Spring循环依赖
码农参上 人气:0前言
上篇文章中我们分析完了Spring中Bean的实例化过程,但是没有对循环依赖的问题进行分析,这篇文章中我们来看一下spring是如何解决循环依赖的实现。
之前在讲spring的过程中,我们提到了一个spring的单例池singletonObjects,用于存放创建好的bean,也提到过这个Map也可以说是狭义上的spring容器。
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<String, Object>(256);
其实spring在缓存bean的过程中并不是只有这一个Map,我们看一下DefaultSingletonBeanRegistry这个类,在其中其实存在3个Map,这也就是经常提到的spring三级缓存。
/** Cache of singleton objects: bean name --> bean instance */ private final Map<String, Object> singletonObjects = new ConcurrentHashMap<String, Object>(256); /** Cache of early singleton objects: bean name --> bean instance */ private final Map<String, Object> earlySingletonObjects = new HashMap<String, Object>(16); /** Cache of singleton factories: bean name --> ObjectFactory */ private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<String, ObjectFactory<?>>(16);
从上到下分别为一到三级缓存,这里先对三级缓存有一个初步的认识,后面使用到的时候我们再详细分析。
循环依赖实现流程
下面开始分析spring循环依赖的注入实现过程。先写两个bean,在它们中分别注入了对方:
@Component
public class ServiceA {
@Autowired
ServiceB serviceB;
public ServiceB getServiceB() {
System.out.println("get ServiceB");
return serviceB;
}
