elasticsearch索引index Translog数据功能
zziawan 人气:0translog的结构及写入方式
跟大多数分布式系统一样,es也通过临时写入写操作来保证数据安全。因为lucene索引过程中,数据会首先据缓存在内存中直到达到一个量(文档数或是占用空间大小)才会写入到磁盘。这就会带来一个风险,如果在写入磁盘前系统崩溃,那么这些缓存数据就会丢失。es通过translog解决了这个问题,每次写操作都会写入一个临时文件translog中,这样如果系统需要恢复数据可以从translog中读取。本篇就主要分析translog的结构及写入方式。
这一部分主要包括两部分translog和tanslogFile,前者对外提供了对translogFile操作的相关接口,后者则是具体的translogFile,它是具体的文件。
translogFile的继承关系
如下图所示:
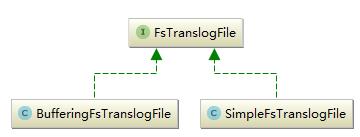
实现了两种translogFile,它们的最大区别如名字所示就是写入时是否缓存。FsTranslogFile的接口如下所示:
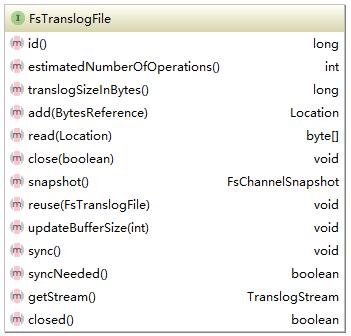
每一个translogFile都会有一个唯一Id,两个非常重要的方法add和write。add是添加对应的操作,这些操作都是在translog中定义,这里写入的只是byte类型的文件,不关注是何种操作。所有的操作都是顺序写入,因此读取的时候需要一个位置信息。add方法代码如下所示:
public Translog.Location add(BytesReference data) throws IOException {
rwl.writeLock().lock();//获取读写锁,每个文件的写入都是顺序的。
try {
operationCounter++;
long position = lastPosition;
if (data.length() >= buffer.length) {
flushBuffer();
// we use the channel to write, since on windows, writing to the RAF might not be reflected
// when reading through the channel
data.writeTo(raf.channel());//写入数据
lastWrittenPosition += data.length();
lastPosition += data.length();//记录位置
return new Translog.Location(id, position, data.length());//返回由id,位置及长度确定的操作位置信息。
}
if (data.length() > buffer.length - bufferCount) {
flushBuffer();
}
data.writeTo(bufferOs);
lastPosition += data.length();
return new Translog.Location(id, position, data.length());
} finally {
rwl.writeLock().unlock();
}
}这是SimpleTranslogFile写入操作,BufferedTransLogFile写入逻辑基本相同,只是它不会立刻写入到硬盘,先进行缓存。
TranslogFile快照的方法
另外TranslogFile还提供了一个快照的方法,该方法返回一个FileChannelSnapshot,可以通过它next方法将translogFile中所有的操作都读出来,写入到一个shapshot文件中。代码如下:
public FsChannelSnapshot snapshot() throws TranslogException {
if (raf.increaseRefCount()) {
boolean success = false;
try {
rwl.writeLock().lock();
try {
FsChannelSnapshot snapshot = new FsChannelSnapshot(this.id, raf, lastWrittenPosition, operationCounter);
snapshot.seekTo(this.headsuccess = true;
returnerSize);
snapshot;
} finally {
rwl.writeLock().unlock();
}
} catch (FileNotFoundException e) {
throw new TranslogException(shardId, "failed to create snapshot", e);
} finally {
if (!success) {
raf.decreaseRefCount(false);
}
}
}
return null;
}TransLogFile是具体文件的抽象,它只是负责写入和读取,并不关心读取和写入的操作类型。各种操作的定义及对TransLogFile的定义到在Translog中。它的接口如下所示:
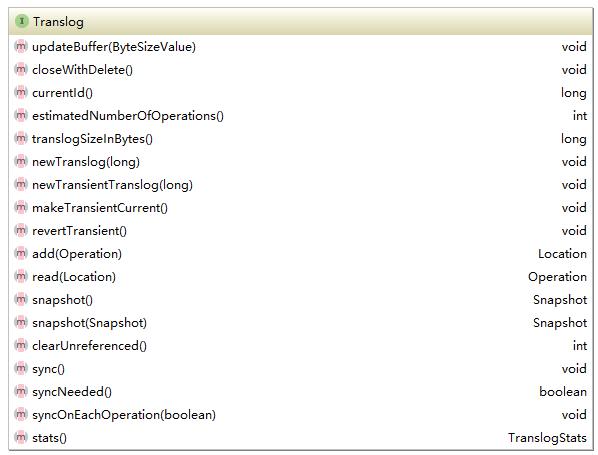
这里的写入(add)就是一个具体的操作,这是一个外部调用接口,索引、删除等修改索引的操作都会构造一个对应的Operation在对索引进行相关操作的同时调用该方法。这里还要着重说明一下makeTransientCurrent方法。操作的写入时刻进行,但是根据配置TransLogFile超过限度时需要删除重新开始一个新的文件。因此在transLog中存在两个TransLogFile,current和transient。当需要更换时需要通过读写锁确保单线程操作,将current切换到transient上来,然后删除之前的current。代码如下所示:
public void revertTransient() {
FsTranslogFile tmpTransient;
rwl.writeLock().lock();
try {
tmpTransient = trans;//交换
this.trans = null;
} finally {
rwl.writeLock().unlock();
}
logger.trace("revert transient {}", tmpTransient);
// previous transient might be null because it was failed on its creation
// for example
if (tmpTransient != null) {
tmpTransient.close(true);
}
}translog中定义了index,create,delete及deletebyquery四种操作它们都继承自Operation。这四种操作也是四种能够改变索引数据的操作。operation代码如下所示:
static interface Operation extends Streamable {
static enum Type {
CREATE((byte) 1),
SAVE((byte) 2),
DELETE((byte) 3),
DELETE_BY_QUERY((byte) 4);
private final byte id;
private Type(byte id) {
this.id = id;
}
public byte id() {
return this.id;
}
public static Type fromId(byte id) {
switch (id) {
case 1:
return CREATE;
case 2:
return SAVE;
case 3:
return DELETE;
case 4:
return DELETE_BY_QUERY;
default:
throw new ElasticsearchIllegalArgumentException("No type mapped for [" + id + "]");
}
}
}
Type opType();
long estimateSize();
Source getSource();
}tanslog部分就是实时记录所有的修改索引操作确保数据不丢失,因此它的实现上不上非常复杂。
总结
TransLog主要作用是实时记录对于索引的修改操作,确保在索引写入磁盘前出现系统故障不丢失数据。tanslog的主要作用就是索引恢复,正常情况下需要恢复索引的时候非常少,它以stream的形式顺序写入,不会消耗太多资源,不会成为性能瓶颈。它的实现上,translog提供了对外的接口,translogFile是具体的文件抽象,提供了对于文件的具体操作。
加载全部内容