Scrapy 中间件Middleware
zombres 人气:0Scrapy 结构概述:
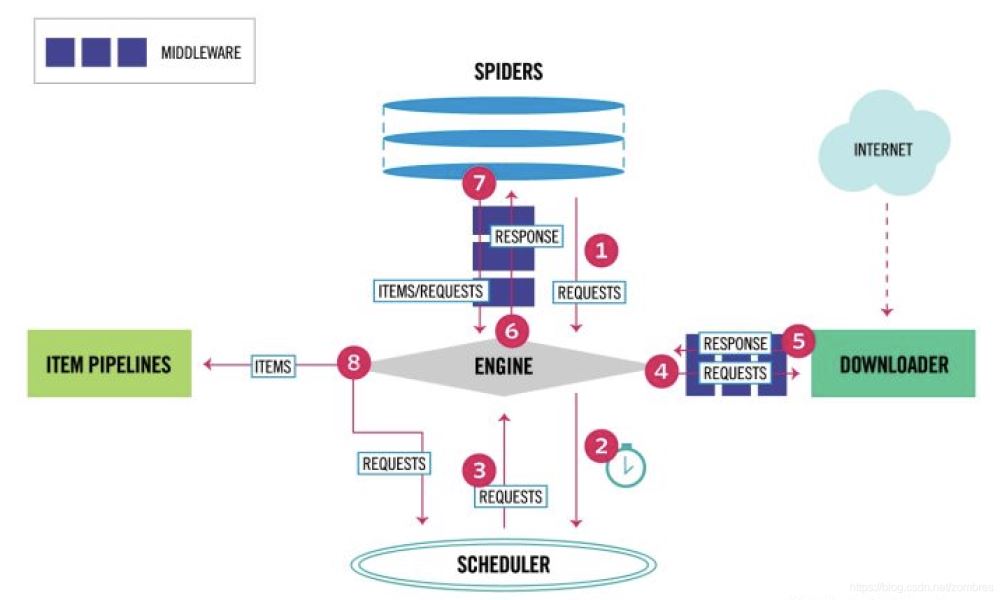
一、下载器中间件(Downloader Middleware)
如上图标号4、5处所示,下载器中间件用于处理scrapy的request和response的钩子框架,如在request中设置代理ip,header等,检测response的HTTP响应码等。
scrapy已经自带来一堆下载器中间件。
{
'scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware': 100,
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware': 300,
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware': 350,
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware': 400,
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': 500,
'scrapy.downloadermiddlewares.retry.RetryMiddleware': 550,
'scrapy.downloadermiddlewares.ajaxcrawl.AjaxCrawlMiddleware': 560,
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware': 580,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 590,
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware': 600,
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware': 700,
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': 750,
'scrapy.downloadermiddlewares.stats.DownloaderStats': 850,
'scrapy.downloadermiddlewares.httpcache.HttpCacheMiddleware': 900,
}
上面就是默认启用的下载器中间件,其各个中间件的作用参考一下官方文档:Scrapy download-middleware
自定义下载器中间件
有时我们需要编写自己的一些下载器中间件,如使用代理池,随机更换user-agent等,要使用自定义的下载器中间件,就需要在setting文件中激活我们自己的实现类,如下:
DOWNLOADERMIDDLEWARES = {
'myproject.middlewares.Custom_A_DownloaderMiddleware': 543,
'myproject.middlewares.Custom_B_DownloaderMiddleware': 643,
'myproject.middlewares.Custom_B_DownloaderMiddleware': None,
}
设置值是个DICT,key是我们自定义的类路径,后面数字是执行顺序,数字越小,越靠近引擎,数字越大越靠近下载器,所以数字越小的,processrequest()优先处理;数字越大的,process_response()优先处理;若需要关闭某个中间件直接设为None即可。
(PS. 如果两个下载器的没有强制的前后关系,数字大小没什么影响)
实现下载器我们需要重写以下几个方法:
- 对于请求的中间件实现 process_request(request, spider);
- 对于处理回复中间件实现process_response(request, response, spider);
- 以及异常处理实现 process_exception(request, exception, spider)
process_request(request, spider)
process_request:可以选择返回None、Response、Request、raise IgnoreRequest其中之一。
- 如果返回None,scrapy将继续处理该request,执行其他的中间件的响应方法。直到合适的下载器处理函数(downloader handler)被调用,该request被执行,其response被下载。
- 如果其返回Response对象,Scrapy将不会调用任何其他的process_request()或process_exception()方法,或相应地下载函数; 其将返回该response。已安装的中间件的process_response()方法则会在每个response返回时被调用
- 如果其返回Request对象,Scrapy则停止调用process_request方法并重新调度返回的request。当新返回的request被执行后,相应地中间件链将会根据下载的response被调用。
- 如果其raise IgnoreRequest,则安装的下载中间件的process_exception()方法会被调用。如果没有任何一个方法处理该异常, 则request的errback(Request.errback)方法会被调用。如果没有代码处理抛出的异常, 则该异常被忽略且不记录(不同于其他异常那样)。
通常返回None较常见,它会继续执行爬虫下去
process_response(request, response, spider)
当下载器完成HTTP请求,传递响应给引擎的时候调用,它会返回 Response 、Request 、IgnoreRequest三种对象的一种
- 若返回Response对象,它会被下个中间件中的process_response()处理
- 若返回Request对象,中间链停止,然后返回的Request会被重新调度下载
- 抛出IgnoreRequest,回调函数 Request.errback将会被调用处理,若没处理,将会忽略
process_exception(request, exception, spider)
当下载处理器(download handler)或process_request()抛出异常(包括 IgnoreRequest 异常)时, Scrapy调用 process_exception() ,通常返回None,它会一直处理异常
from_crawler(cls, crawler)
