Synchronized锁升级
一无是处的研究僧 人气:0前言
在上篇文章深入学习Synchronized各种使用方法当中我们仔细介绍了在各种情况下该如何使用synchronized关键字。因为在我们写的程序当中可能会经常使用到synchronized关键字,因此JVM对synchronized做出了很多优化,而在本篇文章当中我们将仔细介绍JVM对synchronized的各种优化的细节。
工具准备
在正式谈synchronized的原理之前我们先谈一下自旋锁,因为在synchronized的优化当中自旋锁发挥了很大的作用。而需要了解自旋锁,我们首先需要了解什么是原子性。
所谓原子性简单说来就是一个一个操作要么不做要么全做,全做的意思就是在操作的过程当中不能够被中断,比如说对变量data进行加一操作,有以下三个步骤:
- 将
data从内存加载到寄存器。 - 将
data这个值加一。 - 将得到的结果写回内存。
原子性就表示一个线程在进行加一操作的时候,不能够被其他线程中断,只有这个线程执行完这三个过程的时候其他线程才能够操作数据data。
我们现在用代码体验一下,在Java当中我们可以使用AtomicInteger进行对整型数据的原子操作:
import java.util.concurrent.atomic.AtomicInteger;
public class AtomicDemo {
public static void main(String[] args) throws InterruptedException {
AtomicInteger data = new AtomicInteger();
data.set(0); // 将数据初始化位0
Thread t1 = new Thread(() -> {
for (int i = 0; i < 100000; i++) {
data.addAndGet(1); // 对数据 data 进行原子加1操作
}
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < 100000; i++) {
data.addAndGet(1);// 对数据 data 进行原子加1操作
}
});
// 启动两个线程
t1.start();
t2.start();
// 等待两个线程执行完成
t1.join();
t2.join();
// 打印最终的结果
System.out.println(data); // 200000
}
}从上面的代码分析可以知道,如果是一般的整型变量如果两个线程同时进行操作的时候,最终的结果是会小于200000。
我们现在来模拟一下一般的整型变量出现问题的过程:
主内存data的初始值等于0,两个线程得到的data初始值都等于0。
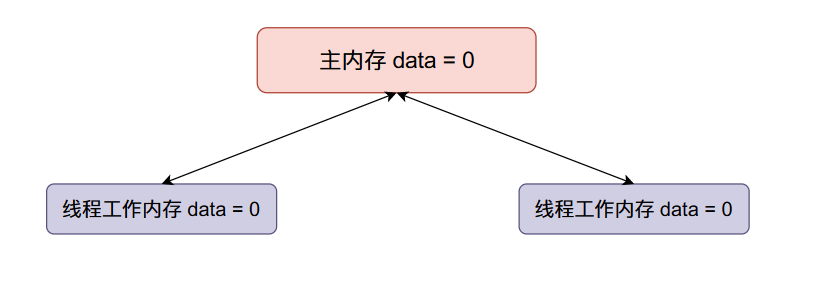
现在线程一将data加一,然后线程一将data的值同步回主内存,整个内存的数据变化如下:
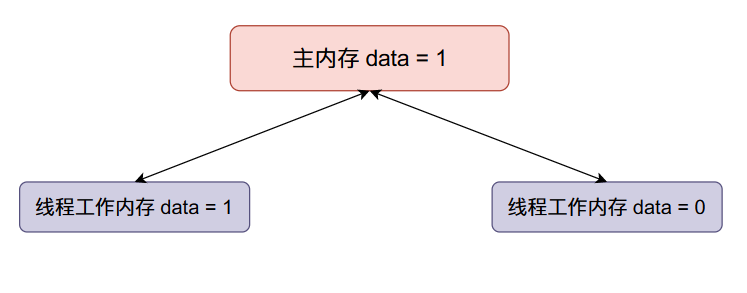
现在线程二data加一,然后将data的值同步回主内存(将原来主内存的值覆盖掉了):
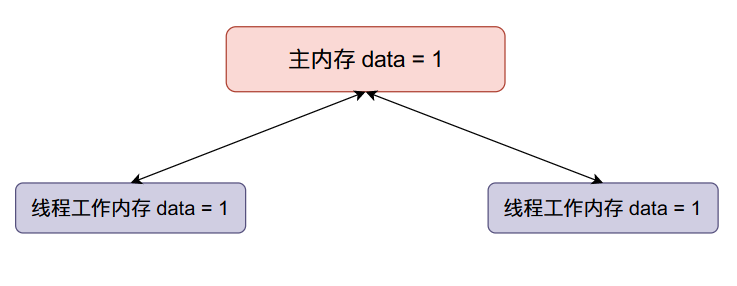
我们本来希望data的值在经过上面的变化之后变成2,但是线程二覆盖了我们的值,因此在多线程情况下,会使得我们最终的结果变小。
但是在上面的程序当中我们最终的输出结果是等于20000的,这是因为给data进行+1的操作是原子的不可分的,在操作的过程当中其他线程是不能对data进行操作的。这就是原子性带来的优势。
事实上上面的+1原子操作就是通过自旋锁实现的,我们可以看一下AtomicInteger的源代码:
