Python+seaborn实现联合分布图的绘制
疯狂学习GIS 人气:0本文介绍基于Python中seaborn模块,实现联合分布图绘制的方法。
联合分布(Joint Distribution)图是一种查看两个或两个以上变量之间两两相互关系的可视化图,在数据分析操作中经常需要用到。一幅好看的联合分布图可以使得我们的数据分析更加具有可视性,让大家眼前一亮。
那么,本文就将用seaborn来实现联合分布图的绘制。seaborn是一个基于matplotlib的Python数据可视化模块,借助于其,我们可以通过较为简单的操作,绘制出各类动人的图片。
首先,引入需要的模块。
import pandas as pd import seaborn as sns
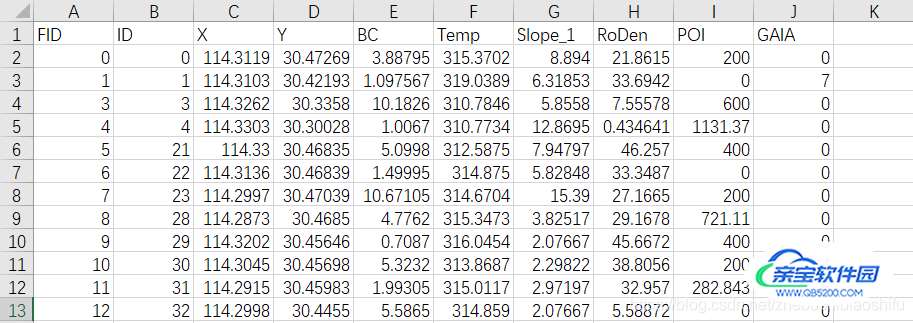
接下来,将存储有我们需要绘制联合分布图数据的文件导入。因为我是将数据存储于.csv文件,所以我这里用pd.read_csv来实现数据的导入。我的数据在.csv文件中长如下图的样子,其中共有107行,包括106行样本加1行列标题;以及10列。我们就看前几行即可:
导入数据的代码如下:
