深度解读Python如何实现dbscan算法
梦想橡皮擦 人气:0DBScan 算法解释说明
DBScan 是密度基于空间聚类,它是一种基于密度的聚类算法,其与其他聚类算法(如K-Means)不同的是,它不需要事先知道簇的数量。
DBScan 算法通过构建基于密度的图模型,对数据进行聚类。
该算法使用两个参数:半径 eps 和最小样本数 minPts 。
它通过遍历每一个数据点,并将它们分为核心对象,边界对象和噪声。
如果一个数据点是核心对象,则它周围的数据点也属于该簇。
DBScan 算法通过找到密度高的区域,并将其作为簇,最终得到聚类结果。
DBScan 算法的应用场景
对非球形簇进行聚类:DBScan 算法可以识别出非球形的簇,因此适用于识别非球形的结构。
对不平衡数据进行聚类:DBScan 算法可以适用于对不平衡的数据进行聚类,因为它不像 K-Means 那样需要事先知道簇的数量。
异常值检测:DBScan 算法可以识别异常值,因为它可以识别出非核心对象的点,并将它们作为异常值。
处理高维数据:DBScan 算法可以很好地处理高维数据,因为它不基于欧几里得距离,而是基于密度关系。
对动态数据进行聚类:DBScan 算法可以适用于对动态数据进行聚类,因为它可以很好地处理动态数据的变化。
Python 实现的 DBScan 算法
from sklearn.cluster import DBSCAN
import numpy as np
# 创建样本数据
X = np.array([[1, 2], [2, 2], [2, 3], [8, 7], [8, 8], [25, 80]])
# 创建并训练模型
db = DBSCAN(eps=3, min_samples=2).fit(X)
# 获取聚类标签
labels = db.labels_
# 打印聚类结果
print("Labels:", labels)
在代码中,首先创建了样本数据,然后创建了一个 DBSCAN 模型,并通过设置参数 eps 和 min_samples 训练该模型。最后,我们通过调用 model.labels_ 属性获取了聚类标签,并打印出了聚类结果。
eps 参数表示数据点之间的最大距离,min_samples 参数表示确定一个簇所需的最小数据点数量。
Python 实现 dbscan 高级算法
import numpy as np
def euclidean_distance(x, y):
return np.sqrt(np.sum((x - y)**2))
def dbscan(X, eps, min_samples):
m = X.shape[0]
labels = [0] * m
C = 0
for i in range(m):
if labels[i] != 0:
continue
neighbors = []
for j in range(m):
if euclidean_distance(X[i], X[j]) < eps:
neighbors.append(j)
if len(neighbors) < min_samples:
labels[i] = -1
else:
C += 1
labels[i] = C
for j in neighbors:
labels[j] = C
return labels
X = np.array([[1,2],[2,2],[2,3],[8,7],[8,8],[25,80]])
labels = dbscan(X, 3, 2)
print(labels)
上面的代码中, X 是输入的数据矩阵, eps 是半径(或阈值), min_samples 是半径内的最小样本数。
在 dbscan() 函数内,首先对每一个样本点,找出它的领域内的样本点(即与其距离小于阈值的样本点),并判断是否满足要求的最小样本数,如果满足,将其作为核心点,并将其他在领域内的样本点聚为同一类,如果不满足,说明该点是噪声点,不聚为任何一类。
最后返回每一个样本点所属的类别标签。
再演示一种 python 实现 dbscan 算法的代码
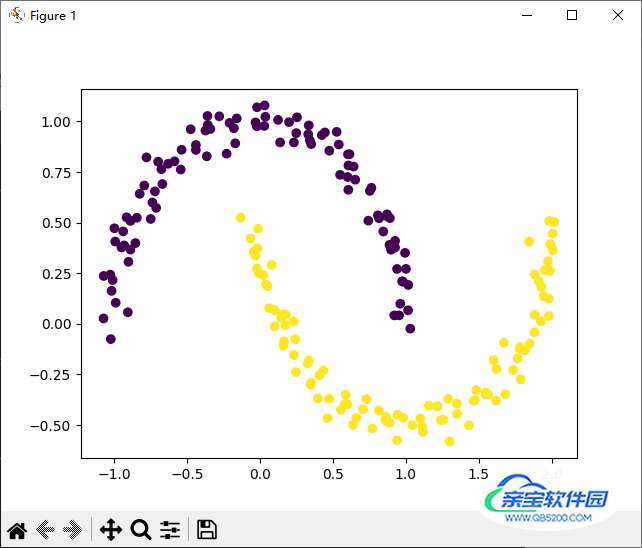
import numpy as np import matplotlib.pyplot as plt from sklearn.datasets import make_moons from sklearn.cluster import DBSCAN # 创建数据集 X, y = make_moons(n_samples=200, noise=0.05, random_state=0) # 初始化 DBScan 模型 dbscan = DBSCAN(eps=0.3, min_samples=5) # 训练模型 y_pred = dbscan.fit_predict(X) # 可视化结果 plt.scatter(X[:, 0], X[:, 1], c=y_pred) plt.show()
上述代码使用了 scikit-learn 库中的 DBSCAN 模型,在创建数据集时使用了 make_moons() 函数,可以创建一个月牙形数据集。
接着,初始化了一个 DBScan 模型,其中 eps 参数表示邻域半径, min_samples 参数表示在邻域内至少需要有多少个样本。接下来使用 fit_predict() 方法训练模型并预测结果。最后使用 scatter() 函数可视化结果。
运行代码得到如下结果。
加载全部内容