Spark网站日志过滤分析实例讲解
CarveStone 人气:0日志过滤
对于一个网站日志,首先要对它进行过滤,删除一些不必要的信息,我们通过scala语言来实现,清洗代码如下,代码要通过别的软件打包为jar包,此次实验所用需要用到的代码都被打好jar包,放到了/root/jar-files文件夹下:
package com.imooc.log
import com.imooc.log.SparkStatFormatJob.SetLogger
import com.imooc.log.util.AccessConvertUtil
import org.apache.spark.sql.{SaveMode, SparkSession}
/*
数据清洗部分
*/
object SparkStatCleanJob {
def main(args: Array[String]): Unit = {
SetLogger
val spark = SparkSession.builder()
.master("local[2]")
.appName("SparkStatCleanJob").getOrCreate()
val accessRDD = spark.sparkContext.textFile("/root/resources/access.log")
accessRDD.take(4).foreach(println)
val accessDF = spark.createDataFrame(accessRDD.map(x => AccessConvertUtil.parseLog(x)),AccessConvertUtil.struct)
accessDF.printSchema()
//-----------------数据清洗存储到目标地址------------------------
// coalesce(1)输出指定分区数的小文件
accessDF.coalesce(1).write.format("parquet").partitionBy("day").mode(SaveMode.Overwrite).save("/root/clean")//mode(SaveMode.Overwrite)覆盖已经存在的文件 存储为parquet格式,按day分区
//存储为parquet格式,按day分区
/**
* 调优点:
* 1) 控制文件输出的大小: coalesce
* 2) 分区字段的数据类型调整:spark.sql.sources.partitionColumnTypeInference.enabled
* 3) 批量插入数据库数据,提交使用batch操作
*/
spark.stop()
}
}
过滤好的数据将被存放在/root/clean文件夹中,这部分已被执行好,后面直接使用就可以,其中代码开始的SetLogger功能在自定义类com.imooc.log.SparkStatFormatJob中,它关闭了大部分log日志输出,这样可以使界面变得简洁,代码如下:
def SetLogger() = {
Logger.getLogger("org").setLevel(Level.OFF)
Logger.getLogger("com").setLevel(Level.OFF)
System.setProperty("spark.ui.showConsoleProgress", "false")
