python 重复值
FizzH 人气:0前言:
如果大家接触过数据分析,那么大家可能都知道,最让人头疼的就是在数据录入的过程中,不可避免的会产生重复值,缺失值和异常值了,python也提供了一些方法让我们处理这些值。下面让我们一块来学习一下吧~
今天,先处理重复值,首先创建一个包含重复值的DataFrame,如下:
import pandas as pd data = pd.DataFrame([[1,2],[1,2],[3,4]],columns = ['a','b']) print(data)
我们将其打印出来,结果如下:
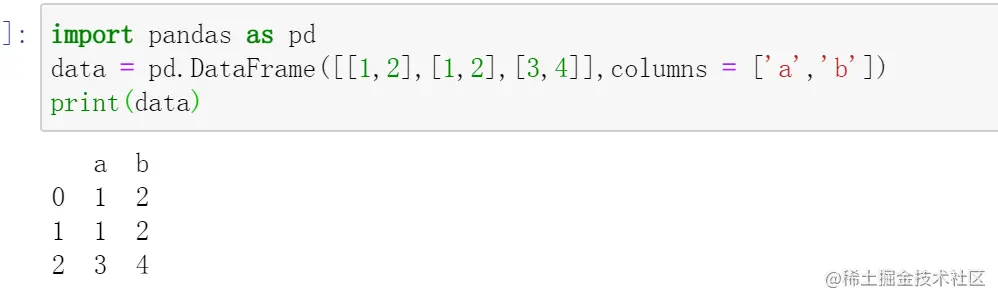
可以看出来第一第二行是重复的,这里的数据量比较少,可以直接肉眼观察,但如果数据量多的时候,我们就需要用到diplicated()函数来查询了,我们用它来查查上面data的重复值。
data[data.duplicated()]
我们可以看出,它把索引为1的行打印了出来,如果有3行一样的呢?我们下面来试试!

import pandas as pd data = pd.DataFrame([[1,2],[1,2],[1,2],[3,4]],columns = ['a','b']) data[data.duplicated()]
其结果如下:

可以看出,重复项出了第一个出现的数据外,都会显示出来。
如果想统计出一共有多少行重复了,我们就可以用到sum()函数,代码如下:
data.duplicated().sum()
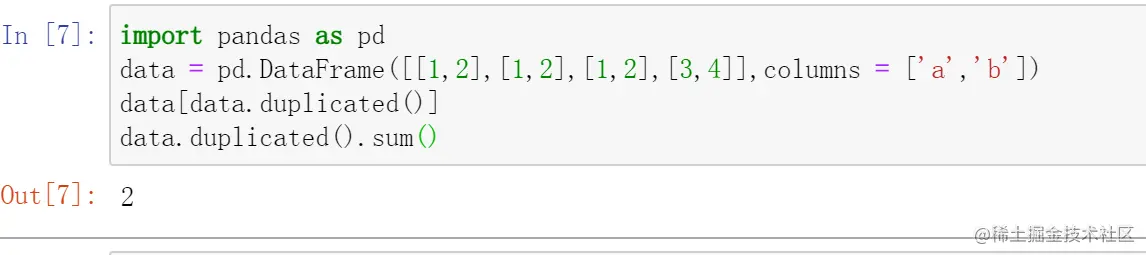
很多情况下,我们都需要删除掉重复的数据,这时候我们就可以用到drop_duplicated()函数,我们将data的重复行删除掉试试!
data.drop_duplicated()
刚执行代码时发生了错误,原来是duplicates而不是duplicated!
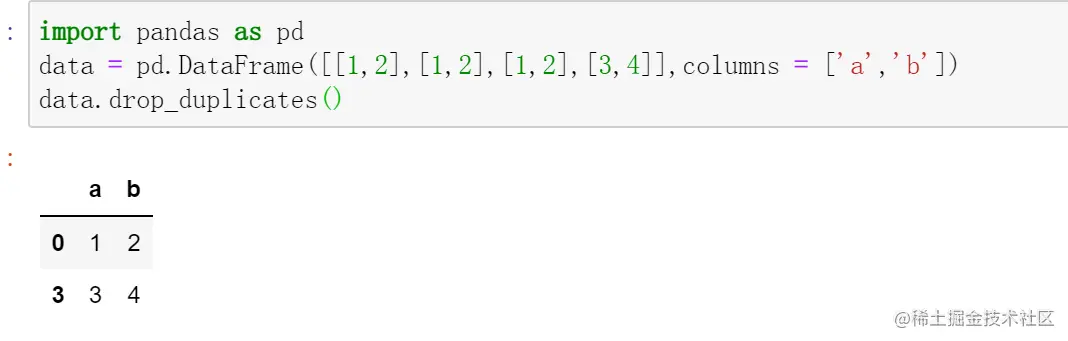
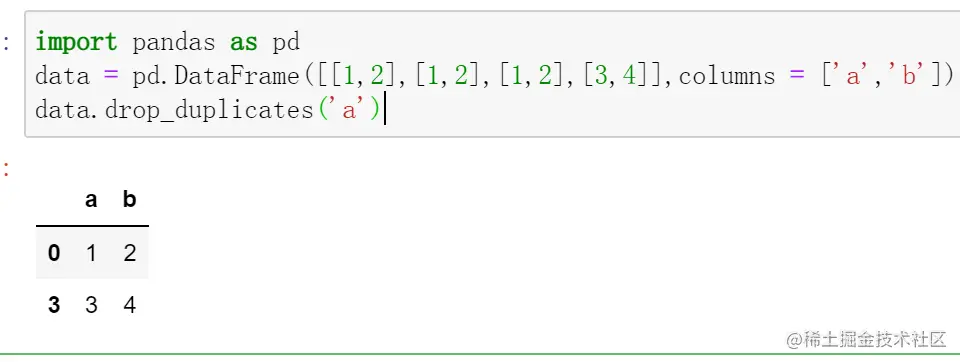
但是要注意,用drop_duplicates()删除重复项并不会影响data的结构,如果你要把data结构改掉就要重新赋值。如果要用来删除某列的重复值的话,直接在括号内加上列名即可。
如下:
加载全部内容