python 使用pandas读取csv文件的方法
小白和小耳朵 人气:0在这里记录一下,python使用pandas读取文件的方法
用到pandas库的read_csv函数
# -*- coding: utf-8 -*-
"""
Created on Mon Jan 24 16:48:32 2022
@author: zxy
"""
# 导入包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
import seaborn as sns; plt.style.use('ggplot')
import sklearn
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.utils import shuffle
from sklearn.metrics import confusion_matrix
from sklearn.manifold import TSNE
# 导入并查看数据
crecreditcard_data=pd.read_csv('./creditcard.csv')
crecreditcard_data.shape,crecreditcard_data.info()
crecreditcard_data.describe()
crecreditcard_data.head()
# 看看欺诈与非欺诈的比例如何
count_classes=pd.value_counts(crecreditcard_data['Class'],sort=True).sort_index()
# 统计下具体数据
count_classes.value_counts()
# 也可以用count_classes[0],count_classes[1]看分别数据
count_classes.plot(kind='bar')
plt.show()
知识点扩展:
pandas读取csv文件的操作
1. 读取csv文件
import pandas as pd
import numpy as np
# 读取整个csv文件
csv_data = pd.read_csv("./stock_day.csv")
# 读取指定列索引字段的数据
csv_data = pd.read_csv("./stock_day.csv", usecols=['open', 'close'])
# 将我们修改完的csv的文件保存到新的路径下
csv_data.to_csv('demo.csv')观察我们保存的文件的格式(行索引为我们的日期, 列索引为 open close) :

# 查看新保存的文件
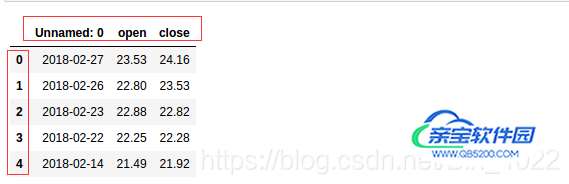
new_data = read_csv('./demo.csv')观察新保存的文件(我们在读取的时候默认给我们添加了新的行索引, 及Unnamed:0):
使用to_csv的时候, 我们可以给他传入几个参数:
csv_data.to_csv('demo.csv', header=True, index=False)
to_csv这个方法中可以传递一些参数:
DataFrame.to_csv(path_or_buf=None, sep=', ’, columns=None, header=True, index=True, index_label=None, mode='w', encoding=None)
- path_or_buf :文件保存的路径;
- sep :默认是以 , 进行分割 , 也可以自己制定;
- columns : 保存索引列和指定列;
- index:是否写进行索引 0或者1;
- header :boolean or list of string, default True,是否写进列索引值 0或者 1;
- na_rep=NaN: 缺失值保存为Na 如果不写 默认为空;
- float_format='%.2f' :保留两位小数;
再来回顾一下将我们的行索引装成日期格式的方法:
# 生成一个时间的序列,略过周末非交易日
date = pd.date_range('2018-02-27', periods=new_data.shape[1], freq='B')
# index代表行索引,columns代表列索引
new_data = pd.DataFrame(new_data, index=date)加载全部内容