public final int addAndGet(int delta) {
// 在 AtomicInteger 内部有一个整型数据 value 用于存储具体的数值的
// 这个 valueOffset 表示这个数据 value 在对象 this (也就是 AtomicInteger一个具体的对象)
// 当中的内存偏移地址
// delta 就是我们需要往 value 上加的值 在这里我们加上的是 1
return unsafe.getAndAddInt(this, valueOffset, delta) + delta;
}上面的代码最终是调用UnSafe类的方法进行实现的,我们再看一下他的源代码:
public final int getAndAddInt(Object o, long offset, int delta) {
int v;
do {
v = getIntVolatile(o, offset); // 从对象 o 偏移地址为 offset 的位置取出数据 value ,也就是前面提到的存储整型数据的变量
} while (!compareAndSwapInt(o, offset, v, v + delta));
return v;
}上面的代码主要流程是不断的从内存当中取对象内偏移地址为offset的数据,然后执行语句!compareAndSwapInt(o, offset, v, v + delta)
这条语句的主要作用是:比较对象o内存偏移地址为offset的数据是否等于v,如果等于v则将偏移地址为offset的数据设置为v + delta,如果这条语句执行成功返回 true否则返回false,这就是我们常说的Java当中的CAS。
看到这里你应该就发现了当上面的那条语句执行不成功的话就会一直进行while循环操作,直到操作成功之后才退出while循环,假如没有操作成功就会一直“旋”在这里,像这种操作就是自旋,通过这种自旋方式所构成的锁就叫做自旋锁。
对象的内存布局
在JVM当中,一个Java对象的内存主要有三块:
- 对象头,对象头包含两部分数据,分别是Mark word和类型指针(Kclass pointer)。
- 实例数据,就是我们在类当中定义的各种数据。
- 对齐填充,JVM在实现的时候要求每一个对象所占有的内存大小都需要是8字节的整数倍,如果一个对象的数据所占有的内存大小不够8字节的整数倍,那就需要进行填充,补齐到8字节,比如说如果一个对象站60字节,那么最终会填充到64字节。
而与我们要谈到的synchronized锁升级原理密切相关的是Mark word,这个字段主要是存储对象运行时的数据,比如说对象的Hashcode、GC的分代年龄、持有锁的线程等等。而Kclass pointer主要是用于指向对象的类,主要是表示这个对象是属于哪一个类,主要是寻找类的元数据。
在32位Java虚拟机当中Mark word有4个字节一共32个比特位,其内容如下:
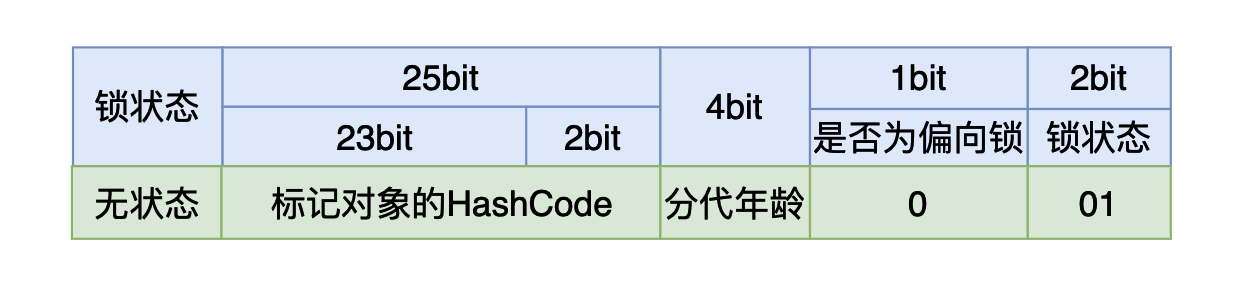
我们在使用synchronized时,如果我们是将synchronized用在同步代码块,我们需要一个锁对象。对于这个锁对象来说一开始还没有线程执行到同步代码块时,这个4个字节的内容如上图所示,其中有25个比特用来存储哈希值,4个比特用来存储垃圾回收的分代年龄(如果不了解可以跳过),剩下三个比特其中第一个用来表示当前的锁状态是否为偏向锁,最后的两个比特表示当前的锁是哪一种状态:
- 如果最后三个比特是:001,则说明锁状态是没有锁。
- 如果最后三个比特是:101,则说明锁状态是偏向锁。
- 如果最后两个比特是:00, 则说明锁状态是轻量级锁。
- 如果最后两个比特是:10, 则说明锁状态是重量级锁。
而synchronized锁升级的顺序是:无
加载全部内容