Python使用pandas导入xlsx格式的excel文件内容操作代码
smart_cat 人气:0Python使用pandas导入xlsx格式的excel文件内容
1. 基本导入
在 Python中使用pandas导入.xlsx文件的方法是read_excel()。
# coding=utf-8 import pandas as pd df = pd.read_excel(r'G:\test.xlsx') print(df)
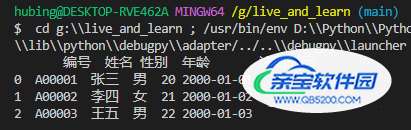
电脑中的文件路径默认使用\,这个时候需要在路径前面加一个r(转义符)避免路径里面的\被转义。也可以不加 r,但是需要把路径里面的所有\转换成/,这个规则在导入其他格式文件时也是一样的,我们一般选择在路径前面加r
2. 列标题与数据对齐
因为我们的表格中有中文,中文占用的字符和英文、数字占用的字符不一样,因此需要调用pd.set_option()使表格对齐显示。如果你是使用 Jupyter 来运行代码的,Jupyter 会自动渲染出一个表格,则无需这个设置。
import pandas as pd
#处理数据的列标题与数据无法对齐的情况
pd.set_option('display.unicode.ambiguous_as_wide', True)
#无法对齐主要是因为列标题是中文
pd.set_option('display.unicode.east_asian_width', True)
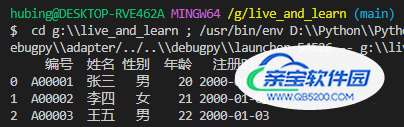
df = pd.read_excel(r'G:\test.xlsx')
print(df)效果如下:
3. 指定导入某个sheet
通过sheet_name参数可以指定要导入哪个sheet的内容。注意这里的名字是区分大小写的。
import pandas as pd
pd.set_option('display.unicode.ambiguous_as_wide', True)
pd.set_option('display.unicode.east_asian_width', True)
df = pd.read_excel(r'G:\test.xlsx', sheet_name='Sheet1')
print(df)除了可以指定具体的sheet名字,还可以传入sheet的index下标,从0开始计数。例如:
# coding=utf-8
import pandas as pd
pd.set_option('display.unicode.ambiguous_as_wide', True)
pd.set_option('display.unicode.east_asian_width', True)
df = pd.read_excel(r'G:\test.xlsx', sheet_name=0)
print(df)如果不指定sheet_name参数,那么默认导入的都是第一个sheet的内容。
4. 指定行索引
在本地文件导入DataFrame时,行索引使用的从0开始的默认索引,可以通过设置index_col参数来设置。
# coding=utf-8
import pandas as pd
pd.set_option('display.unicode.ambiguous_as_wide', True)
pd.set_option('display.unicode.east_asian_width', True)
df = pd.read_excel(r'G:\test.xlsx', sheet_name=0, index_col=0)
print(df)
5. 指定列索引
将本地文件导入DataFrame时,默认使用源数据表的第一行作为列索引,也可以通过设置header参数来设置列索引。 header参数值默认为0,即用第一行作为列索引;也可以是其他行,只需要传入具体的那一行即可;也可以使用默认从0开始的数作为列索引。
使用默认从0开始的数作为列索引示意:
# coding=utf-8
import pandas as pd
pd.set_option('display.unicode.ambiguous_as_wide', True)
pd.set_option('display.unicode.east_asian_width', True)
df = pd.read_excel(r'G:\test.xlsx', sheet_name=0, header=None)
print(df)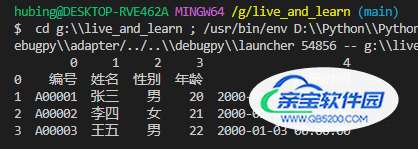
6. 指定导入列
有的时候本地文件的列数太多,而我们又不需要那么多列时,我们就可以通过设定usecols参数来指定要导入的列。

从参数的形式来看,可以通过以下几种形式来指定:
- 通过列表指定,列表中是列的下标,从0开始计数。
- 通过列表指定,列表中是列的名字
- 通过元组指定, 元组中是列的名字
示例如下:
df = pd.read_excel(r'G:\test.xlsx', sheet_name=0, usecols=[0,1]) print(df)
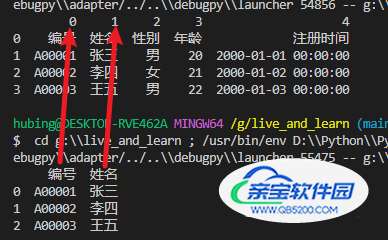
df = pd.read_excel(r'G:\test.xlsx', sheet_name=0, usecols=['姓名','性别']) print(df)
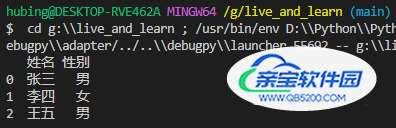
df = pd.read_excel(r'G:\test.xlsx', sheet_name=0, usecols=('姓名','年龄'))
print(df)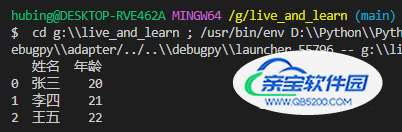
7. 指定导入的行数
如果文件很大,我们不想导入全部的行,只需要导入前面若干行进行分析即可,那么可以通过nrows参数来指定导入多少行数据
df = pd.read_excel(r'G:\test.xlsx', sheet_name=0, nrows=2) print(df)
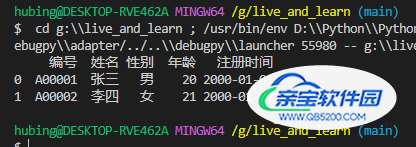
8. 更多的参数
请参考pandas官方文档。
加载全部内容