Python爬虫框架Scrapy
springsnow 人气:0在爬虫的路上,学习scrapy是一个必不可少的环节。也许有好多朋友此时此刻也正在接触并学习scrapy,那么很好,我们一起学习。开始接触scrapy的朋友可能会有些疑惑,毕竟是一个框架,上来不知从何学起。从本篇起,博主将开启scrapy学习的系列,分享如何快速入门scrapy并熟练使用它。
本篇作为第一篇,主要介绍和了解scrapy,在结尾会向大家推荐一本关于学习scrapy的书,以及获取的方式。
为什么要用爬虫框架?
如果你对爬虫的基础知识有了一定了解的话,那么是时候该了解一下爬虫框架了。那么为什么要使用爬虫框架?
- 学习框架的根本是学习一种编程思想,而不应该仅仅局限于是如何使用它。从了解到掌握一种框架,其实是对一种思想理解的过程。
- 框架也给我们的开发带来了极大的方便。许多条条框框都已经是写好了的,并不需要我们重复造轮子,我们只需要根据自己的需求定制自己要实现的功能就好了,大大减少了工作量。
- 参考并学习优秀的框架代码,提升编程代码能力。
博主当时是根据这几点来进行爬虫框架的学习的,但是切记核心目标是掌握一种框架思想,一种框架的能力,掌握了这种思想你才能更好的去使用它,甚至扩展它。
scrapy框架的介绍
比较流行的爬虫的框架有scrapy和pyspider,但是被大家所钟爱的我想非scrapy莫属了。scrapy是一个开源的高级爬虫框架,我们可以称它为"scrapy语言"。它使用python编写,用于爬取网页,提取结构性数据,并可将抓取得结构性数据较好的应用于数据分析和数据挖掘。scrapy有以下的一些特点:
- scrapy基于事件的机制,利用twisted的设计实现了非阻塞的异步操作。这相比于传统的阻塞式请求,极大的提高了CPU的使用率,以及爬取效率。
- 配置简单,可以简单的通过设置一行代码实现复杂功能。
- 可拓展,插件丰富,比如分布式scrapy + redis、爬虫可视化等插件。
- 解析方便易用,scrapy封装了xpath等解析器,提供了更方便更高级的selector构造器,可有效的处理破损的HTML代码和编码。
scrapy和requests+bs用哪个好?
有的朋友问了,为什么要使用scrapy,不使用不行吗?用resquests + beautifulsoup组合难道不能完成吗?
不用纠结,根据自己方便来。resquests + beautifulsoup当然可以了,requests + 任何解析器都行,都是非常好的组合。这样用的优点是我们可以灵活的写我们自己的代码,不必拘泥于固定模式。对于使用固定的框架有时候不一定用起来方便,比如scrapy对于反反爬的处理并没有很完善,好多时候也要自己来解决。
但是对于一些中小型的爬虫任务来讲,scrapy确实是非常好的选择,它避免了我们来写一些重复的代码,并且有着出色的性能。我们自己写代码的时候,比如为了提高爬取效率,每次都自己码多线程或异步等代码,大大浪费了开发时间。这时候使用已经写好的框架是再好不过的选择了,我们只要简单的写写解析规则和pipeline就好了。那么具体哪些是需要我们做的呢?看看下面这个图就明白了。
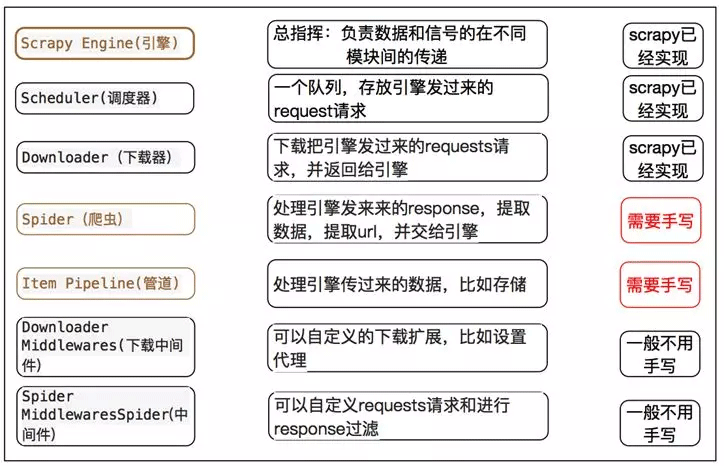
