golang优先级队列的实现全过程
游鱼的编程旅行 人气:0前言
在数据结构中,队列遵循着FIFO(先进先出)的规则。在此基础上,人们引申出了“优先级队列”的概念。
优先级队列,是带有优先级属性的队列,所有的队列元素按照优先级进行排序,消费者会先对优先级高的队列元素进行处理。
优先级队列的使用场景也是非常多的。比如,作业调度系统,当一个作业完成后,需要从剩下的作业中取出优先级最高的作业进行处理。又比如,一个商城的用户分为普通用户和vip用户,vip用户更容易抢到那些秒杀商品。
在本文中,我将和大家一起探讨,golang优先级队列的一种实现方案。
你可以收获
- golang切片特性
- golang map特性
- golang并发场景下的解决方案
- golang优先级队列的实现思路
正文
内容脉络
为了让大家脑海里有个大致的轮廓,我先把正文的大纲展示出来。
基础知识
在正式开始“优先级队列”这个话题之前,我们首先要明确以下的一些golang特性。
切片的特性
- 元素的有序性
- 非线程安全
map的特性
- 元素的无序性
- 非线程安全
并发场景下的解决方案
- 互斥锁:可以对非线程安全的数据结构创建临界区,一般用于同步场景;
- 管道:可以对非线程安全的数据结构进行异步处理
实现思路
既然,我们了解了golang的一些特性,那么,我们接下来就要明确,如何去实现优先级队列了。
我们都知道,无论是哪一种队列,必然是存在生产者和消费者两个部分,对于优先级队列来说,更是如此。因此,咱们的实现思路,也将从这两个部分来谈。
