js强缓存协商缓存
Sunshine_Lin 人气:2背景
无论是开发中或者是面试中,HTTP缓存都是非常重要的,这体现在了两个方面:
- 开发中:合理利用HTTP缓存可以提高前端页面的性能
- 面试中:HTTP缓存是面试中的高频问点
所以本篇文章,我不讲废话,我就通过Nodejs的简单实践,给大家讲最通俗易懂的HTTP缓存,大家通过这篇文章一定能了解掌握它!!!
前置准备
准备
- 创建文件夹cache-study,并准备环境
npm init
- 安装Koa、nodemon
npm i koa -D npm i nodemon -g
- 创建index.js、index.html、static文件夹
- index.html
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Document</title> <link rel="stylesheet" href="./static/css/index.css" rel="external nofollow" > </head> <body> <div class="box"> </div> </body> </html>
- static/css/index.css
.box {
width: 500px;
height: 300px;
background-image: url('../image/guang.jpg');
background-size: 100% 100%;
color: #000;
}
- static/image/guang.jpg

- index.js
const Koa = require('koa')
const fs = require('fs')
const path = require('path')
const mimes = {
css: 'text/css',
less: 'text/css',
gif: 'image/gif',
html: 'text/html',
ico: 'image/x-icon',
jpeg: 'image/jpeg',
jpg: 'image/jpeg',
js: 'text/javascript',
json: 'application/json',
pdf: 'application/pdf',
png: 'image/png',
svg: 'image/svg+xml',
swf: 'application/x-shockwave-flash',
tiff: 'image/tiff',
txt: 'text/plain',
wav: 'audio/x-wav',
wma: 'audio/x-ms-wma',
wmv: 'video/x-ms-wmv',
xml: 'text/xml',
}
// 获取文件的类型
function parseMime(url) {
// path.extname获取路径中文件的后缀名
let extName = path.extname(url)
extName = extName ? extName.slice(1) : 'unknown'
return mimes[extName]
}
// 将文件转成传输所需格式
const parseStatic = (dir) => {
return new Promise((resolve) => {
resolve(fs.readFileSync(dir), 'binary')
})
}
const app = new Koa()
app.use(async (ctx) => {
const url = ctx.request.url
if (url === '/') {
// 访问根路径返回index.html
ctx.set('Content-Type', 'text/html')
ctx.body = await parseStatic('./index.html')
} else {
const filePath = path.resolve(__dirname, `.${url}`)
// 设置类型
ctx.set('Content-Type', parseMime(url))
// 设置传输
ctx.body = await parseStatic(filePath)
}
})
app.listen(9898, () => {
console.log('start at port 9898')
})
启动页面
现在你可以在终端中输入nodemon index,看到下方的显示,则代表成功启动了服务

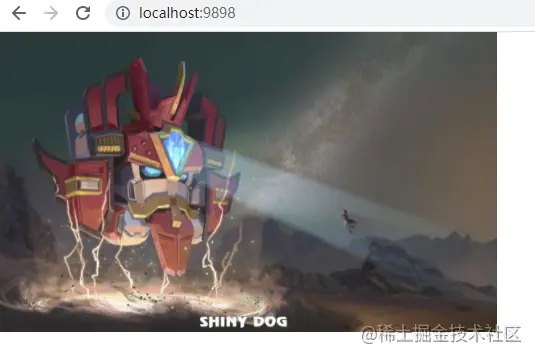
此时你可以在浏览器链接里输入http://localhost:9898/,打开看到如下页面,则代表页面访问成功!!!
HTTP缓存种类
HTTP缓存常见的有两类:
强缓存:可以由这两个字段其中一个决定
- expires
- cache-control(优先级更高)
协商缓存:可以由这两对字段中的一对决定
Last-Modified,If-Modified-Since
Etag,If-None-Match(优先级更高)
强缓存
接下来我们就开始讲强缓存
expires
我们只需设置响应头里expires的时间为当前时间 + 30s就行了
app.use(async (ctx) => {
const url = ctx.request.url
if (url === '/') {
// 访问根路径返回index.html
ctx.set('Content-Type', 'text/html')
ctx.body = await parseStatic('./index.html')
} else {
const filePath = path.resolve(__dirname, `.${url}`)
// 设置类型
ctx.set('Content-Type', parseMime(url))
// 设置 Expires 响应头
const time = new Date(Date.now() + 30000).toUTCString()
ctx.set('Expires', time)
// 设置传输
ctx.body = await parseStatic(filePath)
}
})
然后我们在前端页面刷新,我们可以看到请求的资源的响应头里多了一个expires的字段
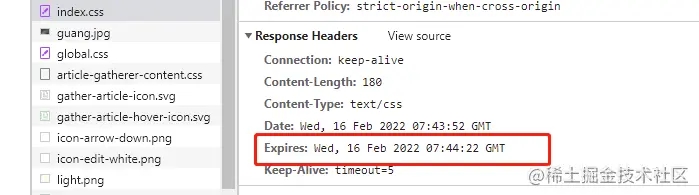
并且,在30s内,我们刷新之后,看到请求都是走memory,这意味着,通过expires设置强缓存的时效是30s,这30s之内,资源都会走本地缓存,而不会重新请求