Logger.getRootLogger().setLevel(Level.OFF);
}
过滤中的AccessConvertUtil类内容如下所示:
object AccessConvertUtil {
//定义的输出字段
val struct = StructType( //过滤日志结构
Array(
StructField("url", StringType), //课程URL
StructField("cmsType", StringType), //课程类型:video / article
StructField("cmsId", LongType), //课程编号
StructField("traffic", LongType), //耗费流量
StructField("ip", StringType), //ip信息
StructField("city", StringType), //所在城市
StructField("time", StringType), //访问时间
StructField("day", StringType) //分区字段,天
)
)
/**
* 根据输入的每一行信息转换成输出的样式
* 日志样例:2017-05-11 14:09:14 http://www.imooc.com/video/4500 304 218.75.35.226
*/
def parseLog(log: String) = {
try {
val splits = log.split("\t")
val url = splits(1)
//http://www.imooc.com/video/4500
val traffic = splits(2).toLong
val ip = splits(3)
val domain = "http://www.imooc.com/"
//主域名
val cms = url.substring(url.indexOf(domain) + domain.length) //建立一个url的子字符串,它将从domain出现时的位置加domain的长度的位置开始计起
val cmsTypeId = cms.split("/")
var cmsType = ""
var cmsId = 0L
if (cmsTypeId.length > 1) {
cmsType = cmsTypeId(0)
cmsId = cmsTypeId(1).toLong
} //以"/"分隔开后,就相当于分开了课程格式和id,以http://www.imooc.com/video/4500为例,此时cmsType=video,cmsId=4500
val city = IpUtils.getCity(ip) //从ip表中可以知道ip对应哪个城市
val time = splits(0)
//2017-05-11 14:09:14
val day = time.split(" ")(0).replace("-", "") //day=20170511
//Row中的字段要和Struct中的字段对应
Row(url, cmsType, cmsId, traffic, ip, city, time, day)
} catch {
case e: Exception => Row(0)
}
}