1、生产者
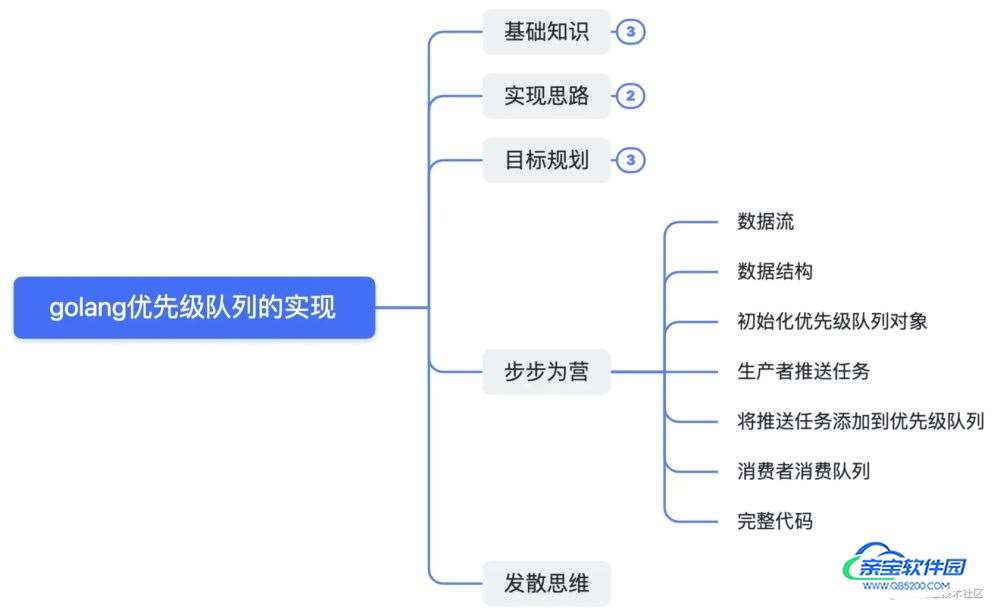
对于生产者来说,他只需要推送一个任务及其优先级过来,咱们就得根据优先级处理他的任务。
由于,我们不大好判断,到底会有多少种不同的优先级传过来,也无法确定,每种优先级下有多少个任务要处理,所以,我们可以考虑使用map来存储优先级队列。其中key为优先级,value为属于该优先级下的任务队列(即管道) 。
2、消费者
对于消费者来说,他需要获取优先级最高的任务进行消费。
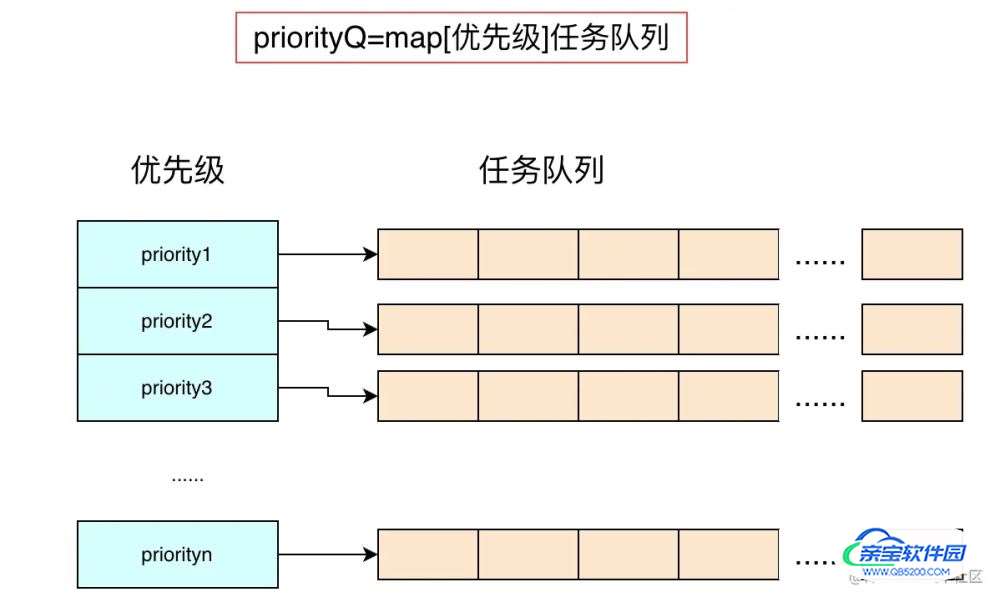
但是,如果只按照上面所说的map来存储优先级队列的话,我们是没法找到优先级最高的任务队列的,因为map的元素是无序的。那么,我们怎么处理这个问题呢?
我们都知道,在golang的数据结构里,切片的元素是具有有序性的。那么,我们只需要将所有的优先级按从小到大的方式,存储在一个切片里,就可以了。等到消费的时候,我们可以先从切片中,取出最大的优先级,然后再根据这个key去优先级队列的map中查询,是不是就可以了?
目标规划
想好了实现思路之后,我们就得对接下来的代码实现做一个规划了。
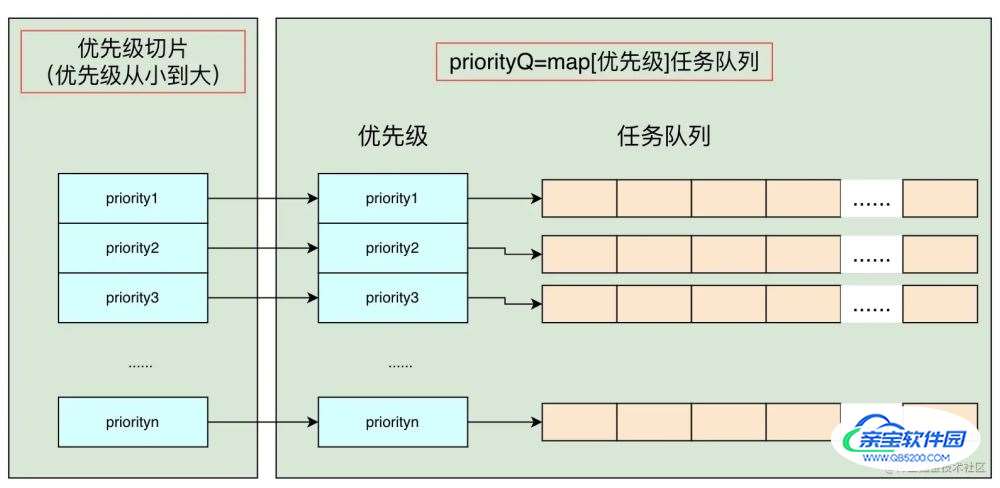
数据结构
- 存储优先级队列的map
- 存储优先级的切片
- 互斥锁
- 其他......
