React之虚拟DOM的实现原理
huangpb0624 人气:0React虚拟DOM机制
- 虚拟DOM本质上是JavaScript对象,是对真实DOM的抽象
- 状态变更时,记录新树和旧树的差异
- 最后把差异更新到真正的dom中
React引入了虚拟DOM(Virtual DOM)的机制:在浏览器端用Javascript实现了一套DOM API。
基于React进行开发时所有的DOM构造都是通过虚拟DOM进行,每当数据变化时,React都会重新构建整个DOM树,然后React将当前整个DOM树和上一次的DOM树进行对比,得到DOM结构的区别,然后仅仅将需要变化的部分进行实际的浏览器DOM更新。
而且React能够批量处理虚拟DOM的刷新,在一个事件循环(Event Loop)内的两次数据变化会被合并,例如你连续的先将节点内容从A变成B,然后又从B变成A,React会认为UI不发生任何变化。
尽管每一次都需要构造完整的虚拟DOM树,但是因为虚拟DOM是内存数据,性能是极高的,而对实际DOM进行操作的仅仅是Diff部分,因而能达到提高性能的目的。这样,在保证性能的同时,开发者将不再需要关注某个数据的变化如何更新到一个或多个具体的DOM元素,而只需要关心在任意一个数据状态下,整个界面是如何Render的。
总之一句话:根据 React 的设计,所有的 DOM 变动,都先在虚拟 DOM 上发生,然后再将实际发生变动的部分,反映在真实 DOM上
React diff 算法
diff 算法作为Virtual DOM的加速器,其算法的改进优化是React整个界面渲染的基础和性能的保障,同时也是React源码中最神秘的,最不可思议的部分。
1. 传统 diff 算法
计算一棵树形结构转换为另一棵树形结构需要最少步骤,如果使用传统的diff算法通过循环递归遍历节点进行对比,其复杂度要达到O(n^3),其中n是节点总数,效率十分低下,假设我们要展示1000个节点,那么我们就要依次执行上十亿次的比较。
下面附上一则简单的传统diff算法:
let result = [];
// 比较叶子节点
const diffLeafs = function (beforeLeaf, afterLeaf) {
// 获取较大节点树的长度
let count = Math.max(beforeLeaf.children.length, afterLeaf.children.length);
// 循环遍历
for (let i = 0; i < count; i++) {
const beforeTag = beforeLeaf.children[i];
const afterTag = afterLeaf.children[i];
// 添加 afterTag 节点
if (beforeTag === undefined) {
result.push({ type: "add", element: afterTag });
// 删除 beforeTag 节点
} else if (afterTag === undefined) {
result.push({ type: "remove", element: beforeTag });
// 节点名改变时,删除 beforeTag 节点,添加 afterTag 节点
} else if (beforeTag.tagName !== afterTag.tagName) {
result.push({ type: "remove", element: beforeTag });
result.push({ type: "add", element: afterTag });
// 节点不变而内容改变时,改变节点
} else if (beforeTag.innerHTML !== afterTag.innerHTML) {
if (beforeTag.children.length === 0) {
result.push({
type: "changed",
beforeElement: beforeTag,
afterElement: afterTag,
html: afterTag.innerHTML
});
} else {
// 递归比较
diffLeafs(beforeTag, afterTag);
}
}
}
return result;
}2. react diff 算法
1. diff 策略
下面介绍一下react diff算法的3个策略
- Web UI 中DOM节点跨层级的移动操作特别少,可以忽略不计
- 拥有相同类的两个组件将会生成相似的树形结构,拥有不同类的两个组件将会生成不同的树形结构。
- 对于同一层级的一组子节点,它们可以通过唯一id进行区分。
对于以上三个策略,react 分别对 tree diff, component diff, element diff 进行算法优化。
2. tree diff
基于策略一,WebUI中DOM节点跨层级的移动操作少的可以忽略不计,React对Virtual DOM树进行层级控制,只会对相同层级的DOM节点进行比较,即同一个父元素下的所有子节点,当发现节点已经不存在了,则会删除掉该节点下所有的子节点,不会再进行比较。这样只需要对DOM树进行一次遍历,就可以完成整个树的比较。复杂度变为O(n);
疑问:当我们的DOM节点进行跨层级操作时,diff 会有怎么样的表现呢?
