python pandas 解析(读取、写入)CSV 文件的操作方法
qiuqiu1027 人气:01. 使用 pandas 读取 CSV 文件
原始数据包含了公司员工的数据:
| Name | Hire Date | Salary | Sick Days remaining |
|---|---|---|---|
| Graham Chapman | 03/15/14 | 50000.00 | 10 |
| John Cleese | 06/01/15 | 65000.00 | 8 |
| Eric Idle | 05/12/14 | 45000.00 | 10 |
| Terry Jones | 11/01/13 | 70000.00 | 3 |
| Terry Gilliam | 08/12/14 | 48000.00 | 7 |
| Michael Palin | 05/23/13 | 66000.00 | 8 |
将 CSV 文件读入 pandas DataFrame 快速而直接:
import pandas
df = pandas.read_csv('hrdata.csv')
print(df)就这样简单:仅仅三行代码,而且其中只有一行真正有用。pandas.read_csv() 打开、分析并读取提供的 CSV 文件,并将数据存储在 DataFrame 中,打印 DataFrame 会产生以下输出:
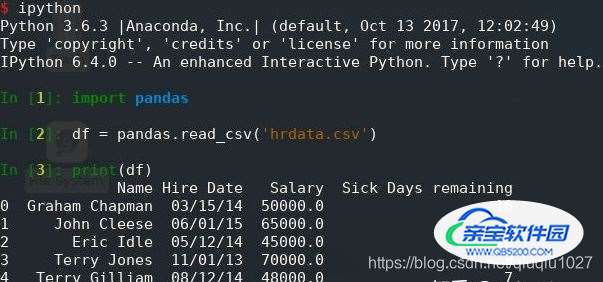
以下是值得注意的几点:
首先,pandas 识别到 CSV 的第一行包含列名,并自动使用它们。
但是,pandas 也在 DataFrame 中使用从零开始的整数索引,那是因为没有告诉它我们的索引应该是什么。
此外,如果查看列的数据类型,会看到 pandas 已将 Salary and Sick Days 剩余列正确转换为数字,但 Hire Date 列仍然是 String,这在交互模式下很容易确认:

让我们一次解决这些问题,要使用其他列作为 DataFrame 的索引,添加 index_col 可选参数:
df2 = pandas.read_csv('hrdata.csv', index_col='Name')
print(df2)现在,Name 字段就是我们的 DataFrame 索引:
接下来,让我们修复「Hire Date」字段的数据类型。可以使用 parse_dates 可选参数强制pandas 将数据作为日期读取,该参数定义为要作为日期处理的列名列表:
df3 = pandas.read_csv('hrdata.csv', index_col='Name', parse_dates=['Hire Date'])
print(df3)注意输出的差异:
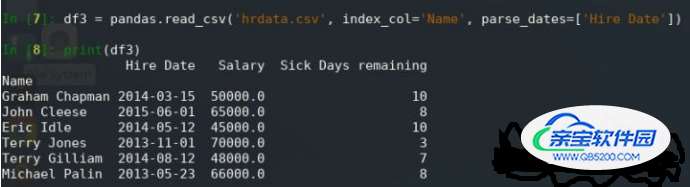
现在日期格式正确,可以在交互模式下轻松确认:
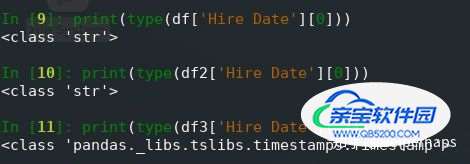
如果 CSV 文件的第一行中没有列名,则可以使用 names 可选参数来提供列名的列表。 如果要覆盖第一行中提供的列名,也可以使用此选项。 在这种情况下,还必须使用header = 0可选参数告诉 pandas.read_csv()忽略现有列名:
df4 = pandas.read_csv('hrdata.csv',
index_col='Employee',
parse_dates=['Hired'],
header=0,
names=['Employee', 'Hired','Salary', 'Sick Days'])
print(df4)请注意,由于列名称已更改,因此还必须更改index_col和parse_dates可选参数中指定的列,现在这会产生以下输出:
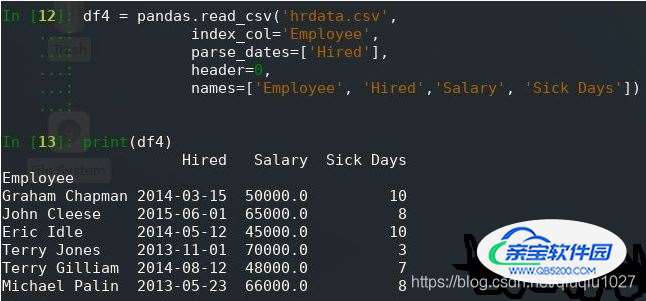
2. 使用 pandas 写入 CSV 文件
当然,如果无法将数据从 pandas 中输出,那 pandas 可能没有多大好处。将 DataFrame 写入CSV 文件就像读取一个文件一样简单。下面让我们将带有新列名称的数据写入新的 CSV 文件:
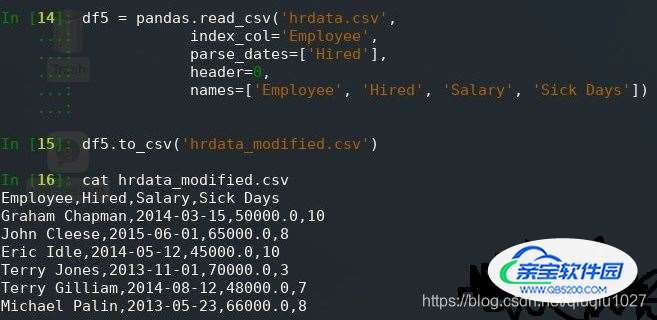
df5 = pandas.read_csv('hrdata.csv',
index_col='Employee',
parse_dates=['Hired'],
header=0,
names=['Employee', 'Hired', 'Salary', 'Sick Days'])
df5.to_csv('hrdata_modified.csv')此代码与上述读取代码之间的唯一区别是 print(df) 替换为 df.to_csv(),新的 CSV 文件如下所示:
参考此文章连接
加载全部内容