生产者
- 添加任务到优先级队列
消费者
- 从优先级队列获取任务
步步为营
1、数据流
(1)调用NewPriorityQueue() ,初始化优先级队列对象。
(2)初始化优先级队列map。
(3)开启协程,监听一个接收推送任务的全局管道pushChan。
(4)用户调用Push() ,推送的任务进入pushChan。
(5)推送的任务被加到优先级队列中。
(6)消费者从优先级队列中获取优先级最高的一个任务。
(7)消费者执行任务。

2、数据结构
(1)优先级队列对象
type PriorityQueue struct {
mLock sync.Mutex // 互斥锁,queues和priorities并发操作时使用
queues map[int]chan *task // 优先级队列map
pushChan chan *task // 推送任务管道
priorities []int // 记录优先级的切片(优先级从小到大排列)
}(2)任务对象
type task struct {
priority int // 任务的优先级
f func() // 任务的执行函数
}3、初始化优先级队列对象
func NewPriorityQueue() *PriorityQueue {
pq := &PriorityQueue{
queues: make(map[int]chan *task), // 初始化优先级队列map
pushChan: make(chan *task, 100),
}
return pq
}当然,在这个过程中,我们需要对pushChan进行监听。如果有任务推送过来,咱们得处理。
func (pq *PriorityQueue) listenPushChan() {
for {
select {
case taskEle := <-pq.pushChan:
// TODO 这里接收到推送的任务,并且准备处理
}
}
}将这个监听函数放到NewPriorityQueue()中:
func NewPriorityQueue() *PriorityQueue {
pq := &PriorityQueue{
queues: make(map[int]chan *task),
pushChan: make(chan *task, 100),
}
// 监听pushChan
go pq.listenPushChan()
return pq
}4、生产者推送任务
生产者推送任务的时候,我们只需要将任务放到pushChan中:
func (pq *PriorityQueue) Push(f func(), priority int) {
pq.pushChan <- &task{
f: f,
priority: priority,
}
}5、将推送任务加到优先级队列中
这一步就比较关键了。我们前面谈到,优先级队列最核心的数据结构有两个:优先级队列map和优先级切片。因此,推送任务添加到优先级队列的操作,咱们得分两种情况来看:
(1)之前已经推过相同优先级的任务
这种情况非常简单,咱们其实只要操作优先级队列map就可以了。
func (pq *PriorityQueue) listenPushChan() {
for {
select {
case taskEle := <-pq.pushChan:
priority := taskEle.priority
pq.mLock.Lock()
if v, ok := pq.queues[priority]; ok {
pq.mLock.Unlock()
// 之前推送过相同优先级的任务
// 将推送的任务塞到对应优先级的队列中
v <- taskEle
continue
}
// todo 之前未推过相同优先级任务的处理...
}
}
}(2)之前未推过相同优先级的任务
这种情况会稍微复杂一些。我们不仅要将新的优先级插入到优先级切片正确的位置,而且要将任务添加到对应优先级的队列。
1)将新的优先级插入到优先级切片中
a. 首先,咱们得寻找新优先级在切片中的插入位置。这里,咱们用了二分法。
// 通过二分法寻找新优先级的切片插入位置
func (pq *PriorityQueue) getNewPriorityInsertIndex(priority int, leftIndex, rightIndex int) (index int) {
if len(pq.priorities) == 0 {
// 如果当前优先级切片没有元素,则插入的index就是0
return 0
}
length := rightIndex - leftIndex
if pq.priorities[leftIndex] >= priority {
// 如果当前切片中最小的元素都超过了插入的优先级,则插入位置应该是最左边
return leftIndex
}
if pq.priorities[rightIndex] <= priority {
// 如果当前切片中最大的元素都没超过插入的优先级,则插入位置应该是最右边
return rightIndex + 1
}
if length == 1 && pq.priorities[leftIndex] < priority && pq.priorities[rightIndex] >= priority {
// 如果插入的优先级刚好在仅有的两个优先级之间,则中间的位置就是插入位置
return leftIndex + 1
}
middleVal := pq.priorities[leftIndex+length/2]
// 这里用二分法递归的方式,一直寻找正确的插入位置
if priority <= middleVal {
return pq.getNewPriorityInsertIndex(priority, leftIndex, leftIndex+length/2)
} else {
return pq.getNewPriorityInsertIndex(priority, leftIndex+length/2, rightIndex)