def main(args: Array[String]): Unit = {
//示例程序:
val url = "http://www.imooc.com/video/4500"
val domain = "http://www.imooc.com/" //主域名
val index_0 = url.indexOf(domain)
val index_1 = index_0 + domain.length
val cms = url.substring(index_1)
val cmsTypeId = cms.split("/")
var cmsType = ""
var cmsId = 0L
if (cmsTypeId.length > 1) {
cmsType = cmsTypeId(0)
cmsId = cmsTypeId(1).toLong
}
println(cmsType + " " + cmsId)
val time = "2017-05-11 14:09:14"
val day = time.split(" ")(0).replace("-", "")
println(day)
}
}执行完毕后clean文件夹下内容如图1所示:
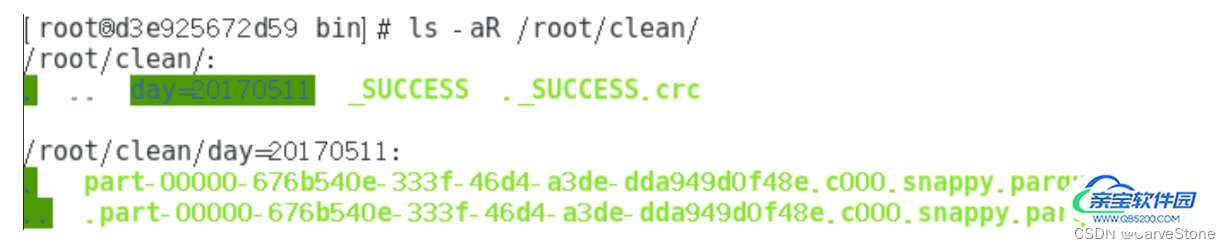
日志分析
现在我们已经拥有了过滤好的日志文件,可以开始编写分析代码,例如实现一个按地市统计主站最受欢迎的TopN课程
package com.imooc.log
import com.imooc.log.SparkStatFormatJob.SetLogger
import com.imooc.log.dao.StatDAO
import com.imooc.log.entity.{DayCityVideoAccessStat, DayVideoAccessStat, DayVideoTrafficsStat}
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.functions._
import org.apache.spark.sql.{DataFrame, SparkSession}
import scala.collection.mutable.ListBuffer
object TopNStatJob2 {
def main(args: Array[String]): Unit = {
SetLogger
val spark = SparkSession.builder()
.config("spark.sql.sources.partitionColumnTypeInference.enabled", "false") //分区字段的数据类型调整【禁用】
.master("local[2]")
.config("spark.sql.parquet.compression.codec","gzip") //修改parquet压缩格式
.appName("SparkStatCleanJob").getOrCreate()
//读取清洗过后的数据
val cleanDF = spark.read.format("parquet").load("/root/clean")
//执行业务前先清空当天表中的数据
val day = "20170511"
import spark.implicits._