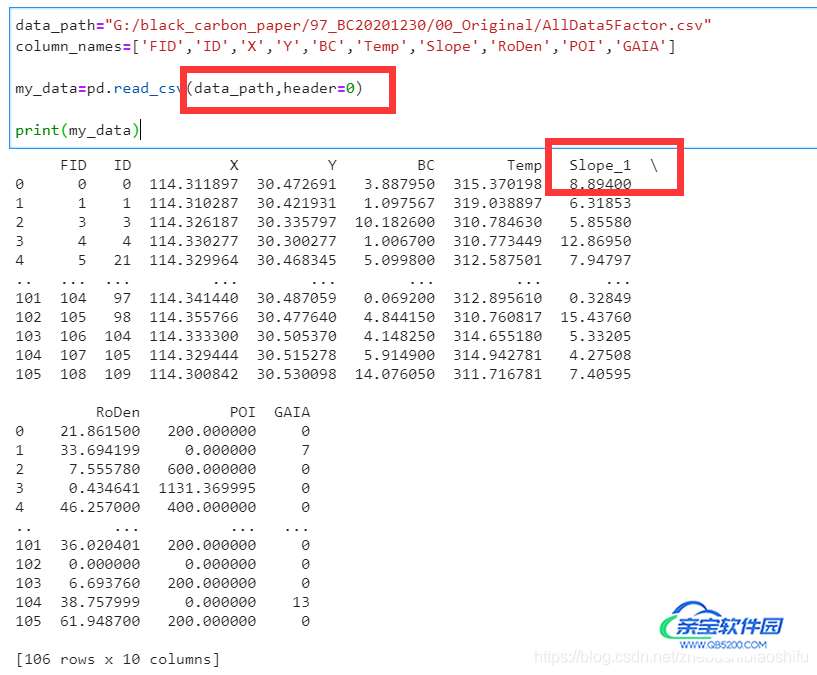
data_path="G:/black_carbon_paper/97_BC20201230/00_Original/AllData5Factor.csv" column_names=['FID','ID','X','Y','BC','Temp','Slope','RoDen','POI','GAIA'] my_data=pd.read_csv(data_path,names=column_names,header=0)
其中,data_path是.csv文件存储位置与文件名,column_names是导入的数据在Python中我希望其显示的名字(为什么原始数据本来就有列标题但还要再设置这个column_names,本文下方有介绍);header=0表示.csv文件中的0行(也就是我们一般而言的第一行)是列标题;如果大家的初始数据没有列标题,即其中的第一行就是数据自身,那么就需要设置header=None。
执行上述代码,我们将导入的数据打印,看看在Python中其长什么样子。
print(my_data)