}
}b. 找到插入位置之后,我们才要插入。在这个过程中,插入位置右侧的元素全部都要向右边移动一位。
// index右侧元素均需要向后移动一个单位
func (pq *PriorityQueue) moveNextPriorities(index, priority int) {
pq.priorities = append(pq.priorities, 0)
copy(pq.priorities[index+1:], pq.priorities[index:])
pq.priorities[index] = priority
}这样,我们就成功地将新的优先级插入了切片。
2)将推送任务放入优先级队列map也就顺理成章。
// 创建一个新优先级管道 pq.queues[priority] = make(chan *task, 10000) // 将任务塞到新的优先级管道中 pq.queues[priority] <- taskEle
因此,listenPushChan()的代码如下:
func (pq *PriorityQueue) listenPushChan() {
for {
select {
case taskEle := <-pq.pushChan:
priority := taskEle.priority
pq.mLock.Lock()
if v, ok := pq.queues[priority]; ok {
pq.mLock.Unlock()
// 将推送的任务塞到对应优先级的队列中
v <- taskEle
continue
}
// 如果这是一个新的优先级,则需要插入优先级切片,并且新建一个优先级的queue
// 通过二分法寻找新优先级的切片插入位置
index := pq.getNewPriorityInsertIndex(priority, 0, len(pq.priorities)-1)
// index右侧元素均需要向后移动一个单位
pq.moveNextPriorities(index, priority)
// 创建一个新优先级队列
pq.queues[priority] = make(chan *task, 10000)
// 将任务塞到新的优先级队列中
pq.queues[priority] <- taskEle
pq.mLock.Unlock()
}
}
}完成了生产者部分之后,接下来我们看看消费者。
6、消费者消费队列
这里分成两个步骤,首先咱们得拿到最高优先级队列的任务,然后再去执行任务。代码如下:
// 消费者轮询获取最高优先级的任务
func (pq *PriorityQueue) Consume() {
for {
task := pq.Pop()
if task == nil {
// 未获取到任务,则继续轮询
continue
}
// 获取到了任务,就执行任务
task.f()
}
}
// 取出最高优先级队列中的一个任务
func (pq *PriorityQueue) Pop() *task {
pq.mLock.Lock()
defer pq.mLock.Unlock()
for i := len(pq.priorities) - 1; i >= 0; i-- {
if len(pq.queues[pq.priorities[i]]) == 0 {
// 如果当前优先级的队列没有任务,则看低一级优先级的队列中有没有任务
continue
}
// 如果当前优先级的队列里有任务,则取出一个任务。
return <-pq.queues[pq.priorities[i]]
}
// 如果所有队列都没有任务,则返回null
return nil
}7、完整代码
这样,咱们的优先级队列就实现了。下面,我们将完整代码展示。
pq.go
package priority_queue
import (
"sync"
)
type PriorityQueue struct {
mLock sync.Mutex // 互斥锁,queues和priorities并发操作时使用
queues map[int]chan *task // 优先级队列map
pushChan chan *task // 推送任务管道
priorities []int // 记录优先级的切片(优先级从小到大排列)
}
type task struct {
priority int // 任务的优先级
f func() // 任务的执行函数
}
func NewPriorityQueue() *PriorityQueue {
pq := &PriorityQueue{
queues: make(map[int]chan *task),
pushChan: make(chan *task, 100),
}
go pq.listenPushChan()
return pq
}
func (pq *PriorityQueue) listenPushChan() {
for {
select {
case taskEle := <-pq.pushChan:
priority := taskEle.priority
pq.mLock.Lock()
if v, ok := pq.queues[priority]; ok {
pq.mLock.Unlock()
// 将推送的任务塞到对应优先级的队列中
v <- taskEle
continue
}
// 如果这是一个新的优先级,则需要插入优先级切片,并且新建一个优先级的queue
// 通过二分法寻找新优先级的切片插入位置
index := pq.getNewPriorityInsertIndex(priority, 0, len(pq.priorities)-1)
// index右侧元素均需要向后移动一个单位
pq.moveNextPriorities(index, priority)
// 创建一个新优先级队列