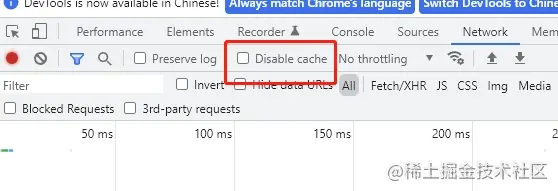
注意点:有时候你Nodejs代码更新了时效时间,但是发现前端页面还是在走上一次代码的时效,这个时候,你可以把这个Disabled cache打钩,然后刷新一下,再取消打钩
cache-control
其实cache-control跟expires效果差不多,只不过这两个字段设置的值不一样而已,前者设置的是秒数,后者设置的是毫秒数
app.use(async (ctx) => {
const url = ctx.request.url
if (url === '/') {
// 访问根路径返回index.html
ctx.set('Content-Type', 'text/html')
ctx.body = await parseStatic('./index.html')
} else {
const filePath = path.resolve(__dirname, `.${url}`)
// 设置类型
ctx.set('Content-Type', parseMime(url))
// 设置 Cache-Control 响应头
ctx.set('Cache-Control', 'max-age=30')
// 设置传输
ctx.body = await parseStatic(filePath)
}
})
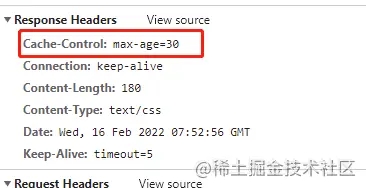
前端页面响应头多了cache-control这个字段,且30s内都走本地缓存,不会去请求服务端
协商缓存
与强缓存不同的是,强缓存是在时效时间内,不走服务端,只走本地缓存;而协商缓存是要走服务端的,如果请求某个资源,去请求服务端时,发现命中缓存则返回304,否则则返回所请求的资源,那怎么才算命中缓存呢?接下来讲讲
Last-Modified,If-Modified-Since
简单来说就是:
- 第一次请求资源时,服务端会把所请求的资源的最后一次修改时间当成响应头中Last-Modified的值发到浏览器并在浏览器存起来
- 第二次请求资源时,浏览器会把刚刚存储的时间当成请求头中If-Modified-Since的值,传到服务端,服务端拿到这个时间跟所请求的资源的最后修改时间进行比对
- 比对结果如果两个时间相同,则说明此资源没修改过,那就是命中缓存,那就返回304,如果不相同,则说明此资源修改过了,则没命中缓存,则返回修改过后的新资源
// 获取文件信息
const getFileStat = (path) => {
return new Promise((resolve) => {
fs.stat(path, (_, stat) => {
resolve(stat)
})
})
}
app.use(async (ctx) => {
const url = ctx.request.url
if (url === '/') {
// 访问根路径返回index.html
ctx.set('Content-Type', 'text/html')
ctx.body = await parseStatic('./index.html')
} else {
const filePath = path.resolve(__dirname, `.${url}`)
const ifModifiedSince = ctx.request.header['if-modified-since']
const fileStat = await getFileStat(filePath)
console.log(new Date(fileStat.mtime).getTime())
ctx.set('Cache-Control', 'no-cache')
ctx.set('Content-Type', parseMime(url))
// 比对时间,mtime为文件最后修改时间
if (ifModifiedSince === fileStat.mtime.toGMTString()) {
ctx.status = 304
} else {
ctx.set('Last-Modified', fileStat.mtime.toGMTString())
ctx.body = await parseStatic(filePath)
}
}
})
第一次请求时,响应头中:
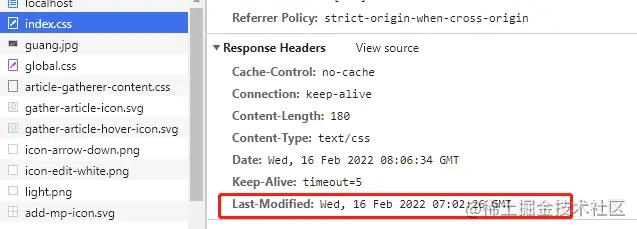
第二次请求时,请求头中:
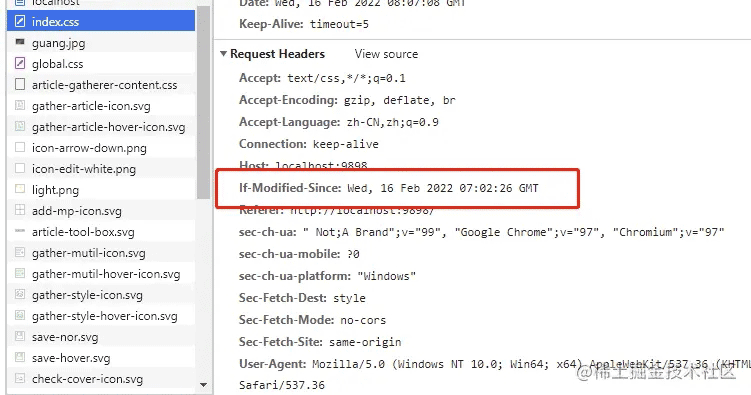
由于资源并没修改,则命中缓存,返回304:

此时我们修改一下index.css
.box {
width: 500px;
height: 300px;
background-image: url('../image/guang.jpg');
background-size: 100% 100%;
/* 修改这里 */
color: #333;
}
然后我们刷新一下页面,index.css变了,所以会没命中缓存,返回200和新资源,而guang.jpg并没有修改,则命中缓存返回304:

Etag,If-None-Match
其实Etag,If-None-Match跟Last-Modified,If-Modified-Since大体一样,区别在于:
- 后者是对比资源最后一次修改时间,来确定资源是否修改了
- 前者是对比资源内容,来确定资源是否修改
那我们要怎么比对资源内容呢?我们只需要读取资源内容,转成hash值,前后进行比对就行了!!
const crypto = require('crypto')
app.use(async (ctx) => {
const url = ctx.request.url
if (url === '/') {
// 访问根路径返回index.html
ctx.set('Content-Type', 'text/html')
ctx.body = await parseStatic('./index.html')
} else {
const filePath = path.resolve(__dirname, `.${url}`)
const fileBuffer = await parseStatic(filePath)
const ifNoneMatch = ctx.request.header['if-none-match']
// 生产内容hash值
const hash = crypto.createHash('md5')
hash.update(fileBuffer)
const etag = `"${hash.digest('hex')}"`
ctx.set('Cache-Control', 'no-cache')
ctx.set('Content-Type', parseMime(url))
// 对比hash值
if (ifNoneMatch === etag) {
ctx.status = 304
} else {
ctx.set('etag', etag)
ctx.body = fileBuffer
}
}
})
验证方式跟刚刚Last-Modified,If-Modified-Since的一样,这里就不重复说明了。。。
总结
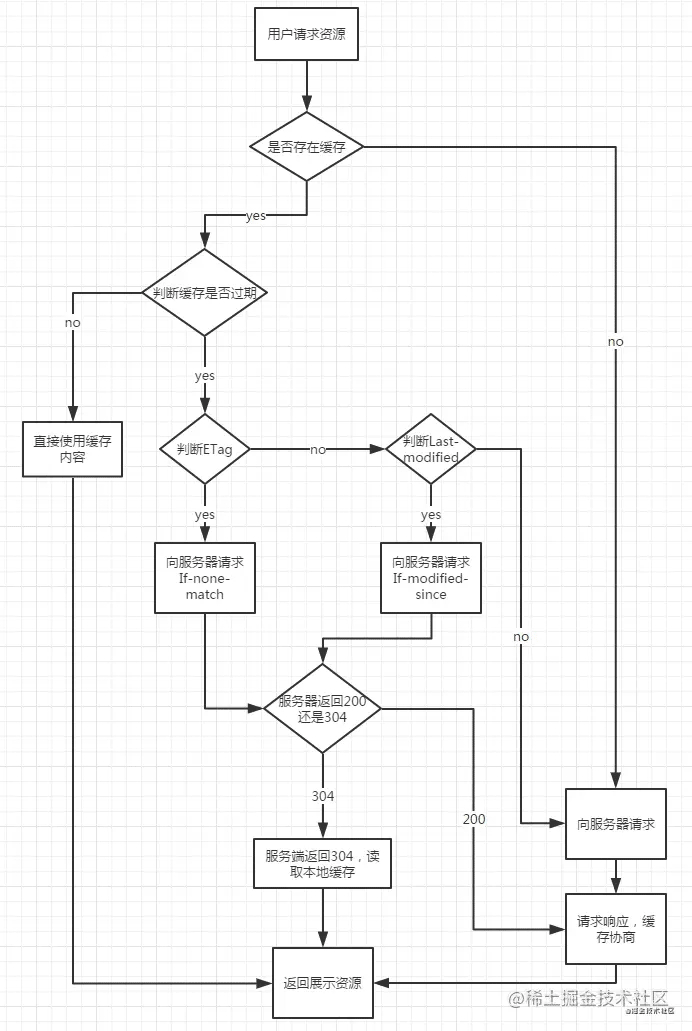
参考 https:
加载全部内容