java OpenTelemetry日志体系及缺陷解决方案
骑牛上青山 人气:0前言
OpenTelemetry为了实现其可观测性有三大体系:Trace,Metrics和Log。本文将对于OpenTelemetry实现的日志体系进行详细的讲述。
日志
说到日志相比大家都能侃侃而谈:帮助快速定位出现的问题,数据追踪,性能分析等等。日志可以说是与开发者们紧密关联常常使用到的东西。经过了多年的发展迭代,日志的体系也在不断变化,涌现了elk这种分布式日志的体系,能够便捷的帮助进行日志的管理和查询。
OpenTelemetry Log
在OpenTelemetry中,不属于Trace或Metrics的部分都可以视为日志。例如,event可以被认为是一种特殊的日志。
OpenTelemetry Log并没有单独拉出来组建一套日志的体系,而是全面拥抱现有的解决方案,在当前的众多日志类库的基础上进行对于可观测性的改进和整合。
OpenTelemetry Log的意义
传统日志的缺陷
现有的日志解决方案没有办法很好的和可观测性解决方案进行集成。日志对于追踪和监控的支持非常有限,通常是通过link的形式。而这种形式往往有部分数据不够完整。并且日志没有一个标准化的传播和记录上下文的解决方案,在分布式的系统中往往会导致从系统的不同组件收集到无法关联起来的日志。
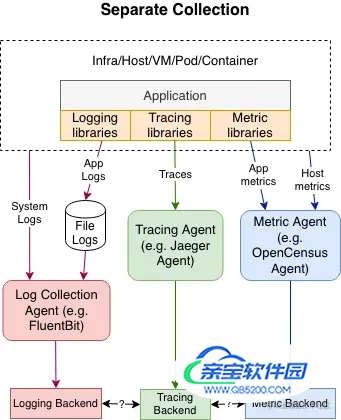
像上图这样不同的库有不同的采集协议采集方式,后端的服务很难将这种没有统一规范的杂乱数据进行统一,因此OpenTelemetry日志的统一规范就很有必要了。
OpenTelemetry日志的解决方案
本质上来说OpenTelemetry Log其实也就是应用的日志,和当前大家使用的日志体系并没有本质的区别。在Trace中广泛使用到的上下文传播的能力可以在日志中进行应用,这样可以丰富日志的关联能力,并且可以将日志与同是OpenTelemetry体系的metrics和trace关联到一起,遇到故障的排查会更加的便利。
假设这么一个场景:生产环境突发告警,然后排查到调用链路异常漫长需要排查原因,这个时候单纯的日志排查就显得很慢了,往往需要具体的报错信息或者是固定的时间点来进行定位。但是OpenTelemetry Log则可以通过异常链路的排查直接从链路定位到关联的日志之中,使得排查的难度大大降低。
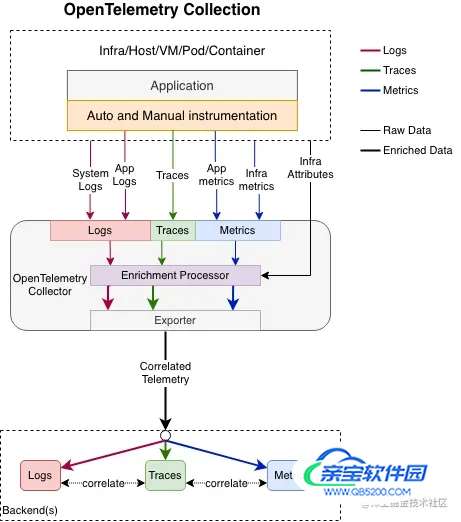
对于Trace和Merics,OpenTelemetry提供了新的API,而日志则比较特殊,当前的各个编程语言已经有了非常成熟的日志苦,例如Java的Logback和Log4j等等。
为了解决这些问题,OpenTelemetry做了如下的努力:
- 定义了一个日志数据模型。数据模型的目的是对
LogRecord的定义,日志系统的记录、传输、存储和解释等等有一个标准的规范。 - 将现有的日志格式与
OpenTelemetry定义的日志数据模型进行对应,并且collector将支持此种数据格式的转换。 - 提供
LogRecord的API给库的开发者提供丰富的能力。 - 提供SDK来对
LogRecord进行配置处理和导出。
上述的种种使得OpenTelemetry能够读取现有系统的应用程序日志,并且可以将其转化为OpenTelemetry定义的数据格式,以此来实现统一。
OpenTelemetry Log的使用
日志的关联
我们之前一直在说OpenTelemetry日志的特点是可以和其他数据进行更好的关联,那么关联的方式是什么呢?
