Java Set接口及常用实现类总结
馆主阿牛 人气:0前言
Collection的另一个子接口就是Set,他并没有我们List常用,并且自身也没有一些额外的方法,全是继承自Collection中的,因此我们还是简单总结一下,包括他的常用实现类HashSet、LinkedHashSet、TreeSet的总结!
概述
- Set 接口是 Collection 的子接口, set 接口没有提供额外的方法。
- Set 集合不允许包含相同的元素,如果试把两个相同的元素加入同一个
Set 集合中,则添加操作失败。 - Set 判断两个对象是否相同不是使用 == 运算符,而是根据equals()方法。
Set 无序性与不可重复性的理解
无序性
不等于随机性。
public static void main(String[] args) {
Set set = new HashSet();
set.add("aniu");
set.add(666);
set.add("yyds");
Iterator iterator = set.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}
}
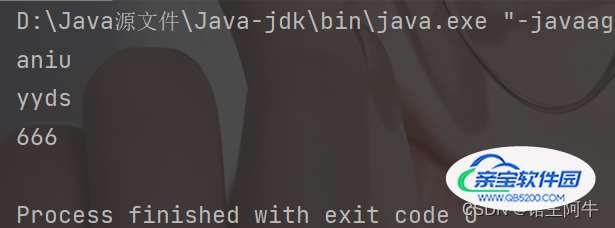
可以看到,他遍历输出的结果不同于元素添加顺序。但千万不要认为这就是无序性,这一点你可以对比LinkedHashSet,他也是无序的,但他区别于HashSet,他可以按照添加顺讯遍历Set。因此,这里无序性要从底层存储数据的角度理解:Set存储的数据在底层数组中并非按照数组索引的顺序添加,而是根据数据的哈希值。
不可重复性
保证添加的元素按照equals()判断时,不能返回True,即相同的元素只能添加一个。
需要注意的是,对于自定义类实现的对象,一定要重写hashcode和equals方法才能保证判断他们是否相等。
可以看下面这段代码:
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
/**
* @Author:Aniu
* @Date:2023/1/5 17:24
* @description TODO
*/
public class Demo {
public static void main(String[] args) {
Set set = new HashSet();
set.add("aniu");
set.add(666);
set.add("yyds");
set.add(new Stu("aniu",21));
set.add(new Stu("aniu",21));
Iterator iterator = set.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}
}
}
class Stu{
String name;
int age;
public Stu(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "Stu{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (!(o instanceof Stu)) return false;
Stu stu = (Stu) o;
if (age != stu.age) return false;
return name != null ? name.equals(stu.name) : stu.name == null;
}
}
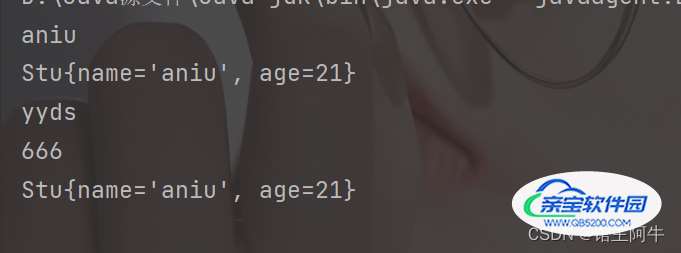
可以发现我们之只重写equals是不行的!
重写hashcode后再看结果:
@Override
public int hashCode() {
int result = name != null ? name.hashCode() : 0;
result = 31 * result + age;
return result;
}
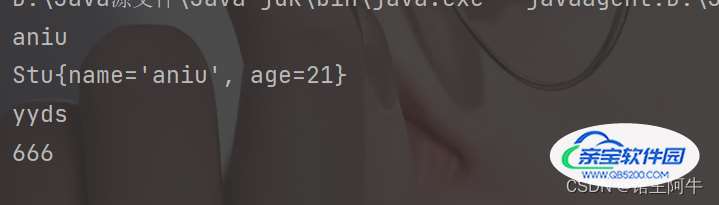
可以看到成功去掉了自定义对象的重复。这个和Set的底层存储原理有关,我们下面会写到!
Set 接口常用实现类
HashSet
作为Set接口的主要实现类,他是线程不安全的,可以存储null值!
HashSet中元素的添加过程
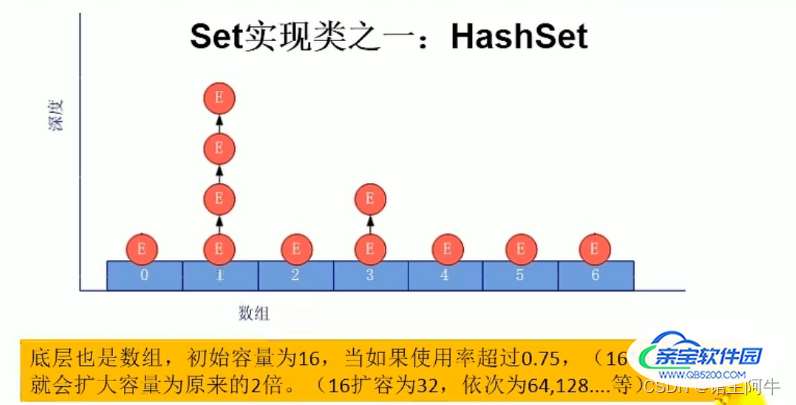
我们以HashSet为例,来大概说一下Set元素的添加过程:
我们向 Hashset 中添加元素 a ,首先调用元素 a 所在类的 hashcode ()方法,计算元素 a 的哈希值,此哈希值接着通过某种算法计算出 HashSet 底层数组中的存放位置(即为:索引位置),判断数组此位置上是否已经有元素:
1.如果此位置上没有其他元素,则元素 a 添加成功。
2.如果此位置上有其他元素(或以链表形式存在的多个元素),则比较元素a与元素 b 的 hash 值:
a.如果 hash 值不相同,则元素 a 添加成功。
b.如果 hash 值相同,进而需要调用元素 a 所在类的 equals ()方法:
- equals ()返回 true ,元素 a 添加失败
- equaLs ()返回 false ,则元素 a 添加成功。
对于添加成功的而言,如果通过hash值计算出的数组索引相同,则元素 a 与已经存在指定索引位置上数据以链表的方式存储。
这也就是上面不可重复性里写到的,对于自定义类实现的对象,一定要重写hashcode和equals方法才能保证判断他们是否相等。
这里源码就不分析了,因为 HashSet的底层是HashMap,我们后面会总结HashMap的源码分析!