可以看到,导入Python后数据的第7列,原本叫做Slope_1,但是设置我们自己命名的column_names后,其就将原本数据的列标题改为我们自己设定的标题Slope了。如果我们不设置column_names,导入的数据就是这个样子:
可以看到,我们不用column_names的话,数据导入Python后列名就是原始的Slope_1。
我们继续。其实用seaborn绘制联合分布图非常简单(这就是seaborn对matplotlib改进,让我们绘制复杂的图时候不需要太麻烦),仅仅只有一下两句代码:
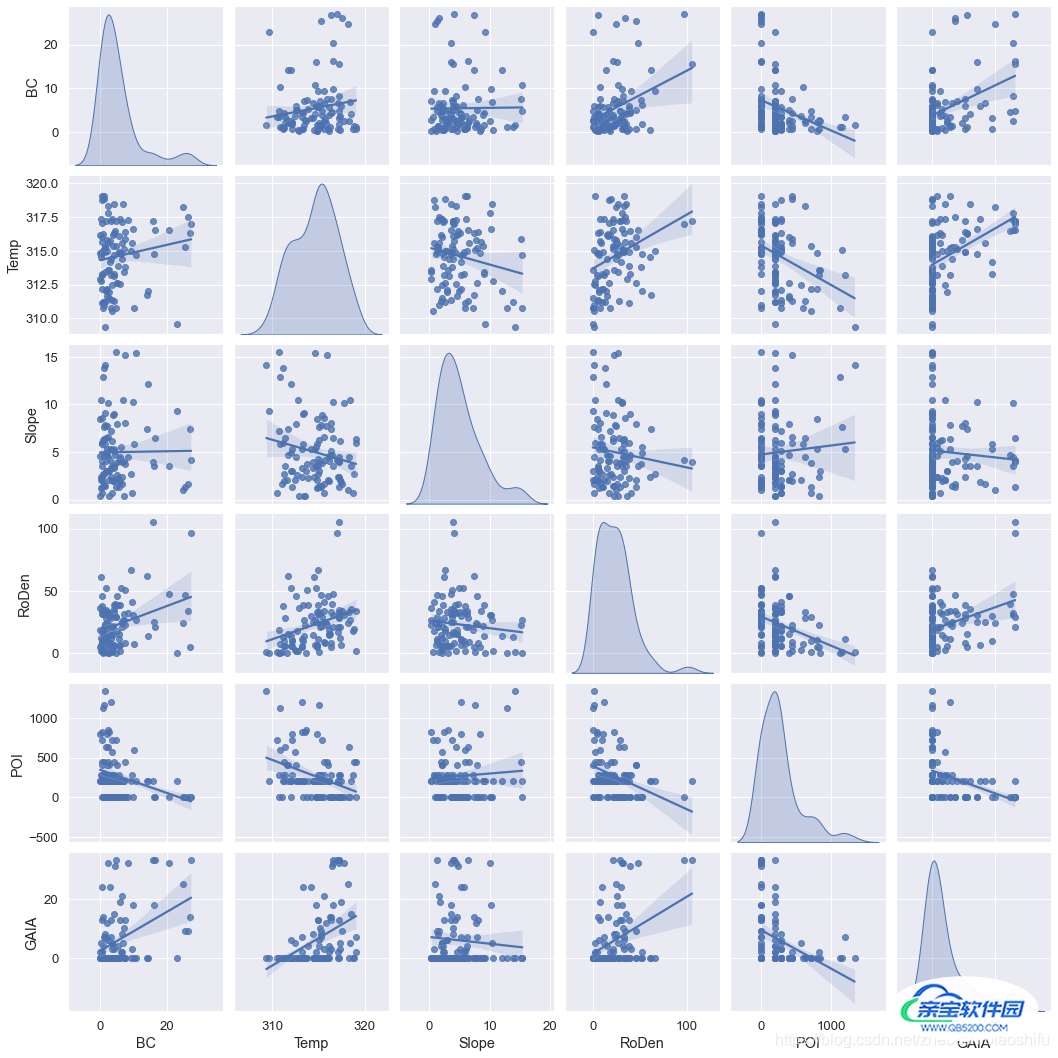
joint_columns=['BC','Temp','Slope','RoDen','POI','GAIA'] sns.pairplot(my_data[joint_columns],kind='reg',diag_kind='kde')
其中,第一句是定义我们想要参与绘制联合分布图的列,将需要绘图的列标题放入joint_column。可以看到,因为我的数据中,具有ID这种编号列,而肯定编号是不需要参与绘图的,那么我们就不将其放入joint_column即可。