}@Component
public class ServiceB {
@Autowired
ServiceA serviceA;
public ServiceA getServiceA() {
return serviceA;
}
}进行测试,分别调用它们的get方法,能够正常获得bean,说明循环依赖是可以实现的:
com.hydra.service.ServiceB@58fdd99 com.hydra.service.ServiceA@6b1274d2
首先,回顾一下上篇文章中讲过的bean实例化的流程。下面的内容较多依赖于spring的bean实例化源码,如果不熟悉建议花点时间阅读一下上篇文章。
在AbstractAutowireCapableBeanFactory的doCreateBean方法中,调用createBeanInstance方法创建一个原生对象,之后调用populateBean方法执行属性的填充,最后调用各种回调方法和后置处理器。
但是在执行populateBean方法前,上篇文章中省略了一些涉及到循环依赖的内容,看一下下面这段代码:
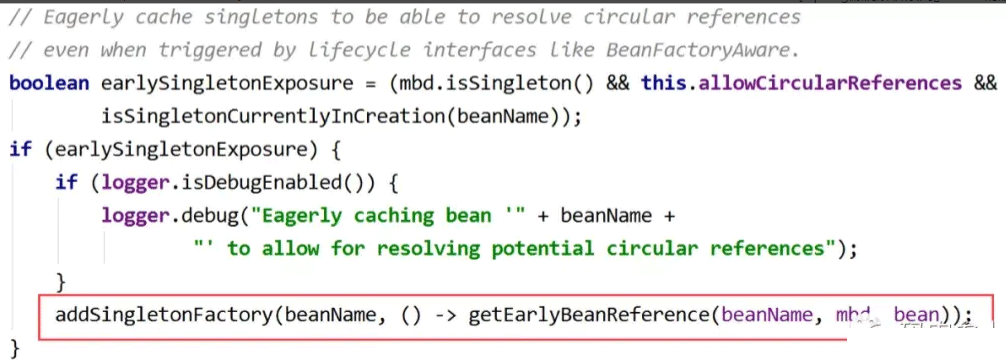
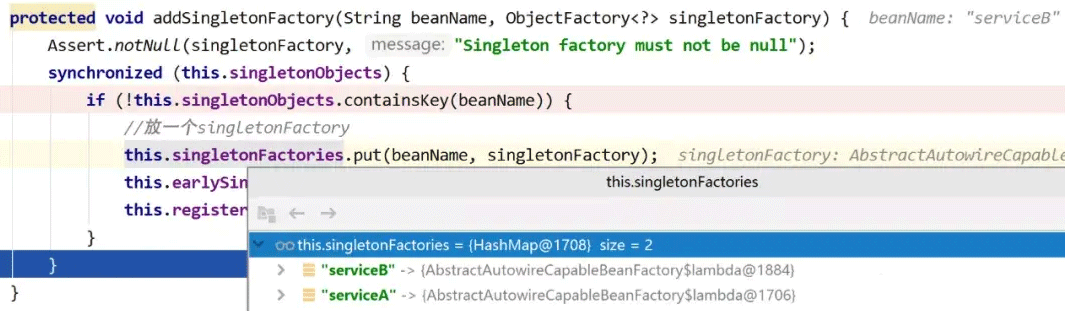
上面的代码先进行判断:如果当前创建的是单例bean,并且允许循环依赖,并且处于创建过程中,那么执行下面的addSingletonFactory方法。
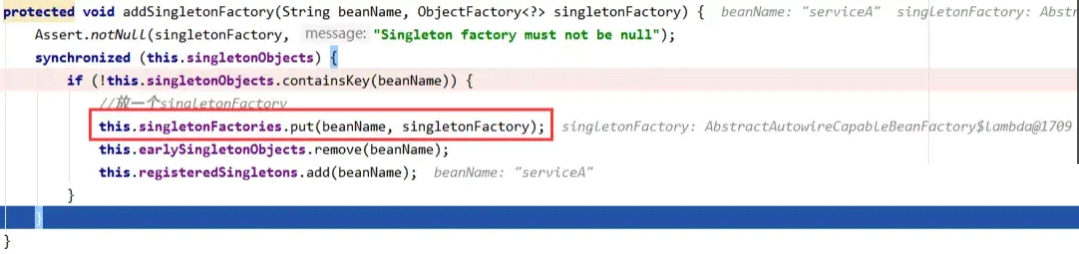
主要工作为将lambda表达式代表的ObjectFactory,放入三级缓存的Map中。注意这里只是一个存放的操作,并没有实际执行lambda表达式中的内容,具体调用过程是在后面调用ObjectFactory的getObject方法时调用。这个方法执行完成后,三级缓存中存放了一条serviceA的数据,二级缓存仍然为空。
回到正常调用流程,生成原生对象后,调用populateBean方法进行属性的赋值也就是依赖注入,具体是通过执行AutowiredAnnotationBeanPostProcessor这一后置处理器的postProcessPropertyValues方法。
在这一过程中,serviceA会找到它依赖的serviceB这一属性,当发现依赖后,会调用DefaultListableBeanFactory的doResolveDependency方法,之后执行resolveCandidate方法,在该方法中,尝试使用beanFactory获取到serviceB的bean实例。
