Python read_csv读数据分隔符问题
清三皮 人气:0用read_csv读数据遇到分隔符问题的两种解决方式
import pandas as pd
1.更改read_csv函数中的传参“sep”
1.1缺省sep参数
默认分隔符为‘,’
1.2不缺省sep参数
1.2.1要读入的文档中分隔符为一位字符
用单引号括起文本中的分隔符
例:sep = '|'
1.2.2要读入的文档中分隔符为多位字符
多位字符在python中被识别为正则式
此时可用为sep = ‘\s+’(不论多位分隔符有什么组成,比如几个空格、\r\t)
此时,python将用自己的语法分析器来对多位字符进行识别
2.利用记事本功能进行分隔符替换
因为自己在编程的时候用正则表达式出现了一些问题,故找到了另一种更改文本中分隔符,以便于设定sep参数的方法,现记录如下。
2.1利用txt中的“编辑”—>“替换”操作
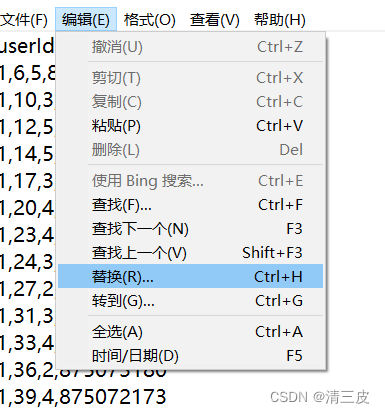
当前分隔符为‘,’

替换为‘ | ’,并单击全部替换
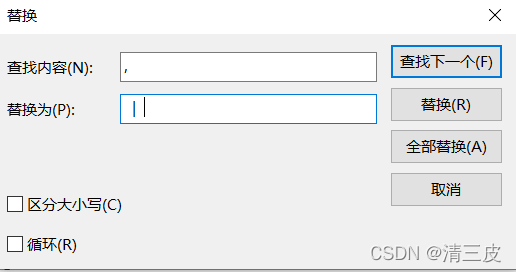
替换后,分隔符为‘ | ’
2.2小tips
选择分隔符的时候有可能面临
“这么大空挡是几个空格?”
“这个逗号是中文的还是英文的?”
…
所以建议直接用鼠标拉着两个数据之间的分割区域,复制,然后粘贴填入要替换的框中。(像我这种手残眼花的人就喜欢这种方式。。。)
补充:Python read_csv 报错:‘gbk‘ codec can‘t decode byte 0xb4 in position 8: illegal multibyte sequence
在我们使用pandas.read_csv()读取文件时 经常会遇到UnicodeDecodeError 的错误
我遇到的主要有两种:
UnicodeDecodeError: 'gbk' codec can't decode byte 0xb4 in position 8: illegal multibyte sequence
或者
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xbc in position 2: invalid start byte
尝试过改encoding="gbk",encoding="utf-8"或者GB2312、gbk、ISO-8859-1的方法,有时候能够起效果,有时候不行
介绍一种最有效的方法:
1.找到csv文件–>右键–>打开方式–>记事本
2.打开记事本之后,在右下角可以看到文件的默认编码格式为ANSI,选择头部菜单的“文件–>另存为”,
3.选择编码下拉框,选择需要的编码格式UTF-8,重新保存即可
4.使用 read_csv('./test.csv', encoding="utf-8") 即可
下面我遇到过错误可以尝试的解决办法如下(推荐使用上面的,下面的有时候也不行):
1. csvdata = pd.read_csv(file, keep_default_na=False, encoding="gbk")
报错:
UnicodeDecodeError: 'gbk' codec can't decode byte 0xb4 in position 8: illegal multibyte sequence
解决:将 encoding="gbk" 改为encoding="utf-8" 或者删掉
2. csvdata = pd.read_csv(file, keep_default_na=False)
报错:
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xbc in position 2: invalid start byte
解决:加上 encoding="gbk" 试试看
总结
加载全部内容