JavaScript实现获取图片文件真实格式的示例代码
jimojianghu 人气:0前面博文有提到,当前主流浏览器能支持的图片格式,是七种:jpg、png、gif、bmp、ico、webp、svg,其中,前六种都是位图,svg则是唯一的矢量图。
每种格式的图片,都有自己特有的优缺点以及数据结构,本篇博文的目的就是基于不同格式的图像二进制数据,获取到图片的真实格式。
常见方式判断图片格式
当我们进行前端开发,需要处理图片上传功能,针对图片格式做判断时,常规的方法都是使用文件后缀名来判断,如下代码所示:
input.addEventListener('change', (e) => {
const file = e.target.files[0]
const format = file.name.substring(file.name.lastIndexOf('.') + 1).toLowerCase()
}, false)以上代码,监听上传控件的事件,得到要上传的文件信息,获取文件名称,然后通过获取文件名称截取文件后缀名,以后缀名作为图片文件的格式。
这段代码,大部分人都比较熟悉,也有很多场景下是这样来判断图片格式的,但如果我们强行修改了文件的后缀名,则此方法就失效了。
我们知道gif格式图片的位深度是8,如果我们强制把位深度为32的png格式的图片后缀名改成gif,这个图片文件依然可以正常使用:
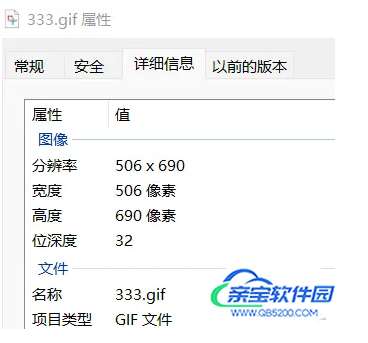
上图所示,就是将png格式文件后缀名改成了gif,图片系统信息显示格式为gif,但是位深度还是32,图像本质上还是png格式的。
这个时候,单纯的通过后缀名来判断图片的格式,就不再准确了,我们需要另外的方式来获取图片文件的真实格式。而这种方式就需要使用到前端二进制相关的知识,见前文介绍深入理解前端字节二进制知识以及相关API。
修改后缀名的方式
- 几种位图格式之间,是可以相互修改后缀名,图片仍能正常使用
- gif动图后缀名改成其他位图格式,则动效会失效,变成静态图
- 位图格式的后缀名如果改成矢量图svg,则图片失效,将无法使用
- svg图片文件后缀名改成位图格式,图片也将无法使用
图像数据简单说明
不同格式的图像所存储的数据是不一样的,都有自己特殊的数据结构。
依据各个格式图像不同的数据结构,我们通过类型数组中的图像数据,就能判断出图片的真实格式。
- 如jpg格式,它的图像数据结构中,最前面2个字节是一个固定取值
0xFFD8,第三个字节一般也是固定0xFF。 - 如png格式,它的图像数据结构中,最前面8个字节就是PNG文件署名域,可以很好的标识出当前图像的格式就是PNG。
- 如bmp格式,它的图像数据结构中,最前面14个字节存储的是文件头信息,而最前面2个字节存储的就是文件类型:
BM。 - 如webp格式,需要从最前面移动8个字节以后,取接下来的4个字节的信息,代表文件类型:
WEBP
针对不同位图的的数据判断,可以使用下面表格列出的方式:
| 格式 | 标识的字节数 | 对应的十进制值 | 偏移量 |
|---|---|---|---|
| jpg | 3 | 255 216 255 | 0 |
| png | 8 | 137 80 78 71 13 10 26 10 | 0 |
| gif | 3 | 71, 73, 70 | 0 |
| webp | 4 | 87, 69, 66, 80 | 8 |
| ico | 4 | 0, 0, 1, 0 | 0 |
| bmp | 2 | 66 77 | 0 |
其中,偏移量为0,表示取最前面几个字节的数据;webp的偏移量为8,表示从最前面移动8个字节后,再取4个字节的标识符。
上面的表格,已经列出了当前浏览器支持的位图图像,字节判断标识,通过读取相应的数据做对比就得到了真实的格式。
以上几种格式中,bmp、gif、webp取到的数据,都能对应各自特有的署名标识,前面有提到 BM 和 WEBP,gif格式的则是 GIF。可以运用字符编码方面的知识,如使用 String.fromCharCode 方法对数值进行转换,具体的前端字符编码知识见前文前端开发中需要搞懂的字符编码
// bmp String.fromCharCode(66) // B String.fromCharCode(77) // M // gif String.fromCharCode(71) // G String.fromCharCode(73) // I String.fromCharCode(70) // F // webp String.fromCharCode(87) // W String.fromCharCode(69) // E String.fromCharCode(66) // B String.fromCharCode(80) // P
