Kubernetes部署可视化地图
Nived Velayudhan 人气:0通过查看创建一个吊舱或一个部署时的 10 个步骤,可以更好地了解 Kubernetes。
当你在 Kubernetes 上使用容器时,你经常把应用程序组合在一个吊舱pod中。当你把一个容器或一个吊舱发布到生产环境中时,它被称为一个部署deployment。如果你每天甚至每周都在使用 Kubernetes,你可能已经这样做过几百次了,但你有没有想过,当你创建一个吊舱或一个部署时到底会发生什么?
我发现在高层次上了解事件链条是有帮助的。当然,你不一定要理解它。即使你不知道为什么,它仍然在工作。我不打算列出每一件发生的小事,但我的目标是涵盖所有重要的事情。
这里有一张 Kubernetes 不同组件如何互动的视觉地图。
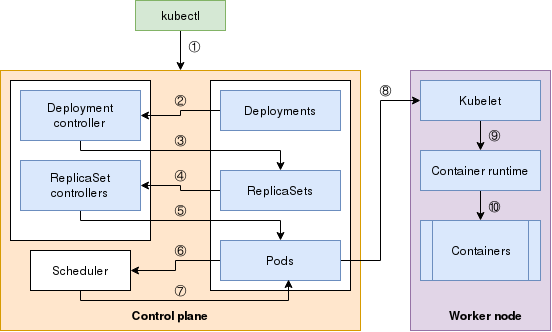
吊舱链条
你可能注意到,在上图中,我没有包括 etcd。API 服务器是唯一能够直接与 etcd 对话的组件,而且只有它能够对 etcd 进行修改。因此,你可以认为 etcd 在这张图中存在于(隐藏的)API 服务器后面。
另外,我在这里只讲到了两个主要的控制器(部署控制器Deployment controller和复制集控制器ReplicaSet controller)。其他的控制器的工作方式类似。
下面的步骤描述了当你执行 kubectl create 命令时会发生什么。
步骤 1
当你使用 kubectl create 命令时,一个 HTTP POST 请求被发送到 API 服务器,其中包含部署清单。API 服务器将其存储在 etcd 数据存储中,并返回一个响应给 kubectl。
步骤 2 和 3
API 服务器有一个观察机制,所有观察它的客户都会得到通知。客户端通过打开与 API 服务器的 HTTP 连接来观察变化,API 服务器会流式地发出通知。其中一个客户端是部署控制器。
部署控制器检测到一个部署Deployment对象,它用部署的当前规格创建一个复制集ReplicaSet。该资源被送回 API 服务器,并存储在 etcd 数据存储中。
步骤 4 和 5
与上一步类似,所有观察者都会收到关于 API 服务器中的变化的通知。这一次,复制集控制器会接收这一变化。
该控制器了解所需的副本数量和对象规格中定义的吊舱选择器,创建吊舱资源,并将这些信息送回 API 服务器,存储在 etcd 数据存储中。
步骤 6 和 7
Kubernetes 现在拥有运行吊舱所需的所有信息,但吊舱应该在哪个节点上运行?调度器Scheduler观察那些还没有分配到节点的吊舱,并开始对所有节点进行过滤和排序,以选择最佳节点来运行吊舱。
一旦节点被选中,该信息将被添加到吊舱规格中。而且它被送回 API 服务器并存储在 etcd 数据存储中。
步骤 8、9 和 10
到目前为止的所有步骤都发生在控制平面control plane本身。工作节点worker node还没有做任何工作。不过,吊舱的创建并不是由控制平面处理的。
相反,在所有节点上运行的 kubelet 服务观察 API 服务器中的吊舱规格,以确定它是否需要创建任何吊舱。
在调度器选择的节点上运行的 kubelet 服务获得吊舱规格,并指示工作节点上的容器运行时创建容器。这时就会下载一个容器镜像(如果它还不存在的话),容器就会实际开始运行。
理解 Kubernetes 的部署
对这个一般流程的理解可以帮助你理解 Kubernetes 中的许多事件。考虑一下 Kubernetes 中的守护进程集DaemonSet或状态集StatefulSet。除了使用不同的控制器外,吊舱的创建过程是一样的。
课后作业:如果部署被修改为有三个应用程序的副本,导致创建吊舱的事件链条会是什么样子?你可以参考图表或列出的步骤,但你肯定有你需要弄清楚的知识。知识就是力量,你现在有了了解 Kubernetes 的一个重要组成部分。
加载全部内容