PyTorch Lightning 模型部署
ronghuaiyang 人气:8导读
一篇用PyTorch Lighting提供模型服务的完全指南。
纵观机器学习领域,一个主要趋势是专注于将软件工程原理应用于机器学习的项目。例如,Cortex重新创造了部署serverless功能的体验,但使用了推理管道。类似地,DVC实现了现代版本控制和CI/CD管道,但是是针对ML的。\
PyTorch Lightning也有类似的理念,只适用于训练。这些框架为PyTorch提供了一个Python包装器,让数据科学家和工程师可以编写干净、易于管理和性能训练的代码。
作为构建整个部署平台的人,部分原因是我们讨厌编写样板文件,我们是PyTorch Lightning的忠实粉丝。本着这种精神,我整理了这篇将PyTorch Lightning模型部署到生产中的指南。在此过程中,我们将了解一些用于导出PyTorch Lightning模型并将其包含在推理管道中的不同选项。
使用PyTorch Lightning模型进行推理的各种方法
有三种方法导出用于PyTorch Lightning模型进行服务:
- 保存模型为PyTorch检查点
- 将模型转换为ONNX
- 导出模型到Torchscript
我们可以用Cortex来对这三种进行服务。
1. 直接打包部署PyTorch Lightning模型
从最简单的方法开始,让我们部署一个不需要任何转换步骤的PyTorch Lightning模型。
PyTorch Lightning训练器是一个抽象了样板训练代码(想想训练和验证步骤)的类,它有一个内置的save_checkpoint()函数,可以将模型保存为.ckpt文件。要将你的模型保存为一个检查点,只需将以下代码添加到你的训练脚本中:

现在,在我们开始服务这个检查点之前,重要的是要注意,当我一直说“PyTorch Lightning模型”时,PyTorch Lightning是PyTorch的一个封装 —— 项目的自述文件字面上说“PyTorch Lightning只是有组织的PyTorch”。因此,导出的模型是一个正常的PyTorch模型,可以相应地提供服务。
有了保存好的检查点,我们就可以轻松地在Cortex中使用该模型。关于Cortex的部署过程的简单概述如下:
- 我们用Python为我们的模型编写了一个预测API
- 我们在YAML中定义api的基础结构和行为
- 我们通过CLI命令来部署API
我们的预测API将使用Cortex的Python Predictor类来定义一个init()函数来初始化我们的API并加载模型,以及一个predict()函数来在查询时提供预测:
import torch
import pytorch_lightning as pl
import MyModel from training_code
from transformers import (
AutoModelForSequenceClassification,
AutoConfig,
AutoTokenizer
)
class PythonPredictor:
def __init__(self, config):
self.device = "cpu"
self.tokenizer = AutoTokenizer.from_pretrained("albert-base-v2")
self.model = MyModel.load_from_checkpoint(checkpoint_path="./model.ckpt")
def predict(self, payload):
inputs = self.tokenizer.encode_plus(payload["text"], return_tensors="pt")
predictions = self.model(**inputs)[0]
if (predictions[0] > predictions[1]):
return {"class": "unacceptable"}
else:
return {"class": "acceptable"}
很简单。我们从训练代码中重新定义了一些代码,添加了一些推理逻辑,就是这样。需要注意的一点是,如果你将模型上传到S3(推荐),你需要添加一些访问它的逻辑。
接下来,我们在YAML中配置基础的设置:
- name: acceptability-analyzer
kind: RealtimeAPI
predictor:
type: python
path: predictor.py
compute:
cpu: 1
同样也很简单。我们给API一个名称,告诉Cortex我们的预测API在哪里,并分配CPU。
接下来,我们部署它:
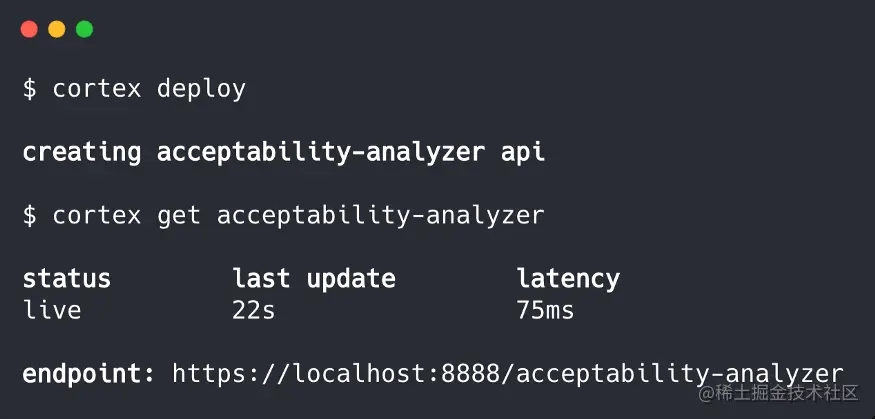
注意,我们也可以将其部署到一个集群中,并由Cortex进行管理:
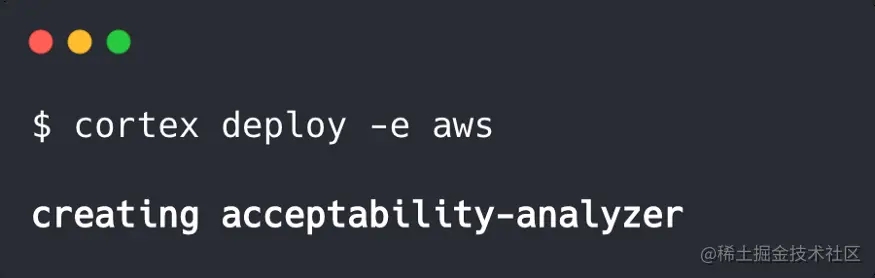
在所有的部署中,Cortex将我们的API打包并将其作为web的服务公开。通过云部署,Cortex可以配置负载平衡、自动扩展、监控、更新和许多其他基础设施功能。
现在,我们有了一个实时的web API,可以通过请求用模型进行预测。
2. 导出为ONNX并通过ONNX Runtime进行服务
现在我们已经部署了一个普通的PyTorch检查点,让我们把事情复杂化一点。
PyTorch Lightning最近添加了一个方便的抽象,用于将模型导出到ONNX(以前,你可以使用PyTorch的内置转换函数,尽管它们需要更多的样板文件)。要将模型导出到ONNX,只需将以下代码添加到训练脚本中:

注意,输入样本应该模拟实际模型输入的形状。
一旦你导出了ONNX模型,你就可以使用Cortex的ONNX Predictor来服务它。代码基本上是一样的,过程也是一样的。例如,这是一个ONNX预测API:
import pytorch_lightning as pl
from transformers import (
AutoModelForSequenceClassification,
AutoConfig,
AutoTokenizer
)
class ONNXPredictor:
def __init__(self, onnx_client, config):
self.device = "cpu"
self.client = onnx_client
self.tokenizer = AutoTokenizer.from_pretrained("albert-base-v2")
def predict(self, payload):
inputs = self.tokenizer.encode_plus(payload["text"], return_tensors="pt")
predictions = self.client.predict(**inputs)[0]
if (predictions[0] > predictions[1]):
return {"class": "unacceptable"}
else:
return {"class": "acceptable"}
基本上是一样的。唯一的区别是,我们不是直接初始化模型,而是通过onnx_client访问它,这是一个ONNX运行时容器,Cortex为我们的模型提供服务。
我们的YAML看起来也很相似:
- name: acceptability-analyzer
kind: RealtimeAPI
predictor:
type: onnx
path: predictor.py
model_path: s3://your-bucket/model.onnx
monitoring:
model_type: classification
我在这里添加了一个监视标志,只是为了说明配置它是多么容易,并且有一些ONNX特定的字段,但除此之外是相同的YAML。
最后,我们使用与之前相同的$ cortex deploy命令进行部署,我们的ONNX API也是可用的。
3. 使用 Torchscript’s JIT compiler序列化
对于最后的部署,我们把PyTorch Lightning模型导出到Torchscript,并使用PyTorch的JIT编译器提供服务。要导出模型,只需将此添加到你的训练脚本:

这个的Python API与普通的PyTorch示例几乎相同:
import torch
from torch import jit
from transformers import (
AutoModelForSequenceClassification,
AutoConfig,
AutoTokenizer
)
class PythonPredictor:
def __init__(self, config):
self.device = "cpu"
self.tokenizer = AutoTokenizer.from_pretrained("albert-base-v2")
self.model = jit.load("model.ts")
def predict(self, payload):
inputs = self.tokenizer.encode_plus(payload["text"], return_tensors="pt")
predictions = self.model(**inputs)[0]
if (predictions[0] > predictions[1]):
return {"class": "unacceptable"}
else:
return {"class": "acceptable"}
YAML与以前一样,CLI命令当然是一致的。如果我们愿意,我们可以通过简单地用新的脚本替换旧的predictor.py脚本来更新之前的PyTorch API,并再次运行$ cortex deploy:
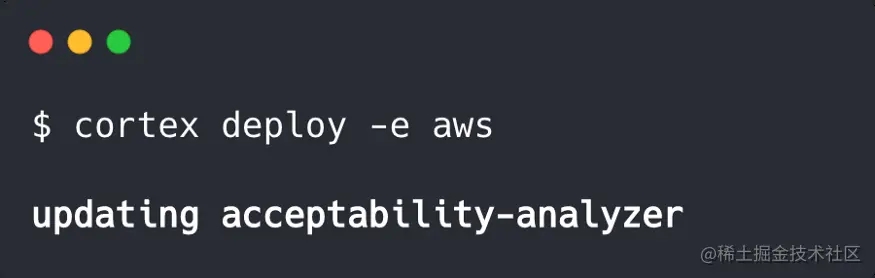
在这里,Cortex会自动执行滚动更新,即启动一个新的API,然后与旧API进行交换,从而防止模型更新之间的停机时间。
就是这样。现在,你有了一个用于实时推断的完全可操作的预测API,从Torchscript模型提供预测。
那么,你会用哪种方法呢?
这里明显的问题是哪种方法性能最好。事实上,这里没有一个简单的答案,因为它取决于你的模型。
对于BERT和GPT-2这样的Transformer模型,ONNX可以提供令人难以置信的优化(我们测量了cpu吞吐量有40倍提高)。对于其他模型,Torchscript可能比vanilla PyTorch表现得更好 —— 尽管这也带来了一些警告,因为并不是所有的模型都清晰地导出到Torchscript。
幸运的是,使用任何选项都可以很容易地进行部署,因此可以并行测试这三种方法,看看哪种最适合你的特定API.
加载全部内容