因此,对于该用哪个,根据个人需求和喜好决定。但是至于学习的先后顺序,建议先学学resquests + beautifulsoup,然后再接触Scrapy效果可能会更好些,仅供参考。
scrapy的架构
在学习Scrapy之前,我们需要了解Scrapy的架构,明白这个架构对学习scrapy至关重要。
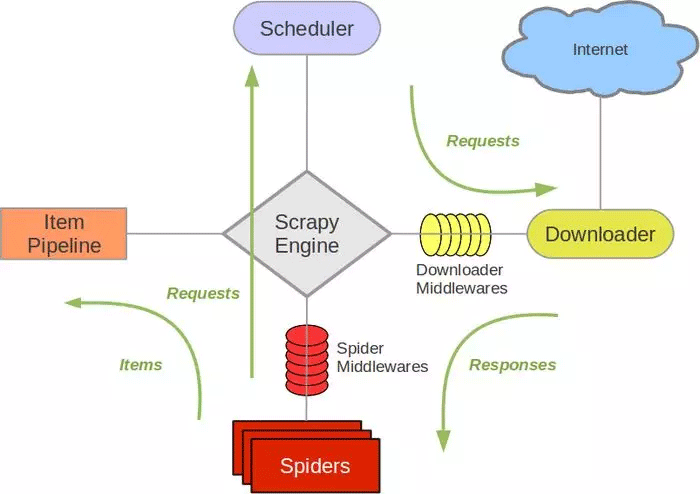
Scrapy官方文档的图片
下面的描述引自官方doc文档(在此引用),讲的很清楚明白,对照这个图看就能明白。
组件
Scrapy Engine
引擎负责控制数据流在系统中所有组件中流动,并在相应动作发生时触发事件。 详细内容查看下面的数据流(Data Flow)部分。
调度器(Scheduler)
调度器从引擎接受request并将他们入队,以便之后引擎请求他们时提供给引擎。
下载器(Downloader)
下载器负责获取页面数据并提供给引擎,而后提供给spider。
Spiders
Spider是Scrapy用户编写用于分析response并提取item(即获取到的item)或额外跟进的URL的类。 每个spider负责处理一个特定(或一些)网站。
Item Pipeline
Item Pipeline负责处理被spider提取出来的item。典型的处理有清理、 验证及持久化(例如存取到数据库中)。
下载器中间件(Downloader middlewares)
下载器中间件是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的response。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。
Spider中间件(Spider middlewares)
Spider中间件是在引擎及Spider之间的特定钩子(specific hook),处理spider的输入(response)和输出(items及requests)。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。
数据流过程
- 引擎打开一个网站(open a domain),找到处理该网站的Spider并向该spider请求第一个要爬取的URL(s)。
- 引擎从Spider中获取到第一个要爬取的URL并在调度器(Scheduler)以Request调度。
- 引擎向调度器请求下一个要爬取的URL。
- 调度器返回下一个要爬取的URL给引擎,引擎将URL通过下载中间件(请求(request)方向)转发给下载器(Downloader)。
- 一旦页面下载完毕,下载器生成一个该页面的Response,并将其通过下载中间件(返回(response)方向)发送给引擎。
- 引擎从下载器中接收到Response并通过Spider中间件(输入方向)发送给Spider处理。
- Spider处理Response并返回爬取到的Item及(跟进的)新的Request给引擎。
- 引擎将(Spider返回的)爬取到的Item给Item Pipeline,将(Spider返回的)Request给调度器。
- (从第二步)重复直到调度器中没有更多地request,引擎关闭该网站。
到此这篇关于Python爬虫框架Scrapy的文章就介绍到这了。希望对大家的学习有所帮助,也希望大家多多支持。
加载全部内容