PyTorch加载数据集
心️升明月 人气:0一、实现过程
1、准备数据
与PyTorch实现多维度特征输入的逻辑回归的方法不同的是:本文使用DataLoader方法,并继承DataSet抽象类,可实现对数据集进行mini_batch梯度下降优化。
代码如下:
import torch
import numpy as np
from torch.utils.data import Dataset,DataLoader
class DiabetesDataSet(Dataset):
def __init__(self, filepath):
xy = np.loadtxt(filepath,delimiter=',',dtype=np.float32)
self.len = xy.shape[0]
self.x_data = torch.from_numpy(xy[:,:-1])
self.y_data = torch.from_numpy(xy[:,[-1]])
def __getitem__(self, index):
return self.x_data[index],self.y_data[index]
def __len__(self):
return self.len
dataset = DiabetesDataSet('G:/datasets/diabetes/diabetes.csv')
train_loader = DataLoader(dataset=dataset,batch_size=32,shuffle=True,num_workers=0)2、设计模型
class Model(torch.nn.Module): def __init__(self): super(Model,self).__init__() self.linear1 = torch.nn.Linear(8,6) self.linear2 = torch.nn.Linear(6,4) self.linear3 = torch.nn.Linear(4,1) self.activate = torch.nn.Sigmoid() def forward(self, x): x = self.activate(self.linear1(x)) x = self.activate(self.linear2(x)) x = self.activate(self.linear3(x)) return x model = Model()
3、构造损失函数和优化器
criterion = torch.nn.BCELoss(reduction='mean') optimizer = torch.optim.SGD(model.parameters(),lr=0.1)
4、训练过程
每次拿出mini_batch个样本进行训练,代码如下:
epoch_list = [] loss_list = [] for epoch in range(100): count = 0 loss1 = 0 for i, data in enumerate(train_loader,0): # 1.Prepare data inputs, labels = data # 2.Forward y_pred = model(inputs) loss = criterion(y_pred,labels) print(epoch,i,loss.item()) count += 1 loss1 += loss.item() # 3.Backward optimizer.zero_grad() loss.backward() # 4.Update optimizer.step() epoch_list.append(epoch) loss_list.append(loss1/count)
5、结果展示
plt.plot(epoch_list,loss_list,'b')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.grid()
plt.show()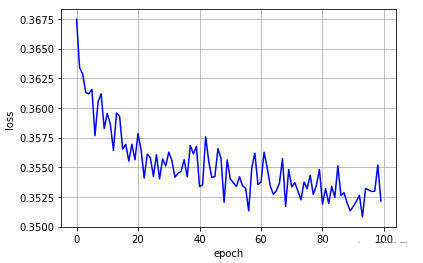
二、参考文献
到此这篇关于PyTorch加载数据集梯度下降优化的文章就介绍到这了,更多相关PyTorch加载数据集内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
加载全部内容