gif格式的署名标识是和版本号一起处理的,一般最前面6个字节标识: 'G'、'I'、'F'、'8'、'7(9)'、'a'。第5个字节可取值7或者9,代表两个不同的版本,即1987年的版本和1989年的版本。
JS读取图片真实格式
当我们了解了前端二进制相关的知识后,就应该知道图片文件也是能通过WebAPI对象,读取到对应的数据:
const reader = new FileReader()
reader.onload = () => {
const imgArrayBuffer = reader.result
const imgUint8Array = new Uint8Array(imgArrayBuffer)
}
reader.readAsArrayBuffer(file)
以上代码,就是通过 FileReader 对象读取文件的数据,这里是作为 ArrayBuffer 来读取的,然后就可以转换成类型数组进行处理了。
读取到图片文件的 Uint8Array 类型数组数据后,根据上文表格中提到的格式字节数据标识,我们以jpg、bmp和webp为例:
imgUint8Array[0] === 66 && imgUint8Array[1] === 77 // bmp 格式 imgUint8Array[0] === 255 && imgUint8Array[1] === 216 && imgUint8Array[3] === 255 // jpg 格式 imgUint8Array[8] === 87 && imgUint8Array[9] === 69 && imgUint8Array[10] === 66 && imgUint8Array[10] === 80 // webp 格式
到此,就可以使用这种方式来读取到图片的真实格式,部分判断代码如下:
// 各格式对应图像数据的标识数值
const IMAGEFORMATS = [
{ ext: 'png', data: [137, 80, 78, 71, 13, 10, 26, 10] },
{ ext: 'jpg', data: [255, 216, 255] },
{ ext: 'gif', data: [71, 73, 70] },
{ ext: 'ico', data: [0, 0, 1, 0] },
{ ext: 'bmp', data: [66, 77] },
{ ext: 'webp', data: [87, 69, 66, 80], offset: 8 }
]
// 循环判断文件是否符合某个格式对应的标识数值
for (let i = 0; i < IMAGEFORMATS.length; i++) {
const { data, offset, ext } = IMAGEFORMATS[i]
if (isEqualFormatPrefix(imgUint8Array, data, offset)) {
return ext
}
}不过以上的方式主要是针对位图,如果是svg的图片,则会稍微复杂一些,需要另行处理。
svg格式的判断
svg格式图片是矢量图,对应的数据一般使用 xml 标记语言进行描述,所以我们读取到图像数据后,需要对应的标识署名是 <svg,如果对应的图像数据中拥有该标识,则大致可以判定为svg格式的图片。
<svg标识有4个符号和字母,对应的数值:60, 115, 118, 103,接下来我就需要判断图像文件是否有同样的数据了。
imgUint8Array[0] === 60 && imgUint8Array[1] === 115 && imgUint8Array[3] === 118 && imgUint8Array[3] === 103 // svg 格式
以上代码就是简单的判断svg格式了。
但是,我们一般的svg图片,图像数据最开始是包含有xml标记语言的 <?xm 标签,这个时候我们根据格式再判断:
if (isEqualFormatPrefix(fileUint8Array, [60, 63, 120, 109], offset)) { // 判断是否以 <?xm 开头
if (isHasSignCodes(fileUint8Array, [60, 115, 118, 103])) { // 判断是否包含 <svg 标签
return'svg'
}
}
注意:以上针对svg格式矢量图的这种判断方式,是以 xml 标记语言的标签符号进行判断的,只能处理通过更改后缀名的方式伪造的图片文件。当我们伪造一个假的文件,包含有 <svg 标签标识时,则可以逃避这种判断。
总结
浏览器支持的图片格式中,除了svg以外,其他几种位图格式,都可以较好的通过读取图像二进制数据的方式判断出图片文件的真实格式,能够防止文件伪造绕开判断,造成不必要的异常等问题。
加载全部内容