Java流量合并拆分提高系统的并发量
Java知识图谱 人气:0序言
在并发场景中,当热点缓存Key失效时,流量瞬间打到数据库中,此所谓缓存击穿现象;当大范围的缓存Key失效时,流量也会打到数据库中,此所谓缓存雪崩现象。
当使用分布式行锁时,能够有效解决缓存击穿问题;当使用分布式表锁时,能够解决缓存雪崩问题。实际操作中,分布式表锁不在考虑范围,理由是降低并发量。
本文将从另一个角度出发,将请求流量合并和拆分,以提高系统的并发量。
理论基础
流量的合并与拆分原理是将多条请求合并成一条请求,执行后再将结果拆分。在数据库与缓存架构中,缓存Key失效的瞬间,大量重复请求打到数据库中。实际上除了第一条请求为有效请求,随后的请求为无效请求,浪费数据库连接资源。
流量的合并与拆分实践是额外唤醒一个线程,每隔固定时间(比如200毫秒)发送合并后的请求,执行完成后将查询结果进行拆分,分发到原始请求中,原始请求响应用户请求。
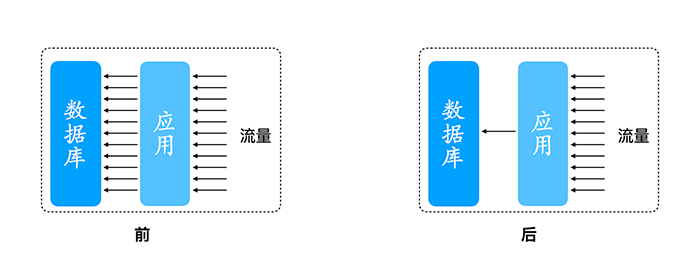
从应用到数据库之间连接资源需求显著下降,从而提高数据库连接资源利用率。
应用实践
(一)编码与使用
基于MybatisPlus提供一个内置封装的服务类QueueServiceImpl,透明的实现查询详情流量的合并与拆分,使用者可屏蔽内部实现。
<dependency>
<groupId>xin.altitude.cms</groupId>
<artifactId>ucode-cms-common</artifactId>
<version>1.4.4</version>
</dependency>对于一定时间区间内的所有请求,合并成一条请求处理。
@Override
public BuOrder getOrderById(Long orderId) {
return getById(orderId);
}举例说明,如果特定时间区间内汇集了相同的主键请求,那么合并后的请求查询一次数据库便能够响应所有的请求。
子类重写父类方法,可修改合并与拆分的行为。
@Override
protected RequstConfig createRequstConfig() {
RequstConfig config = new RequstConfig();
/* 单次最大合并请求数量 */
config.setMaxRequestSize(100);
/* 核心线程池大小 */
config.setCorePoolSize(1);
/* 请求间隔(毫秒) */
config.setRequestInterval(200);
return config;
}实现细节
1、ConcurrentLinkedQueue
使用ConcurrentLinkedQueue并发安全队列用于缓冲和接收请求,定时任务以固定频率从队列中消费数据,将多条请求条件合并后汇总查询。
2、CompletableFuture
CompletableFuture类是合并与拆分的关键类,原始请求将查询条件封装成CompletableFuture对象,提交到队列中后陷入阻塞,定时任务分批次组装查询条件,得到结果后将结果拆分并存入CompletableFuture对象中,原始请求线程被唤醒,继续响应用户请求。
其它应用场景
应用于数据库间流量的合并请求与拆分,首先提高数据库连接资源(稀缺资源)利用率,其次提高网络间数据传输效率。100条数据收发100次与100条数据收发一次的效率差别。
1、服务间接口调用
服务间API接口调用同样适用于流量的合并与拆分:比如向订单服务发送Http API请求,同一时刻有100个用户发起查询请求,使用流量合并与拆分的思想可将多个订单查询请求转换成批查询请求,得到结果后分发到不同的请求线程,响应用户请求。
小结
在本文中,选用的队列是本地并发安全的队列,在分布式系统中,本地队列是否合适?此处选用本地队列基于两点考虑:一是无严格的分布式的需求;二是CompletableFuture类不支持序列化。考虑使用Redis做分布式队列的想法无法实现,你用本地队列,尽管会有少量查询条件数据冗余(不影响结果),回避了分布式队列的网络IO延迟,反而有更优的查询效率。
本方案仅在高并发场景受益,属于针对并发场景进行架构的优化,普通项目使用常规操作即可。
加载全部内容