第二句就是绘图。kind表示联合分布图中非对角线图的类型,可选'reg'与'scatter'、'kde'、'hist','reg'代表在图片中加入一条拟合直线,'scatter'就是不加入这条直线,'kde'是等高线的形式,'hist'就是类似于栅格地图的形式;diag_kind表示联合分布图中对角线图的类型,可选'hist'与'kde','hist'代表直方图,'kde'代表直方图曲线化。
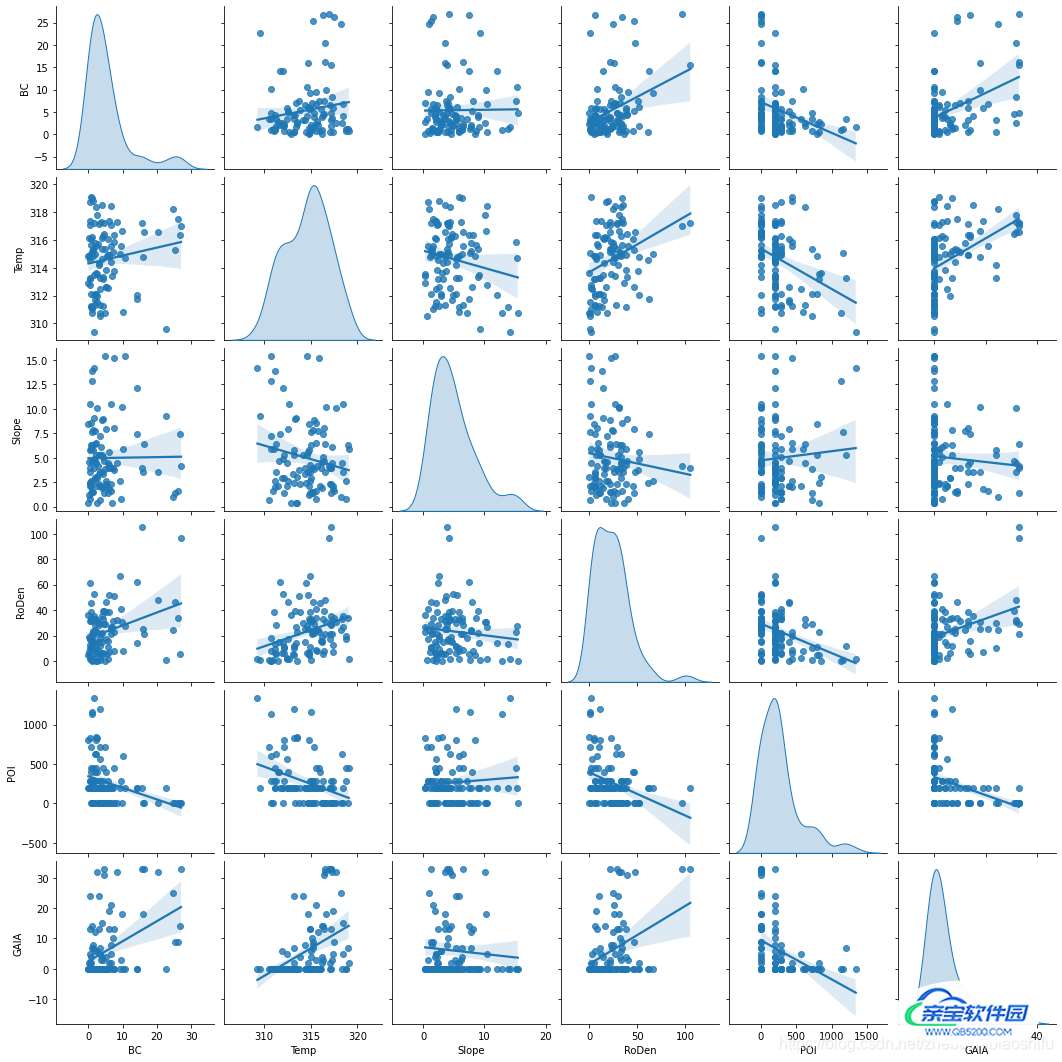
以kind和diag_kind分别选择'reg'和'kde'为例,绘图结果如下:
以kind和diag_kind分别选择'scatter'和'hist'为例,绘图结果如下:
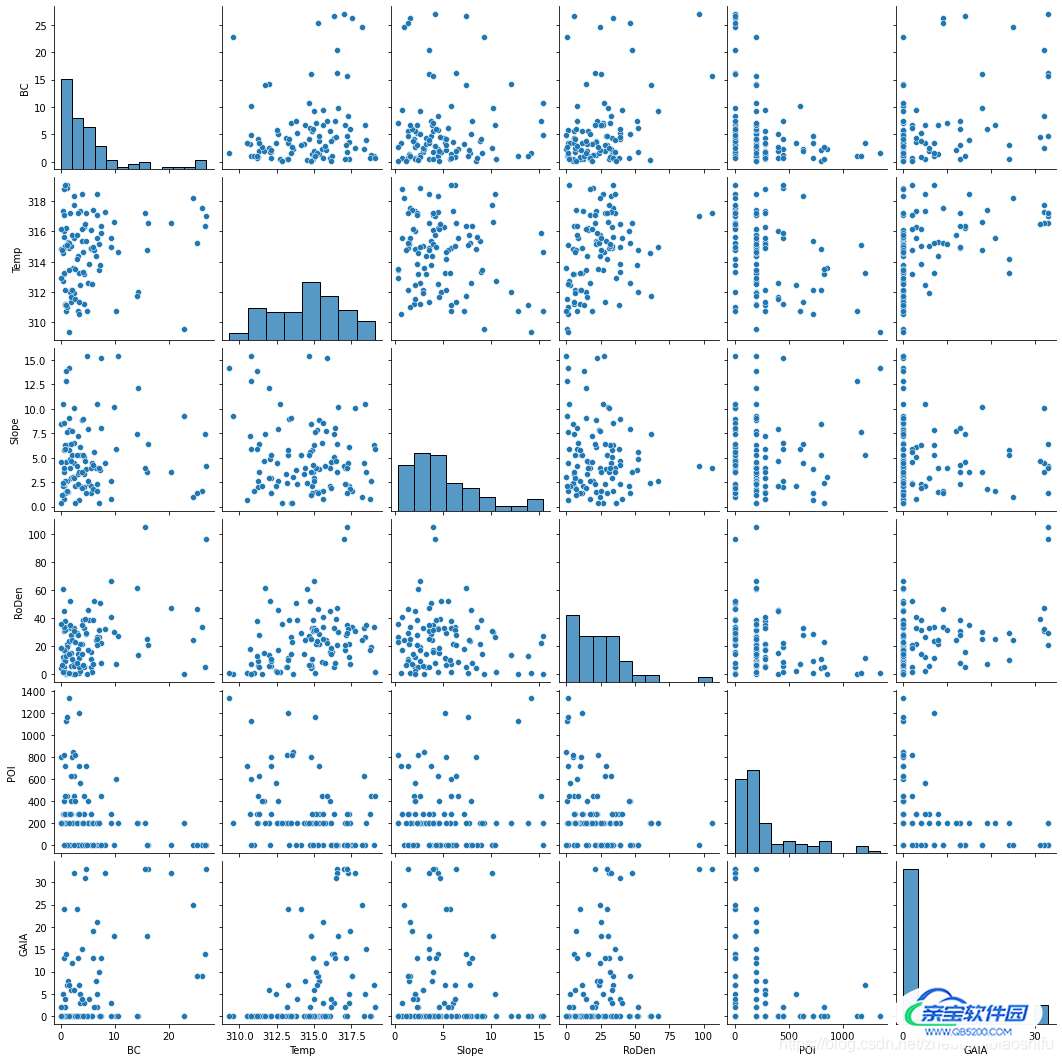
个人感觉第一幅图好看些~
不过,由于参与绘图的变量个数比较多,因此使得图中的字体有点看不清。可以加上一句代码在sns.pairplot这句代码的上面:
sns.set(font_scale=1.2)
其中,font_scale就是字体的大小,后面的数字越大,字体就越大。以font_scale=1.2为例,让我们看看效果:
这样子字体就大了~
加载全部内容