Python实现LSTM模块
qyhyzard 人气:0LSTM 简介:
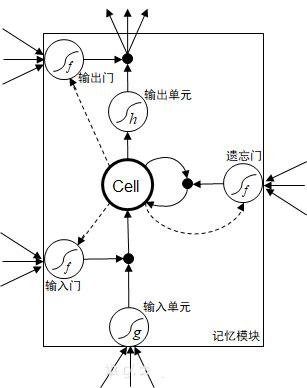
LSTM是RNN中一个较为流行的网络模块。主要包括输入,输入门,输出门,遗忘门,激活函数,全连接层(Cell)和输出。
其结构如下:

上述公式不做解释,我们只要大概记得以下几个点就可以了:
- 当前时刻LSTM模块的输入有来自当前时刻的输入值,上一时刻的输出值,输入值和隐含层输出值,就是一共有四个输入值,这意味着一个LSTM模块的输入量是原来普通全连接层的四倍左右,计算量多了许多。
- 所谓的门就是前一时刻的计算值输入到sigmoid激活函数得到一个概率值,这个概率值决定了当前输入的强弱程度。 这个概率值和当前输入进行矩阵乘法得到经过门控处理后的实际值。
- 门控的激活函数都是sigmoid,范围在(0,1),而输出输出单元的激活函数都是tanh,范围在(-1,1)。
Pytorch实现如下:
import torch
import torch.nn as nn
from torch.nn import Parameter
from torch.nn import init
from torch import Tensor
import math
class NaiveLSTM(nn.Module):
"""Naive LSTM like nn.LSTM"""
def __init__(self, input_size: int, hidden_size: int):
super(NaiveLSTM, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
# input gate
self.w_ii = Parameter(Tensor(hidden_size, input_size))
self.w_hi = Parameter(Tensor(hidden_size, hidden_size))
self.b_ii = Parameter(Tensor(hidden_size, 1))
self.b_hi = Parameter(Tensor(hidden_size, 1))
# forget gate
self.w_if = Parameter(Tensor(hidden_size, input_size))
self.w_hf = Parameter(Tensor(hidden_size, hidden_size))
self.b_if = Parameter(Tensor(hidden_size, 1))
self.b_hf = Parameter(Tensor(hidden_size, 1))
# output gate
self.w_io = Parameter(Tensor(hidden_size, input_size))
self.w_ho = Parameter(Tensor(hidden_size, hidden_size))
self.b_io = Parameter(Tensor(hidden_size, 1))
self.b_ho = Parameter(Tensor(hidden_size, 1))
# cell
self.w_ig = Parameter(Tensor(hidden_size, input_size))
self.w_hg = Parameter(Tensor(hidden_size, hidden_size))
self.b_ig = Parameter(Tensor(hidden_size, 1))
self.b_hg = Parameter(Tensor(hidden_size, 1))
self.reset_weigths()
def reset_weigths(self):
"""reset weights
"""
stdv = 1.0 / math.sqrt(self.hidden_size)
for weight in self.parameters():
init.uniform_(weight, -stdv, stdv)
def forward(self, inputs: Tensor, state: Tuple[Tensor]) \
-> Tuple[Tensor, Tuple[Tensor, Tensor]]:
"""Forward
Args:
inputs: [1, 1, input_size]
state: ([1, 1, hidden_size], [1, 1, hidden_size])
"""
# seq_size, batch_size, _ = inputs.size()
if state is None:
h_t = torch.zeros(1, self.hidden_size).t()
c_t = torch.zeros(1, self.hidden_size).t()
else:
(h, c) = state
h_t = h.squeeze(0).t()
c_t = c.squeeze(0).t()
hidden_seq = []
seq_size = 1
for t in range(seq_size):
x = inputs[:, t, :].t()
# input gate
i = torch.sigmoid(self.w_ii @ x + self.b_ii + self.w_hi @ h_t +
self.b_hi)
# forget gate
f = torch.sigmoid(self.w_if @ x + self.b_if + self.w_hf @ h_t +
self.b_hf)
# cell
g = torch.tanh(self.w_ig @ x + self.b_ig + self.w_hg @ h_t
+ self.b_hg)
# output gate
o = torch.sigmoid(self.w_io @ x + self.b_io + self.w_ho @ h_t +
self.b_ho)
c_next = f * c_t + i * g
h_next = o * torch.tanh(c_next)
c_next_t = c_next.t().unsqueeze(0)
h_next_t = h_next.t().unsqueeze(0)
hidden_seq.append(h_next_t)
hidden_seq = torch.cat(hidden_seq, dim=0)
return hidden_seq, (h_next_t, c_next_t)
def reset_weigths(model):
"""reset weights
"""
for weight in model.parameters():
init.constant_(weight, 0.5)
### test
inputs = torch.ones(1, 1, 10)
h0 = torch.ones(1, 1, 20)
c0 = torch.ones(1, 1, 20)
print(h0.shape, h0)
print(c0.shape, c0)
print(inputs.shape, inputs)
# test naive_lstm with input_size=10, hidden_size=20
naive_lstm = NaiveLSTM(10, 20)
reset_weigths(naive_lstm)
output1, (hn1, cn1) = naive_lstm(inputs, (h0, c0))
print(hn1.shape, cn1.shape, output1.shape)
print(hn1)
print(cn1)
print(output1)
对比官方实现:
# Use official lstm with input_size=10, hidden_size=20 lstm = nn.LSTM(10, 20) reset_weigths(lstm) output2, (hn2, cn2) = lstm(inputs, (h0, c0)) print(hn2.shape, cn2.shape, output2.shape) print(hn2) print(cn2) print(output2)
可以看到与官方的实现有些许的不同,但是输出的结果仍旧一致。

加载全部内容