这个类方法通常是访问settings和signals的入口函数
例如下面2个例子是更换user-agent和代理ip的下载中间件
# setting中设置
USER_AGENT_LIST = [ \
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1", \
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11", \
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6", \
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6", \
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1", \
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5", \
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5", \
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", \
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", \
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", \
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", \
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", \
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", \
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", \
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", \
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3", \
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24", \
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24", \
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.2357.132 Safari/537.36", \
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:41.0) Gecko/20100101 Firefox/41.0"
]
PROXIES = [
'1.85.220.195:8118',
'60.255.186.169:8888',
'118.187.58.34:53281',
'116.224.191.141:8118',
'120.27.5.62:9090',
'119.132.250.156:53281',
'139.129.166.68:3128'
]
代理ip中间件
import random
class Proxy_Middleware():
def __init__(self, crawler):
self.proxy_list = crawler.settings.PROXY_LIST
self.ua_list = crawler.settings.USER_AGENT_LIST
@classmethod
def from_crawler(cls, crawler):
return cls(crawler)
def process_request(self, request, spider):
try:
ua = random.choice(self.ua_list)
request.headers.setdefault('User-Agent', ua)
proxy_ip_port = random.choice(self.proxy_list)
request.meta['proxy'] = 'http://' + proxy_ip_port
except request.exceptions.RequestException:
spider.logger.error('some error happended!')
重试中间件
有时使用代理会被远程拒绝或超时等错误,这时我们需要换代理ip重试,重写scrapy.downloadermiddlewares.retry.RetryMiddleware
from scrapy.downloadermiddlewares.retry import RetryMiddleware
from scrapy.utils.response import response_status_message
class My_RetryMiddleware(RetryMiddleware):
def __init__(self, crawler):
self.proxy_list = crawler.settings.PROXY_LIST
self.ua_list = crawler.settings.USER_AGENT_LIST
@classmethod
def from_crawler(cls, crawler):
return cls(crawler)
def process_response(self, request, response, spider):
if request.meta.get('dont_retry', False):
return response
if response.status in self.retry_http_codes:
reason = response_status_message(response.status)
try:
ua = random.choice(self.ua_list)
request.headers.setdefault('User-Agent', ua)
proxy_ip_port = random.choice(self.proxy_list)
request.meta['proxy'] = 'http://' + proxy_ip_port
except request.exceptions.RequestException:
spider.logger.error('获取讯代理ip失败!')