public Object resolveCandidate(String beanName, Class<?> requiredType, BeanFactory beanFactory)
throws BeansException {
return beanFactory.getBean(beanName);
}
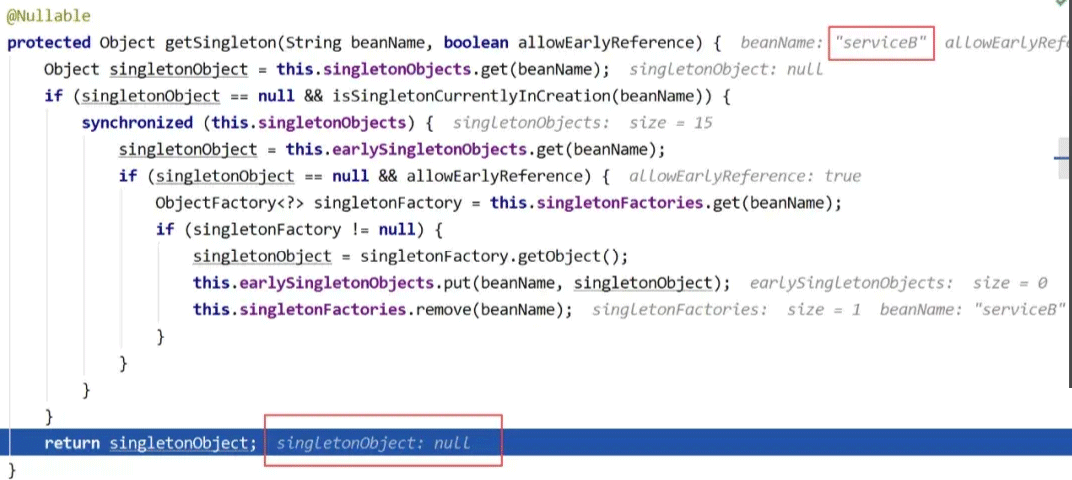
这时和之前没有循环依赖时的情况就会有些不一样了,因为现在serviceB还没有被创建出来,所以通过beanFactory是无法直接获取的。因此当在doGetBean方法中调用getSingleton方法会返回一个null值:
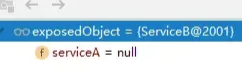
因此,继续使用与之前相同的创建bean的流程,实例化serviceB的bean对象。当serviceB的原生对象被实例化完成后,同样可以看到它依赖的serviceA还没有被赋值:
创建完serviceB的原生对象后,同样执行addSingletonFactory方法,将serviceB放入三级缓存中,执行完成后,三级缓存中就已经存在了两个bean的缓存:
向下执行,serviceB会调用populateBean方法进行属性填充。和之前serviceA依赖serviceB相同的调用链,执行到resolveCandidate方法,尝试使用beanFactory的getBean去获取serviceA。

向下执行,调用getSingleton方法尝试直接获取serviceA,此时三级缓存singletonFactories中我们之前已经存进去了一个key为serviceA的beanName,value为lambda表达式,这时可以直接获取到。
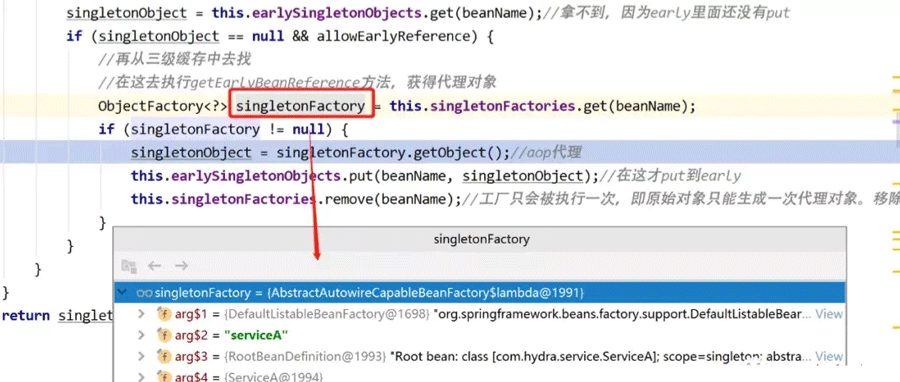
在执行singletonFactory的getObject方法时才去真正执行lambda表达式中的方法,实际执行的是getEarlyBeanReference方法:
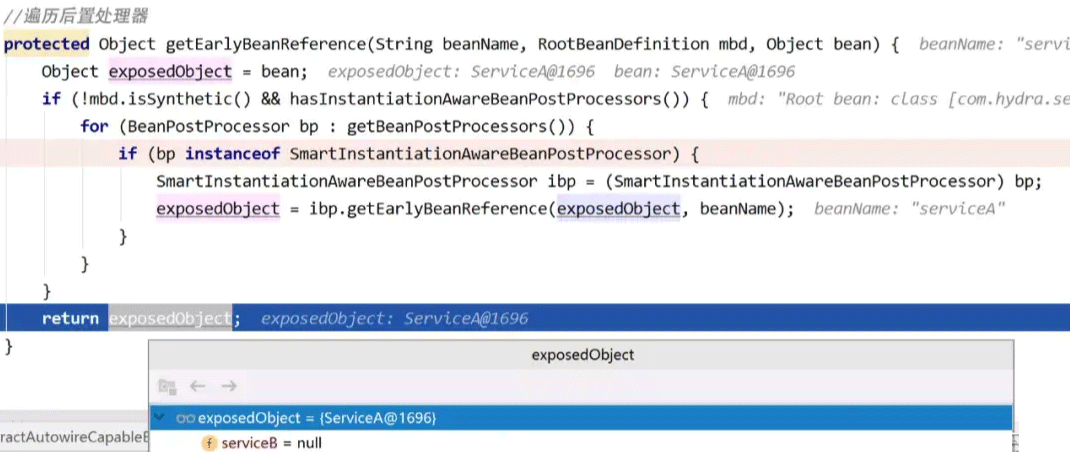
在遍历后置处理器后,获取到serviceA的执行过后置处理器后的对象,执行:
this.earlySingletonObjects.put(beanName, singletonObject); this.singletonFactories.remove(beanName);
