pd.read_csv读取文件路径
RDSunday 人气:7写在前面
在用pd.read_csv读取数据集时,我有2个疑问?1是:写相对路径还是绝对路径。2是:相对路径,绝对路径怎么写。这篇文章就是解决以上两个问题。如果这个脚本只是在自己电脑上,都可以无所谓,但是如果别人也想用你的脚本,我认为相对路径还是比较好的,数据集和脚本一起拷贝给别人,如果环境没问题的话路径不用修改就可以直接运行,如果你用绝对路径的话,别人拿到之后还得自己修改路径。
出现的问题
报错,这个路径没找到文件,路径写错了。

解决问题
一般是数据集与你的脚本在一个文件夹下。 我用的是绝对路径
第1步打印脚本所在的路径
import os os.getcwd() print(os.getcwd())

第2步
加上你的数据集路径
train = pd.read_csv('F:\\pythonProject3\\data\\data\\train.csv')下面是我的脚本和数据集的文件。
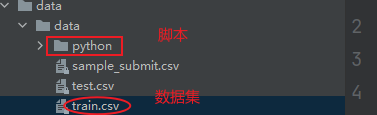
第3步测试一下
print(train)
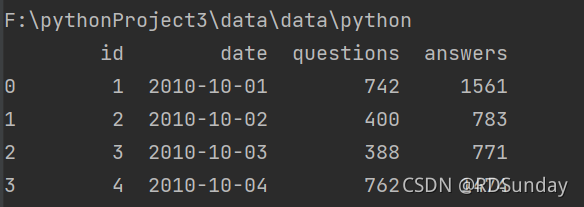
用相对路径读取数据集
前提数据集与脚本不在同一个文件下,但同在上一级文件夹。就是下面这种情况。
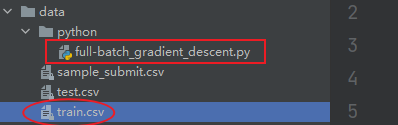
读取文件方式
train = pd.read_csv('..\\train.csv')图中的“..”表示是当前所处的文件夹上一级文件夹的绝对路径。也就是我下图中data路径
F:\pythonProject3\data\data
实在不理解可以自己试试
import os
path1=os.path.abspath('.') #表示当前所处的文件夹的绝对路径
print("path1@@@@@",path1)
path2=os.path.abspath('..') ## 表示当前所处的文件夹上一级文件夹的绝对路径
print("path2@@@@@",path2)
完整的代码
import pandas as pd
import numpy as np
import os
os.getcwd()
# F:\\pythonProject3\\data\\data\\train.csv
# dataset_path = '..'
train = pd.read_csv('..\\train.csv')
path1=os.path.abspath('.')
print("path1@@@@@",path1)
path2=os.path.abspath('..')
print("path2@@@@@",path2)
print(train)
参考
加载全部内容