endl << endl;
// test double
cout << "compare double sum: " << endl;
double* arr4 = getArray<double>(N);
start = getTime();
double sum4 = simpleSum(arr4, N);
end = getTime();
cout << "double simpleSum time: " << end - start << endl;
cout << "double simpleSum sum: " << sum4 << endl;
start = getTime();
sum4 = avx2Sum(arr4, N);
end = getTime();
cout << "double avx2Sum time: " << end - start << endl;
cout << "double avx2Sum sum: " << sum4 << endl;
delete[] arr4;
cout << endl << endl;
进行性能测试
第一次测试
测试命令
g++ -mavx2 avx_big_integer.cpp ./a.out
测试结果
| 方法 | 耗时(ms) |
|---|---|
| AVX2加法 单精度 | 615 |
| 普通加法 单精度 | 2229 |
| AVX2加法 双精度 | 1237 |
| 普通加法 双精度 | 2426 |
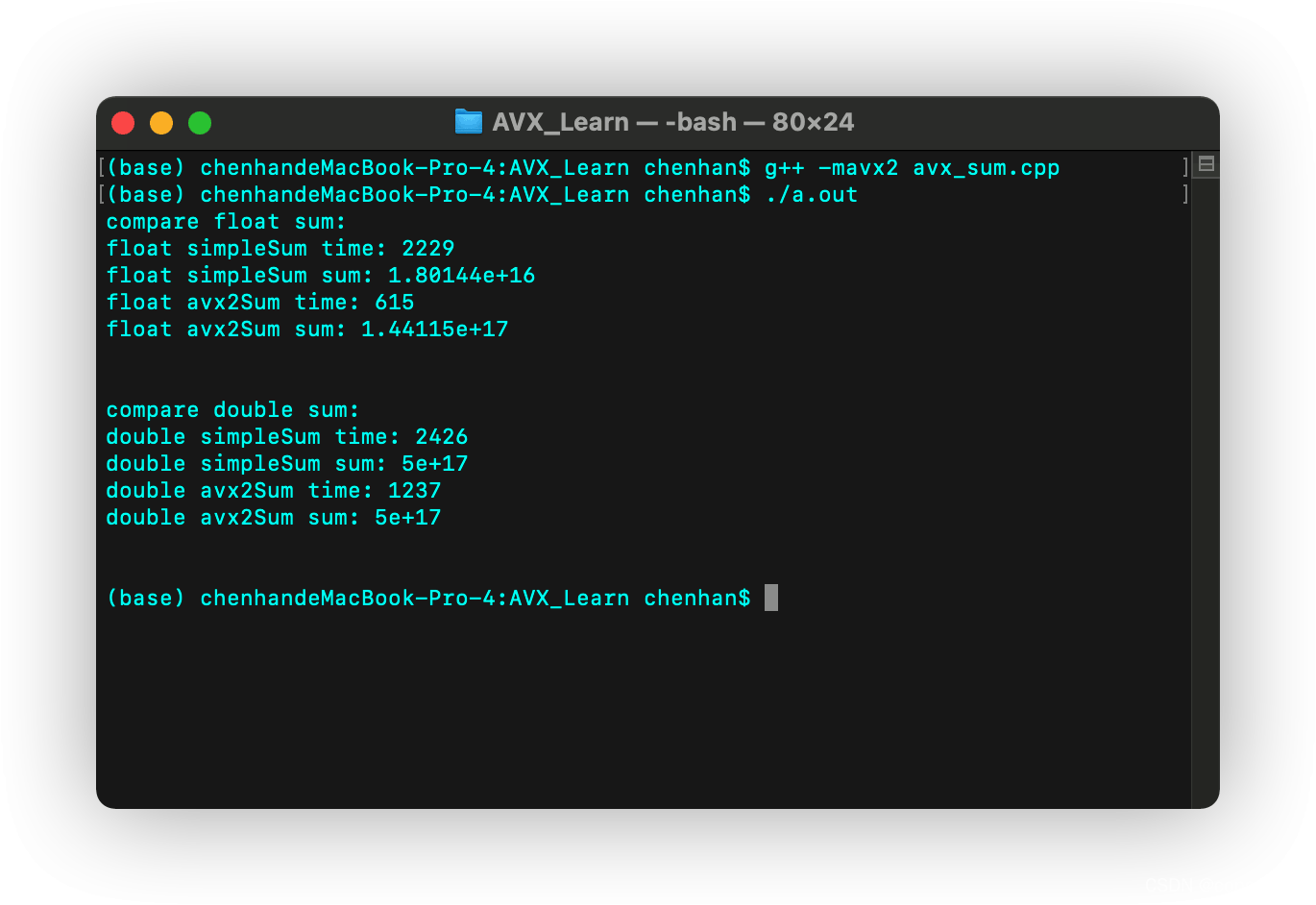
这里能看到单精度下已经出现了比较明显的误差,并且由于普通求和和avx2求和的加法顺序不一样,导致误差值也不一样。
第二次测试
测试命令
现在我们再开启O2编译优化试一试:
g++ -O2 -mavx2 avx_big_integer.cpp ./a.out
测试结果
| 方法 | 耗时(ms) |
|---|---|
| AVX2加法 32位 | 244 |
| 普通加法 32位 | 1012 |
| AVX2加法 64位 | 476 |
| 普通加法 64位 | 1292 |
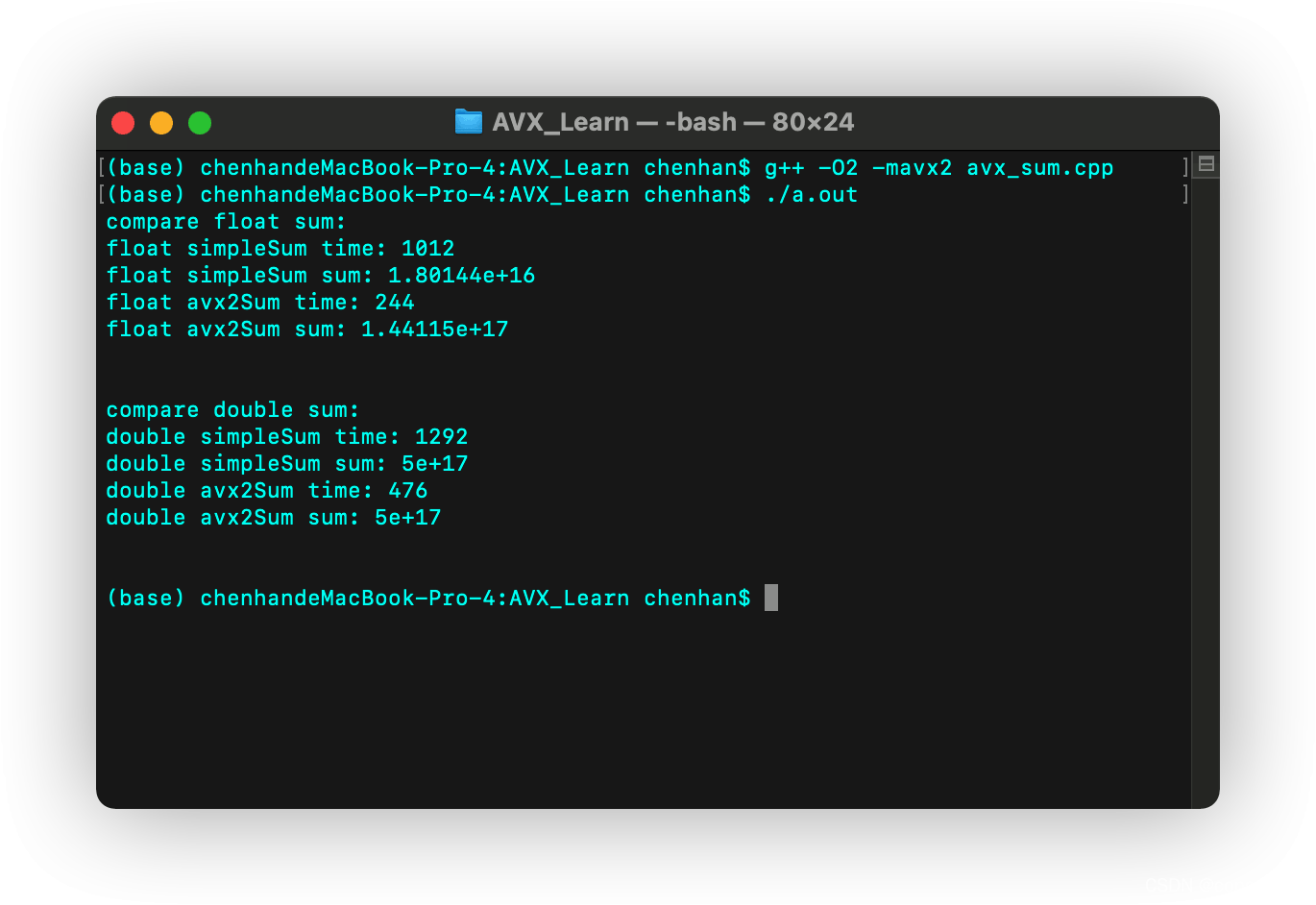
我们发现,比起上一次对整形的测试,浮点型在开启O2优化后反而是AVX2指令集加法得到了明显的提升。
四、总结
可见在进行浮点运算时,用avx2指令集做并行优化,能得到比起整形更好的效果。
个人猜测原因:
- 浮点型加法器比整形加法器复杂许多,流水线操作的效果不那么明显。
- 有可能CPU内的浮点加法器少于整形加法器,导致O2优化乱序执行时的优化效果不如整形理想。
- AVX2指令集可能针对浮点运算有专门的优化,使得浮点运算性能和整形运算更为接近。
加载全部内容