LinkedHashSet
是HashSet的子类,遍历其内部数据时,可以按照添加的顺序遍历!
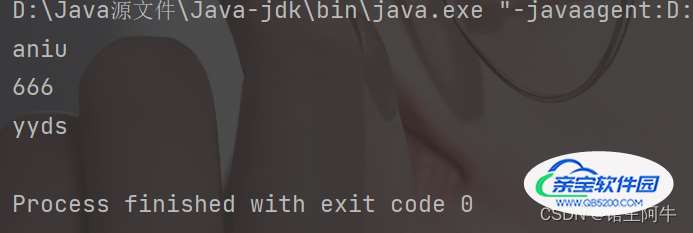
public static void main(String[] args) {
Set set = new LinkedHashSet();
set.add("aniu");
set.add(666);
set.add("yyds");
Iterator iterator = set.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}
}
LinkedHashSet为什么可以按照添加的元素顺序来遍历呢,看下面这张图就行了:
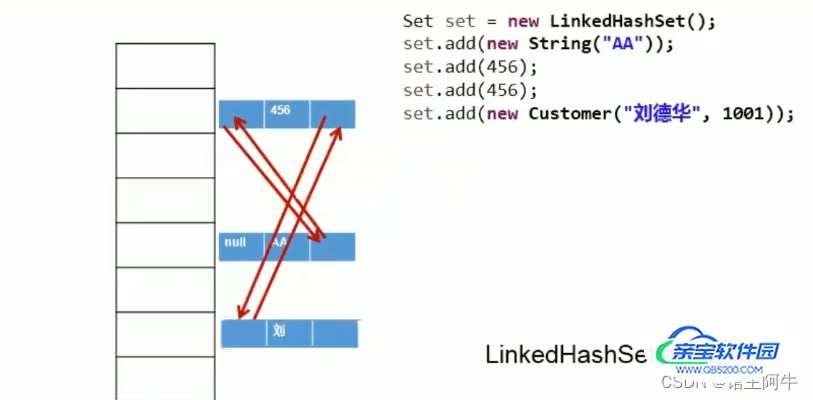
LinkedHashSet在原有HashSet的基础上提供了双向链表,保证了便历时的顺序输出!
对于频繁的便利操作,LinkedHashSet的效率高于HashSet!
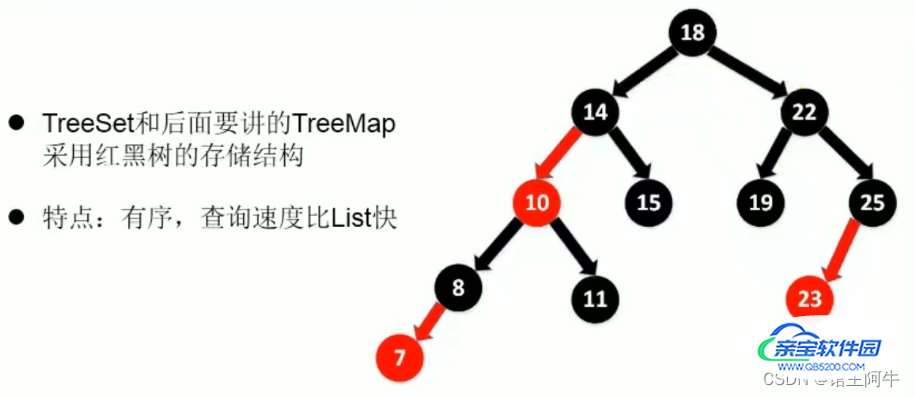
TreeSet
可以按照添加的元素的指定属性进行排序,因此,他要求添加的元素是同一数据类型!
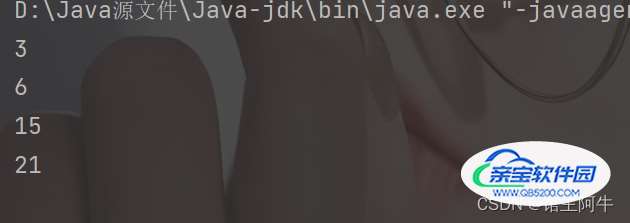
public class Demo {
public static void main(String[] args) {
Set set = new TreeSet();
set.add(3);
set.add(21);
set.add(15);
set.add(6);
Iterator iterator = set.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}
}
}
对于自定义类的对象,就需要我们前面总结的自然排序和定制排序了,这里不再写案例!
那再看看TreeSet的存储结构:
加载全部内容