pq.queues[priority] = make(chan *task, 10000)
// 将任务塞到新的优先级队列中
pq.queues[priority] <- taskEle
pq.mLock.Unlock()
}
}
}
// 插入work
func (pq *PriorityQueue) Push(f func(), priority int) {
pq.pushChan <- &task{
f: f,
priority: priority,
}
}
// index右侧元素均需要向后移动一个单位
func (pq *PriorityQueue) moveNextPriorities(index, priority int) {
pq.priorities = append(pq.priorities, 0)
copy(pq.priorities[index+1:], pq.priorities[index:])
pq.priorities[index] = priority
}
// 通过二分法寻找新优先级的切片插入位置
func (pq *PriorityQueue) getNewPriorityInsertIndex(priority int, leftIndex, rightIndex int) (index int) {
if len(pq.priorities) == 0 {
// 如果当前优先级切片没有元素,则插入的index就是0
return 0
}
length := rightIndex - leftIndex
if pq.priorities[leftIndex] >= priority {
// 如果当前切片中最小的元素都超过了插入的优先级,则插入位置应该是最左边
return leftIndex
}
if pq.priorities[rightIndex] <= priority {
// 如果当前切片中最大的元素都没超过插入的优先级,则插入位置应该是最右边
return rightIndex + 1
}
if length == 1 && pq.priorities[leftIndex] < priority && pq.priorities[rightIndex] >= priority {
// 如果插入的优先级刚好在仅有的两个优先级之间,则中间的位置就是插入位置
return leftIndex + 1
}
middleVal := pq.priorities[leftIndex+length/2]
// 这里用二分法递归的方式,一直寻找正确的插入位置
if priority <= middleVal {
return pq.getNewPriorityInsertIndex(priority, leftIndex, leftIndex+length/2)
} else {
return pq.getNewPriorityInsertIndex(priority, leftIndex+length/2, rightIndex)
}
}
// 取出最高优先级队列中的一个任务
func (pq *PriorityQueue) Pop() *task {
pq.mLock.Lock()
defer pq.mLock.Unlock()
for i := len(pq.priorities) - 1; i >= 0; i-- {
if len(pq.queues[pq.priorities[i]]) == 0 {
// 如果当前优先级的队列没有任务,则看低一级优先级的队列中有没有任务
continue
}
// 如果当前优先级的队列里有任务,则取出一个任务。
return <-pq.queues[pq.priorities[i]]
}
// 如果所有队列都没有任务,则返回null
return nil
}
// 消费者轮询获取最高优先级的任务
func (pq *PriorityQueue) Consume() {
for {
task := pq.Pop()
if task == nil {
// 未获取到任务,则继续轮询
continue
}
// 获取到了任务,就执行任务
task.f()
}
}测试代码pq_test.go:
package priority_queue
import (
"fmt"
"math/rand"
"testing"
"time"
)
func TestQueue(t *testing.T) {
defer func() {
if err := recover(); err != nil {
fmt.Println(err)
}
}()
pq := NewPriorityQueue()
rand.Seed(time.Now().Unix())
// 我们在这里,随机生成一些优先级任务
for i := 0; i < 100; i++ {
a := rand.Intn(10)
go func(i int) {
pq.Push(func() {
fmt.Println("推送任务的编号为:", i)
fmt.Println("推送的任务优先级为:", a)
fmt.Println("============")
}, a)
}(i)
}
// 这里会阻塞,消费者会轮询查询任务队列
pq.Consume()
}发散思维
上面的方案的确是实现了优先级队列,但是,有一种极端情况:如果消费者的消费速度远远小于生产者的生产速度,并且高优先级的任务被不断插入,这样,低优先级的任务就会有“饿死”的风险。
对于这种情况,我们在消费的时候,可以考虑给每一个优先级队列分配一个权重,高优先级的队列有更大的概率被消费,低优先级的概率相对较小。感兴趣的朋友们,可以自己去实现一下。
小结
本文和大家讨论了优先级队列在golang中的一种实现方案,里面应用到了切片、map、互斥锁、管道等诸多golang特性,可以说是一个非常典型的案例。其实,优先级队列在实际的业务场景中使用广泛,其实现方式也不止一种,我们需要根据实际的需求,选择最优解。
加载全部内容