val commonDF = cleanDF.filter($"day" === day && $"cmsType" === "video")
commonDF.cache()
StatDAO.delete(day)
cityAccessTopSata(spark, commonDF) //按地市统计主站最受欢迎的TopN课程功能
commonDF.unpersist(true) //RDD去持久化,优化内存空间
spark.stop()
}
/*
* 按地市统计主站最受欢迎的TopN课程
*/
def cityAccessTopSata(spark: SparkSession, commonDF: DataFrame): Unit = {
//------------------使用DataFrame API完成统计操作--------------------------------------------
import spark.implicits._
val cityAccessTopNDF = commonDF
.groupBy("day", "city", "cmsId").agg(count("cmsId").as("times")).orderBy($"times".desc) //聚合
cityAccessTopNDF.printSchema()
cityAccessTopNDF.show(false)
//-----------Window函数在Spark SQL中的使用--------------------
val cityTop3DF = cityAccessTopNDF.select( //Top3中涉及到的列
cityAccessTopNDF("day"),
cityAccessTopNDF("city"),
cityAccessTopNDF("cmsId"),
cityAccessTopNDF("times"),
row_number().over(Window.partitionBy(cityAccessTopNDF("city"))
.orderBy(cityAccessTopNDF("times").desc)).as("times_rank")
).filter("times_rank <= 3").orderBy($"city".desc, $"times_rank".asc) //以city为一个partition,聚合times为times_rank,过滤出前三,降序聚合city,升序聚合times_rank
cityTop3DF.show(false) //展示每个地市的Top3
//-------------------将统计结果写入数据库-------------------
try {
cityTop3DF.foreachPartition(partitionOfRecords => {
val list = new ListBuffer[DayCityVideoAccessStat]
partitionOfRecords.foreach(info => {
val day = info.getAs[String]("day")
val cmsId = info.getAs[Long]("cmsId")
val city = info.getAs[String]("city")
