TensorFlow简单线性回归
kylinxjd 人气:0简单的一元线性回归
一元线性回归公式:
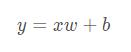
其中x是特征:[x1,x2,x3,…,xn,]T
w是权重,b是偏置值
代码实现
导入必须的包
import tensorflow as tf import matplotlib.pyplot as plt import numpy as np import os # 屏蔽warning以下的日志信息 os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
产生模拟数据
def generate_data(): x = tf.constant(np.array([i for i in range(0, 100, 5)]).reshape(-1, 1), tf.float32) y = tf.add(tf.matmul(x, [[1.3]]) + 1, tf.random_normal([20, 1], stddev=30)) return x, y
x是100行1列的数据,tf.matmul是矩阵相乘,所以权值设置成二维的。
设置的w是1.3, b是1
实现回归
def myregression():
"""
自实现线性回归
:return:
"""
x, y = generate_data()
# 建立模型 y = x * w + b
# w 1x1的二维数据
w = tf.Variable(tf.random_normal([1, 1], mean=0.0, stddev=1.0), name='weight_a')
b = tf.Variable(0.0, name='bias_b')
y_predict = tf.matmul(x, a) + b
# 建立损失函数
loss = tf.reduce_mean(tf.square(y_predict - y))
# 训练
train_op = tf.train.GradientDescentOptimizer(0.1).minimize(loss=loss)
# 初始化全局变量
init_op = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init_op)
print('初始的权重:%f偏置值:%f' % (a.eval(), b.eval()))
# 训练优化
for i in range(1, 100):
sess.run(train_op)
print('第%d次优化的权重:%f偏置值:%f' % (i, a.eval(), b.eval()))
# 显示回归效果
show_img(x.eval(), y.eval(), y_predict.eval())使用matplotlib查看回归效果
def show_img(x, y, y_pre): plt.scatter(x, y) plt.plot(x, y_pre) plt.show()
完整代码
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
def generate_data():
x = tf.constant(np.array([i for i in range(0, 100, 5)]).reshape(-1, 1), tf.float32)
y = tf.add(tf.matmul(x, [[1.3]]) + 1, tf.random_normal([20, 1], stddev=30))
return x, y
def myregression():
"""
自实现线性回归
:return:
"""
x, y = generate_data()
# 建立模型 y = x * w + b
w = tf.Variable(tf.random_normal([1, 1], mean=0.0, stddev=1.0), name='weight_a')
b = tf.Variable(0.0, name='bias_b')
y_predict = tf.matmul(x, w) + b
# 建立损失函数
loss = tf.reduce_mean(tf.square(y_predict - y))
# 训练
train_op = tf.train.GradientDescentOptimizer(0.0001).minimize(loss=loss)
init_op = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init_op)
print('初始的权重:%f偏置值:%f' % (w.eval(), b.eval()))
# 训练优化
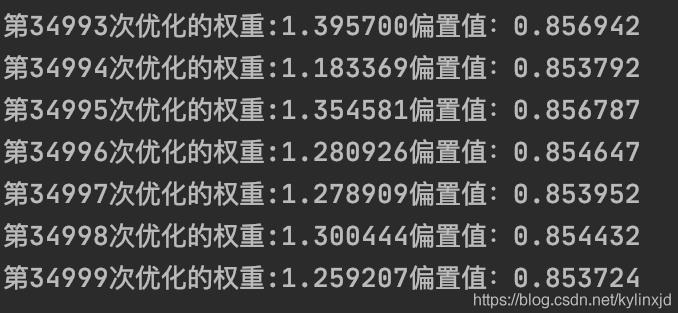
for i in range(1, 35000):
sess.run(train_op)
print('第%d次优化的权重:%f偏置值:%f' % (i, w.eval(), b.eval()))
show_img(x.eval(), y.eval(), y_predict.eval())
def show_img(x, y, y_pre):
plt.scatter(x, y)
plt.plot(x, y_pre)
plt.show()
if __name__ == '__main__':
myregression()看看训练的结果(因为数据是随机产生的,每次的训练结果都会不同,可适当调节梯度下降的学习率和训练步数)
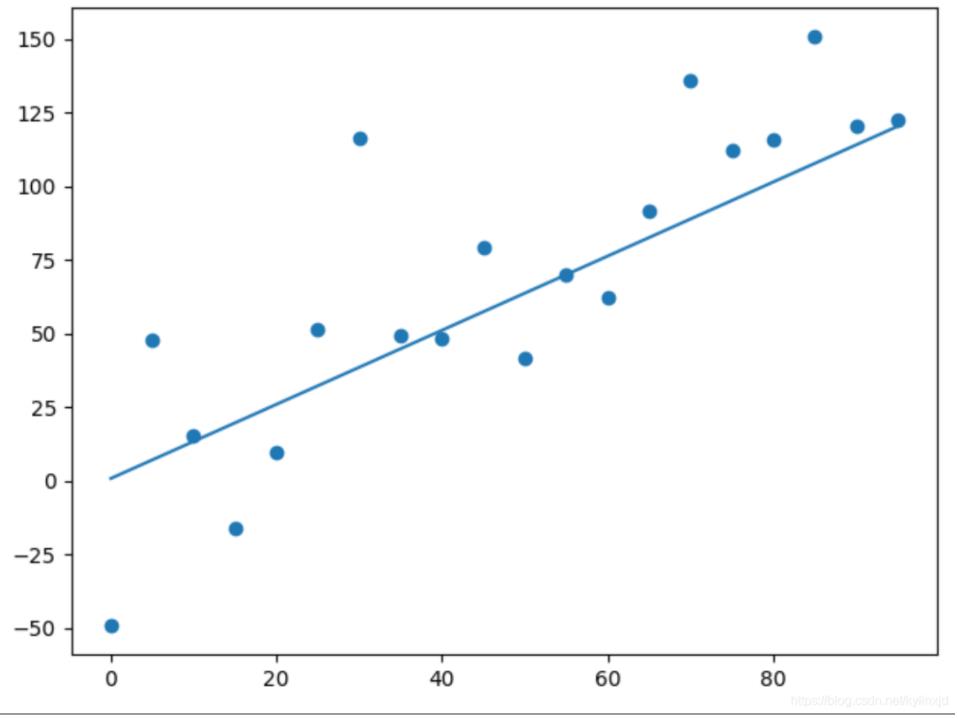
35000次的训练结果
加载全部内容