这里将serviceA放入二级缓存earlySingletonObjects,并从三级缓存singletonFactories中移除。在这一步执行完后,三级缓存中的serviceA就没有了。
当我们从缓存中获取了serviceA的bean后,就不会再调用createBean去重复创建新的bean了。之后,顺调用链返回serviceB调用的doResolveDependency方法:
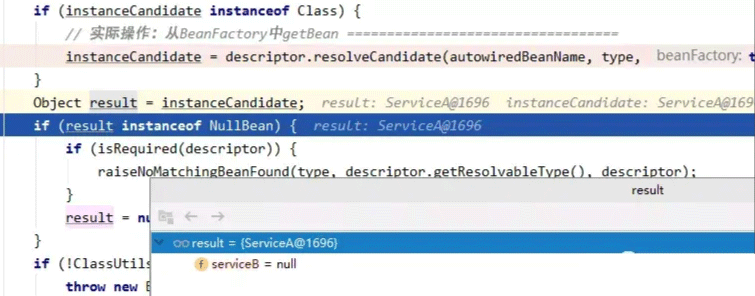
serviceB就成功获取到了它的依赖的serviceA属性的bean对象,回到inject方法,使用反射给serviceA赋值成功。
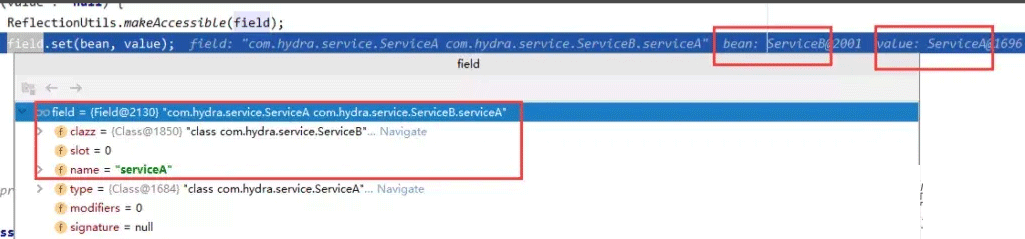
回到doCreateBean的方法,可以看到serviceB的serviceA属性已经被注入了,但是serviceA中的serviceB属性还是null。说明serviceB的依赖注入已经完成,而serviceA的依赖注入还没做完。
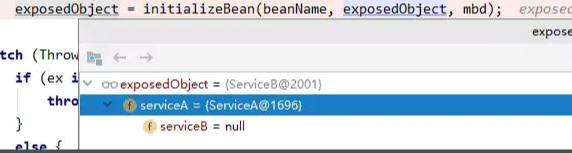
现在我们梳理一下运行到这里的流程:
1、在serviceA填充属性过程中发现依赖了serviceB,通过beanFactory的getBean方法,尝试获取serviceB
2、serviceB不存在,执行了一遍serviceB的创建流程,填充属性时发现serviceA已经存在于三级缓存,直接注入给serviceB
可以看到,在创建serviceA的过程中发现依赖的serviceB不存在,转而去创建了serviceB,而创建serviceA的流程并没有执行完,因此在创建完serviceB后再顺调用链返回,直到doResolveDependency方法:
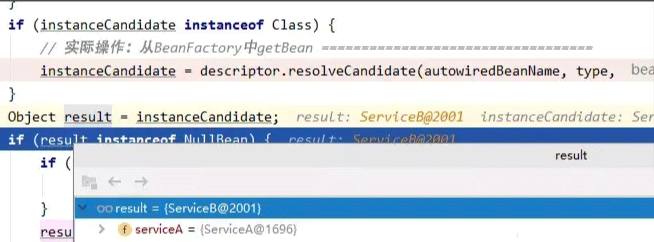
可以看到,需要依赖的serviceB已经被创建并返回成功,返回到inject方法,同样通过反射给serviceB赋值:

返回doCreateBean方法,可以看到serviceA和serviceB之间的循环依赖已经完成了:
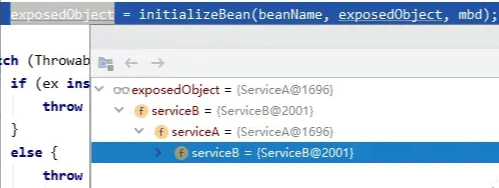
这样,一个最简单的循环依赖流程就结束了。有的小伙伴可能会提出疑问,这样的话,我只需要添加一个缓存存放原生对象就够了啊,为什么还需要二级缓存和三级缓存两层结构呢?这个问题,我们放在下一篇具体讨论,看看循环依赖的具体实现时怎样的。
加载全部内容