val times = info.getAs[Long]("times")
val timesRank = info.getAs[Int]("times_rank")
list.append(DayCityVideoAccessStat(day, cmsId, city, times, timesRank))
})
StatDAO.insertDayCityVideoAccessTopN(list)
})
} catch {
case e: Exception => e.printStackTrace()
}
}
其中保存统计时用到了StatDAO类的insertDayCityVideoAccessTopN()方法,这部分的说明如下:
def insertDayVideoTrafficsTopN(list: ListBuffer[DayVideoTrafficsStat]): Unit = {
var connection: Connection = null
var pstmt: PreparedStatement = null
try {
connection = MySQLUtils.getConnection() //JDBC连接MySQL
connection.setAutoCommit(false) //设置手动提交
//向day_video_traffics_topn_stat表中插入数据
val sql = "insert into day_video_traffics_topn_stat(day,cms_id,traffics) values(?,?,?)"
pstmt = connection.prepareStatement(sql)
for (ele <- list) {
pstmt.setString(1, ele.day)
pstmt.setLong(2, ele.cmsId)
pstmt.setLong(3, ele.traffics)
pstmt.addBatch() //优化点:批量插入数据库数据,提交使用batch操作
}
pstmt.executeBatch() //执行批量处理
connection.commit() //手工提交
} catch {
case e: Exception => e.printStackTrace()
} finally {
MySQLUtils.release(connection, pstmt) //释放连接
}
}
JDBC连接MySQL和释放连接用到了MySQLUtils中的方法
此外我们还需要在MySQL中插入表,用来写入统计数据,MySQL表已经设置好。
下面将程序和所有依赖打包,用spark-submit提交:
./spark-submit --class com.imooc.log.TopNStatJob2 --master spark://localhost:9000 /root/jar-files/sql-1.0-jar-with-dependencies.jar
执行结果:

Schema信息
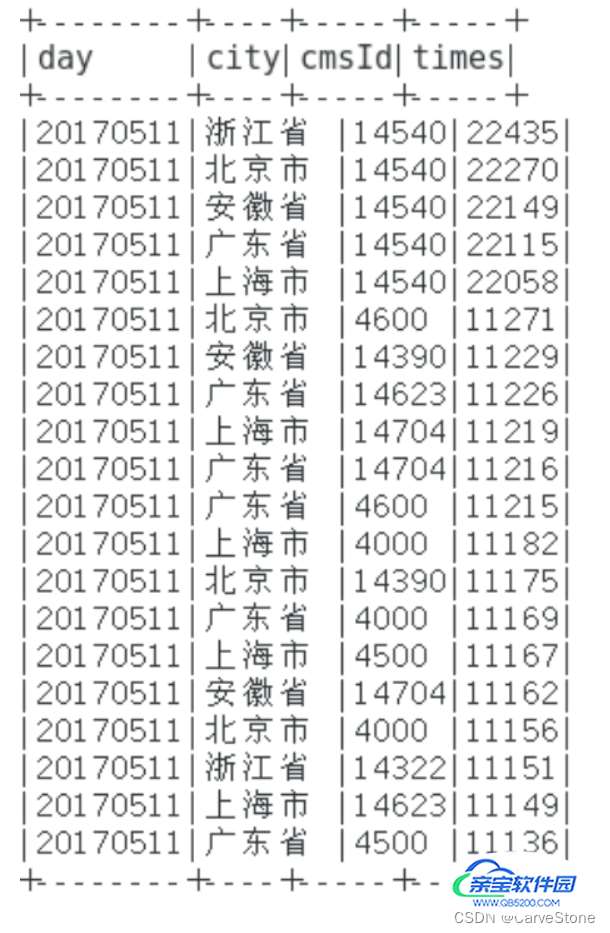
TopN课程信息
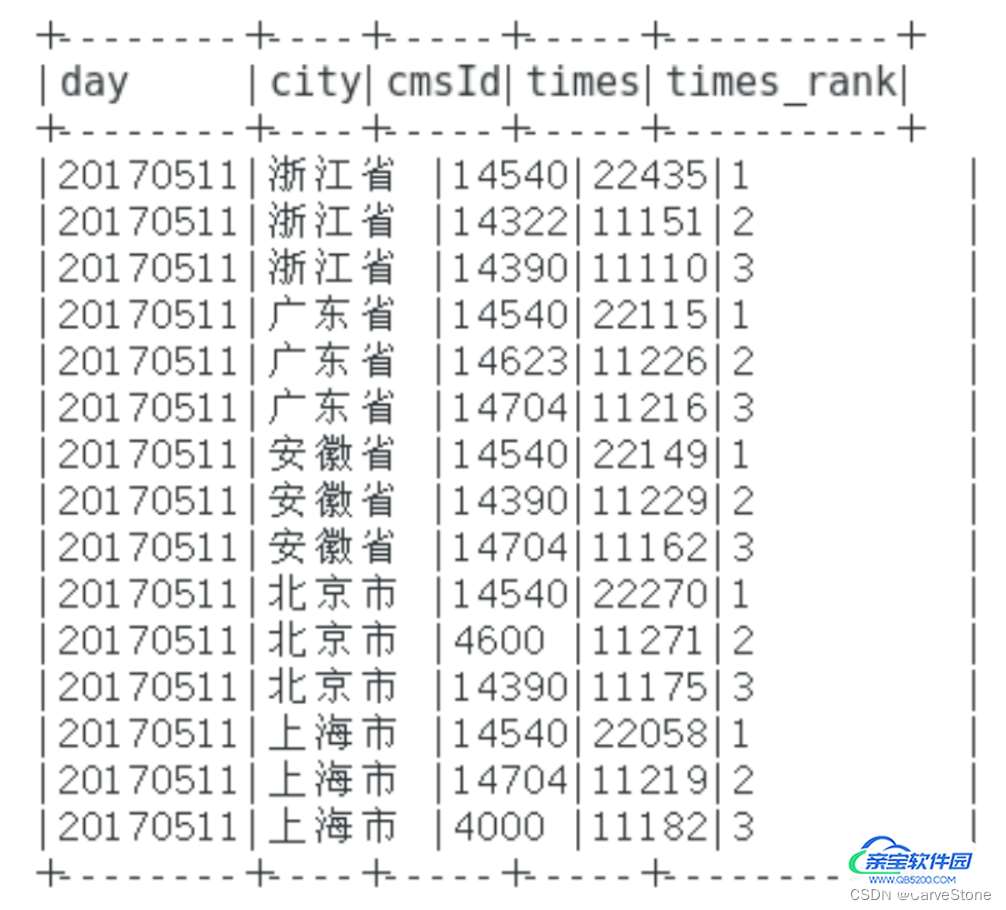
各地区Top3课程信息
MySQL表中数据:
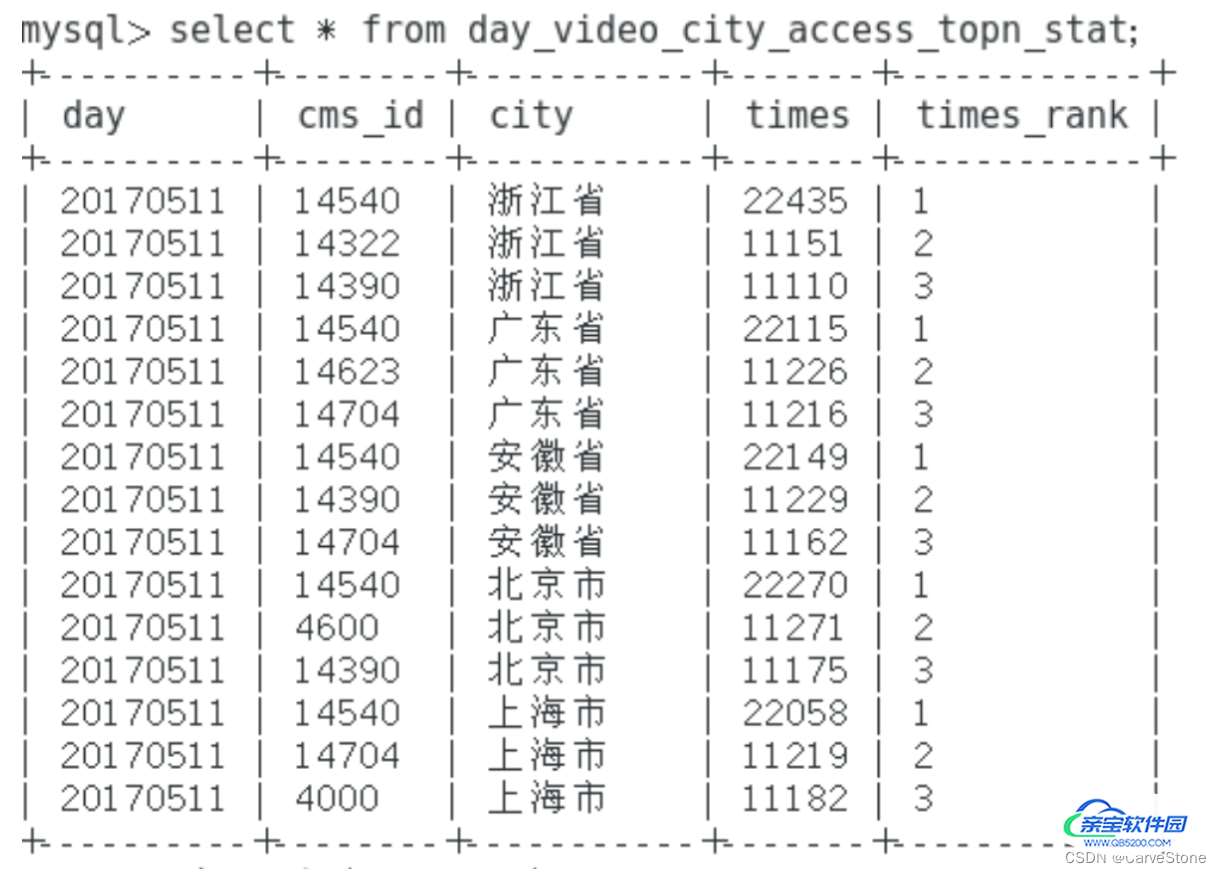
加载全部内容