如下图所示,A节点及其子节点被整个移动到D节点下面去,由于React只会简单的考虑同级节点的位置变换,而对于不同层级的节点,只有创建和删除操作,所以当根节点发现A节点消失了,就会删除A节点及其子节点,当D发现多了一个子节点A,就会创建新的A作为其子节点。
此时,diff的执行情况是:
createA-->createB-->createC-->deleteA
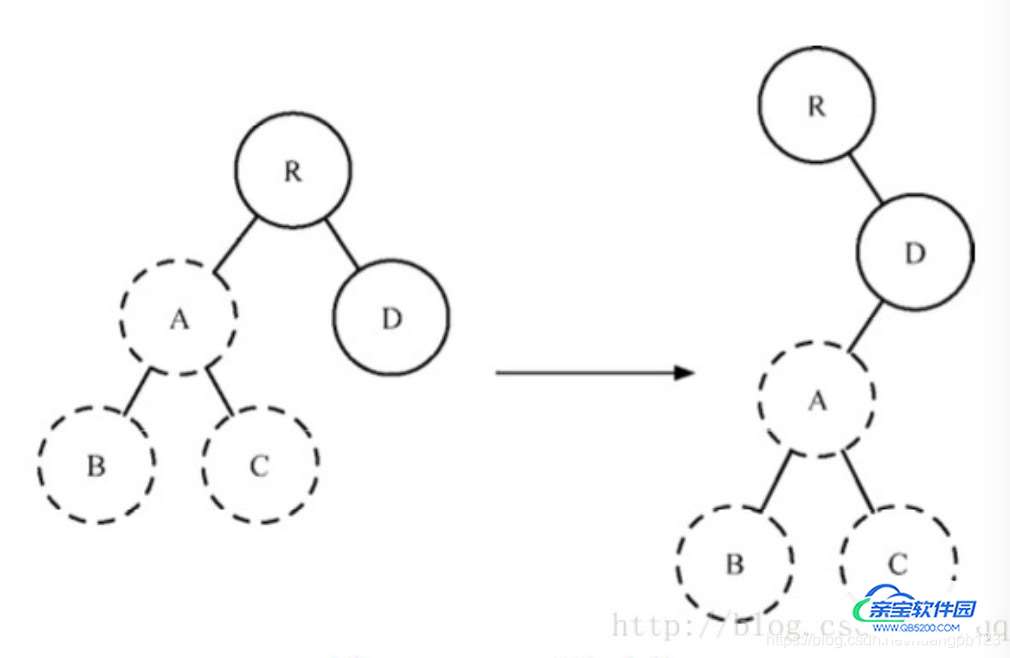
由此可以发现,当出现节点跨层级移动时,并不会出现想象中的移动操作,而是会进行删除,重新创建的动作,这是一种很影响React性能的操作。因此官方也不建议进行DOM节点跨层级的操作。
3. component diff
- React是基于组件构建应用的,对于组件间的比较所采用的策略也是非常简洁和高效的。
- 如果是同一个类型的组件,则按照原策略进行Virtual DOM比较。
- 如果不是同一类型的组件,则将其判断为dirty component,从而替换整个组价下的所有子节点。
- 如果是同一个类型的组件,有可能经过一轮Virtual DOM比较下来,并没有发生变化。如果我们能够提前确切知道这一点,那么就可以省下大量的diff运算时间。因此,React允许用户通过shouldComponentUpdate()来判断该组件是否需要进行diff算法分析。
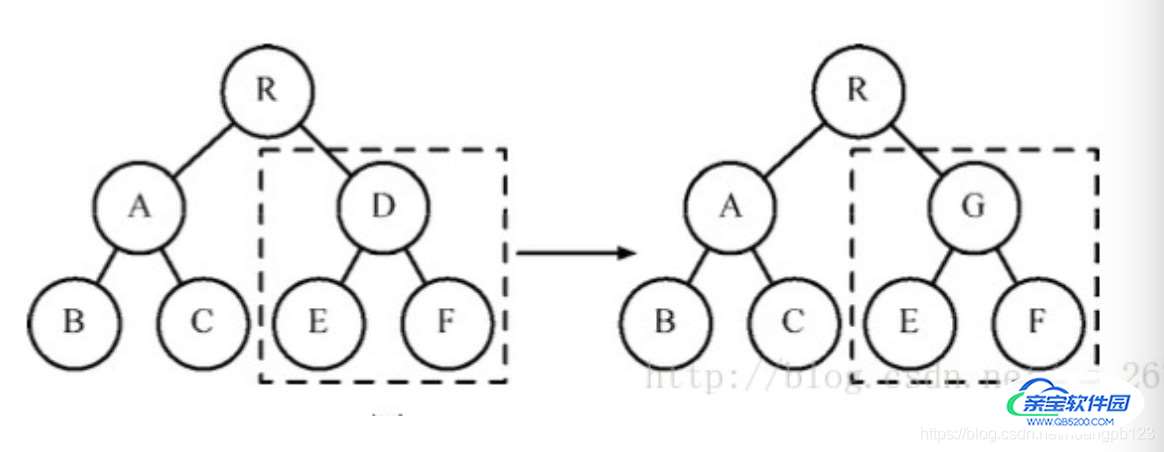
如下图所示,当组件D变为组件G时,即使这两个组件结构相似,一旦React判断D和G是不用类型的组件,就不会比较两者的结构,而是直接删除组件D,重新创建组件G及其子节点。
虽然当两个组件是不同类型但结构相似时,进行diff算法分析会影响性能,但是毕竟不同类型的组件存在相似DOM树的情况在实际开发过程中很少出现,因此这种极端因素很难在实际开发过程中造成重大影响。
4. element diff
当节点属于同一层级时,diff提供了3种节点操作,分别为INSERT_MARKUP(插入),MOVE_EXISTING(移动),REMOVE_NODE(删除)。
INSERT_MARKUP:新的组件类型不在旧集合中,即全新的节点,需要对新节点进行插入操作。MOVE_EXISTING:旧集合中有新组件类型,且element是可更新的类型,这时候就需要做移动操作,可以复用以前的DOM节点。REMOVE_NODE:旧组件类型,在新集合里也有,但对应的element不同则不能直接复用和更新,需要执行删除操作,或者旧组件不在新集合里的,也需要执行删除操作。
总结
通过diff策略,将算法从O(n^3)简化为O(n)。
分层求异,对tree diff进行优化。
分组件求异,相同类生成相似树形结构、不同类生成不同树形结构,对component diff进行优化。
设置key,对element diff进行优化。
尽量保持稳定的DOM结构、避免将最后一个节点移动到列表首部、避免节点数量过大或更新过于频繁。
最后
以上为个人经验,希望能给大家一个参考,也希望大家多多支持。
加载全部内容