python爬取数据
斜月 人气:0前言
前面已经讲述了如何获取股票的k线数据,今天我们来分析一下股票的资金流入情况,股票的上涨和下跌都是由资金推动的,这其中的北上资金就是一个风向标,今天就抓取一下北上资金对股票的逐天持仓变动和资金变动。
数据分析
照例先贴一下数据的访问地址:
# 以海尔智家为例贴一下数据的页面连接地址,再次吐槽一下拼音前缀 https://data.eastmoney.com/hsgtcg/StockHdStatistics/600690.html
下图就是北上资金逐天的访问数据页面,我们要抓取的是持股数量、持股市值、持股百分比和市值变化信息。
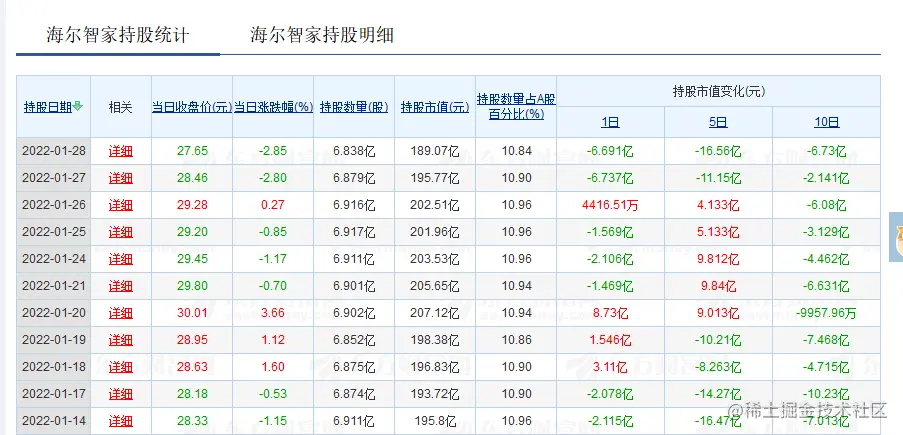
通过浏览器后台的接口可以看到这样一个接口数据:
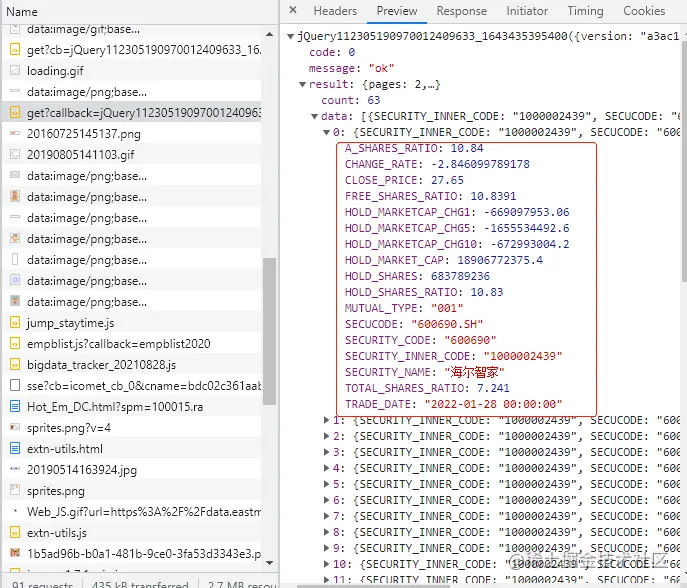
这个接口的参数为:
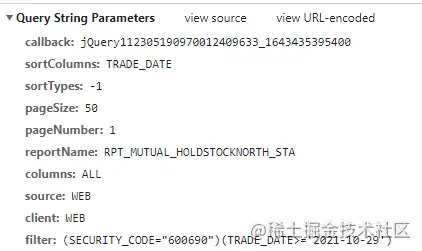
# 请求地址数据,这里的参数和请求的不太一样,因为其它的参数我试过了,可以忽略掉,以下是必要参数 https://datacenter-web.eastmoney.com/api/data/v1/get? # 排序字段和排序的类型, -1 为倒序排列 sortColumns=TRADE_DATE &sortTypes=-1 # 后两个参数比较简单,就是分页参数而已 &pageSize=50 &pageNumber=1 # 报告类型,固定为北上资金数据 &reportName=RPT_MUTUAL_HOLDSTOCKNORTH_STA # 返回的数据列,默认返回所有 &columns=ALL # 获取数据参数为股票代码和交易日期 &filter=(SECURITY_CODE="600690")(TRADE_DATE>='2021-10-29')
数据抓取
我们已经解析了获取资金的参数,以下就是使用 python 来获取数据,并进行展示。我们依旧使用 requets 来获取数据。