return self._retry(request, reason, spider) or response
return response
# scrapy中对接selenium
from scrapy.http import HtmlResponse
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from gp.configs import *
class ChromeDownloaderMiddleware(object):
def __init__(self):
options = webdriver.ChromeOptions()
options.add_argument('--headless') # 设置无界面
if CHROME_PATH:
options.binary_location = CHROME_PATH
if CHROME_DRIVER_PATH: # 初始化Chrome驱动
self.driver = webdriver.Chrome(chrome_options=options, executable_path=CHROME_DRIVER_PATH)
else:
self.driver = webdriver.Chrome(chrome_options=options) # 初始化Chrome驱动
def __del__(self):
self.driver.close()
def process_request(self, request, spider):
try:
print('Chrome driver begin...')
self.driver.get(request.url) # 获取网页链接内容
return HtmlResponse(url=request.url, body=self.driver.page_source, request=request, encoding='utf-8',
status=200) # 返回HTML数据
except TimeoutException:
return HtmlResponse(url=request.url, request=request, encoding='utf-8', status=500)
finally:
print('Chrome driver end...')
二、Spider中间件(Spider Middleware)
如文章第一张图所示,spider中间件用于处理response及spider生成的item和Request
启动自定义spider中间件必须先开启settings中的设置
SPIDER_MIDDLEWARES = {
'myproject.middlewares.CustomSpiderMiddleware': 543,
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware': None,
}
同理,数字越小越靠近引擎,process_spider_input()优先处理,数字越大越靠近spider,process_spider_output()优先处理,关闭用None
编写自定义spider中间件
process_spider_input(response, spider)
当response通过spider中间件时,这个方法被调用,返回None
process_spider_output(response, result, spider)
当spider处理response后返回result时,这个方法被调用,必须返回Request或Item对象的可迭代对象,一般返回result
process_spider_exception(response, exception, spider)
当spider中间件抛出异常时,这个方法被调用,返回None或可迭代对象的Request、dict、Item
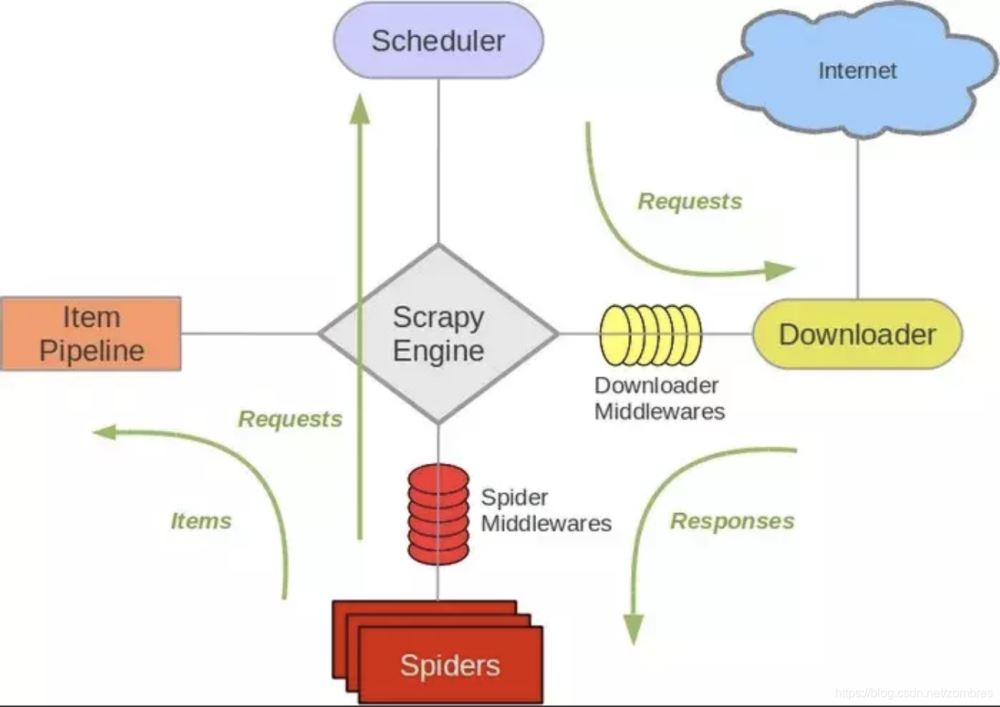
补充一张图:
参考文档:
https://docs.scrapy.org/en/latest/topics/spider-middleware.html
https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
加载全部内容