OpenTelemetry为日志提供了如下的集中关联方式:
- 时间维度:这个是最基础的关联方式,
Trace,Metrics和Log都能够记录发生的时刻或者是时间范围,因此可以从时间的维度直接进行关联。 - 请求上下文:
OpenTelemetry可以在LogRecord中包含TraceId和SpanId,同样的Trace也是一样,并且这些信息是可以通过上下文进行传递的,凭借此信息,日志就能够互相进行串联,并且也可以和Trace一起进行整合。 - 资源上下文:即在
LogRecord中包含Resource的信息,以此来与其他数据关联。
Event
event也是一种特殊的日志,他的使用我们在前面的OpenTelemetry系列中有介绍过,就不在此赘述了。
OpenTelemetry Log的采集
OpenTelemetry Collector支持对于OpenTelemetry日志的采集和处理。
- 目前的
collector支持otlp协议的push式日志传输,但是此方式的问题在于当日志的量极其的大的时候会影响客户端服务的性能,并且对于collector本身的性能也是一个极大的挑战。 - 除此之外
collector也支持从日志文件pull的方式来自行获取数据。目前支持日志文件的读取,日志格式的解析等等,在collector中进行类似如下配置即可开启:
receivers:
filelog:
include: [ /var/log/myservice/*.json ]
operators:
- type: json_parser
timestamp:
parse_from: attributes.time
layout: '%Y-%m-%d %H:%M:%S'
- 目前
collector对于fluent forward方式有额外的支持,配置监听的端点即可直接以此方式采集数据。
如果是使用的pull模式,TraceId,SpanId等信息需要你自行在日志文件中进行输出,并且在采集后进行解析,不然日志就没办法和Trace等进行关联。
总结
在当前OpenTelemetry的日志体系可以说是已经初步完成并且接近于GA了,但是从个人的观感上来说距离生产可用还是有一定的距离的。
首先目前广泛使用的日志采集器Filebeat和Logstash本质上来说和OpenTelemetry Collector是二者取其一的关系,如果要完整启用OpenTelemetry日志体系,需要使用OpenTelemetry Collector来替换掉Filebeat和Logstash。这对于绝大多数的公司来说是一个极其艰难的过程,抛弃掉一个完善的体系来使用一个刚刚1.0的应用不是一件很容易的事情。
其次OpenTelemetry Collector的性能未必能有一定的保证。相对于久经考验的Filebeat和Logstash,OpenTelemetry Collector还很年轻,尽管他在Trace的采集上已经有过证明,但是日志的处理上还不太能给人信心。
其三由于OpenTelemetry体系会将Trace,Metrics,Log进行关联,因此其数据的存储也是需要考量的问题。一般来说使用Elasticsearch是能够兼容所有的完美策略,但是面对其巨大的数据量以及不同数据格式的处理时,需要仔细思考这样的存储体系是不是一定是最佳的方案。
总的来说从功能侧OpenTelemetry日志体系已经是一个较为完善的状态了,但是他在生产环境的运用到底如何还暂时需要打个问号。我们期待他的不断迭代,以及先行者在生产环境的使用结果。
加载全部内容