我们需要先组装请求的参数,这里的 fliter 只传入了代码,日期选择了固定,这个个人感觉是查询的 ES ,不然不会这么传入参数,建议做个参数转换吧,这样直传不太好。
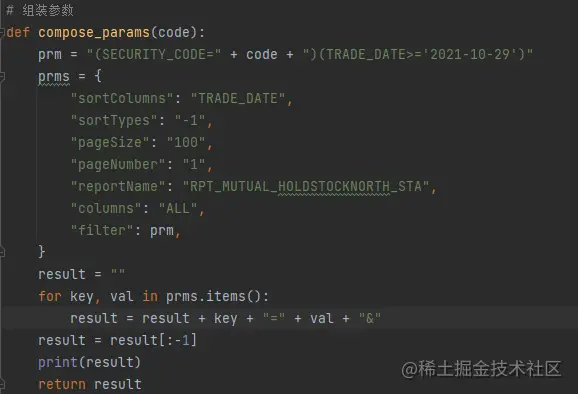
数据查询返回的结果是json 格式,进行了解析后我们采用 prettyTable 打印结果。
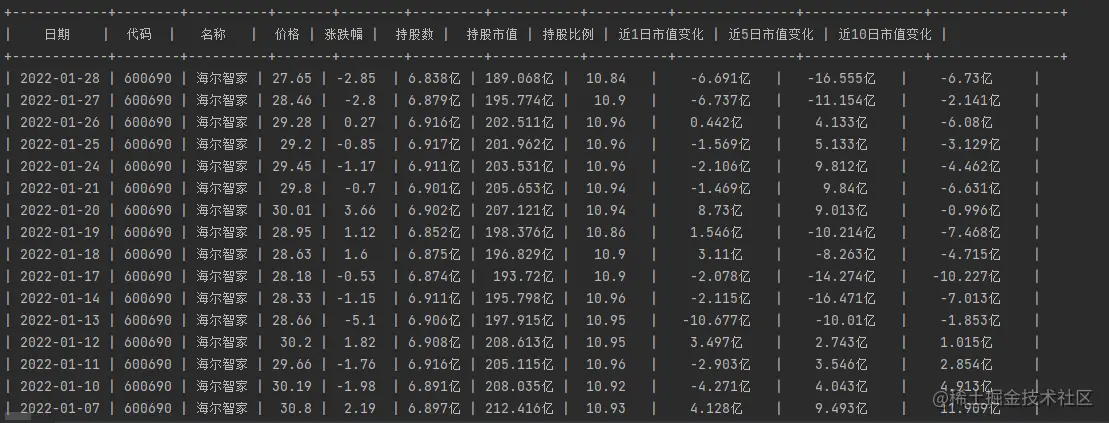
由于获取的数据没有经过格式化,显示的位数比较长,所以对持股数和市值之类的数据进行了格式化展示,
代码如下:
# 如果是亿级的就格式化为亿,万的话格式化为万
def cal_num(num):
if abs(num / 100000000) > 0:
return str(round(num / 100000000, 3)) + "亿"
else:
return str(round(num / 10000, 3)) + "万"最终我们得到的结果如下:
建立模型
我们已经获取到了股票的北上资金的情况,我们建立一个简单的模型筛选一下:
- 1 选取最近一个月内北上资金连续加仓的股票,加仓幅度超过流通股份的1%。
在这个模型中,我们可以根据最近一个月每天的持仓百分比建立线性规划模型,y = kx + b 来计算斜率和截距,但是这个觉得有点儿复杂了,我们可以简化一下,就偷个懒计算当天的持仓量与一个月前的持仓比例差值即可,
具体代码如下:
# rate_list 为持股比例的集合,将 ratio 添加进集合中,这里为什么是22呢,
# 一般情况下一个月有22个交易日,所以减去22就是一个月前的持仓比例
def cal_model(rate_list):
if len(rate_list) >= 22:
cur_node = rate_list[0]
pre_node = rate_list[22]
return cur_node - pre_node
return -100总结
今天我们使用接口获取了个股北上资金的持仓数据,并建立了简单的分析模型来选择股票,这个技术实现比较简单,作为学习和练习使用已经就足够了。
加载全部内容