Python OpenCV特征匹配
机器视觉小学徒 人气:0前言
获得图像的关键点后,可通过计算得到关键点的描述符。关键点描述符可用于图像的特征匹配。通常,在计算图A是否包含图B的特征区域时,将图A称做训练图像,将图B称为查询图像。图A的关键点描述符称为训练描述符,图B的关键点描述符称为查询描述符。
一、暴力匹配器
暴力匹配器使用描述符进行特征比较。在比较时,暴力匹配器首先在查询描述符中取一个关键点的描述符,将其与训练描述符中的所有关键点描述符进行比较,每次比较后会给出一个距离值,距离最小的值对应最佳匹配结果。所有描述符比较完后,匹配器返回匹配结果列表。
OpenCV的cv2.BFMatcher_create()函数用于创建暴力匹配器,其基本格式如下:
bf = cv2.BFMatcher_create([normType[, crossCheck]])
bf为返回的暴力匹配器对象
normType为距离测量类型, 默认为cv2.NORM_L2, 通常, SIFT描述符使用cv2.NORM_L1或cv2.NORM_L2, ORB描述符使用cv2.NORM_HAMMING
crossCheck默认为False, 匹配器为每个查询描述符找到k个距离最近的匹配描述符, 为True时, 只返回满足交叉验证条件的匹配结果
暴力匹配器对象的match()方法返回每个关键点的最佳匹配结果,其基本格式如下:
ms = bf.match(des1, des2)
ms为返回的结果, 它是一个DMatch对象列表, 每个DMatch对象表示关键点的一个匹配结果, 其dintance属性表示距离, 距离值越小匹配度越高
des1为查询描述符
des2为训练描述符
获得匹配结果后,可调用cv2.drawMatches()函数或cv2.drawMatchesKnn()函数绘制匹配结果图像,其基本格式如下:
outImg = cv2.drawMatches(img1, keypoints1, img2, keypoints2, matches1to2[, matchColor[, singlePointColor[, matchesMask[, flags]]]])
outImg为返回的绘制结果图像, 图像中查询图像与训练图像中匹配的关键点个两点之间的连线为彩色
img1为查询图像
keypoints1为img1的关键点
img2为训练图像
keypoints2为img2的关键点
matches1to2为img1与img2的匹配结果
matchColor为关键点和链接线的颜色, 默认使用随机颜色
singlePointColor为单个关键点的颜色, 默认使用随机颜色
matchesMask为掩膜, 用于决定绘制哪些匹配结果, 默认为空, 表示绘制所有匹配结果
flags为标志, 可设置为下列参数值:
cv2.DrawMatchesFlags_DEFAUL:默认方式, 绘制两个源图像、匹配项和单个关键点, 没有围绕关键点的圆以及关键点的大小和方向
cv2.DrawMatchesFlags_NOT_DRAW_SINGLE_POINTS:不会绘制单个关键点
cv2.DrawMatchesFlags_DRAW_RICH_KEYPOINTS:在关键点周围绘制具有关键点大小和方向的圆圈
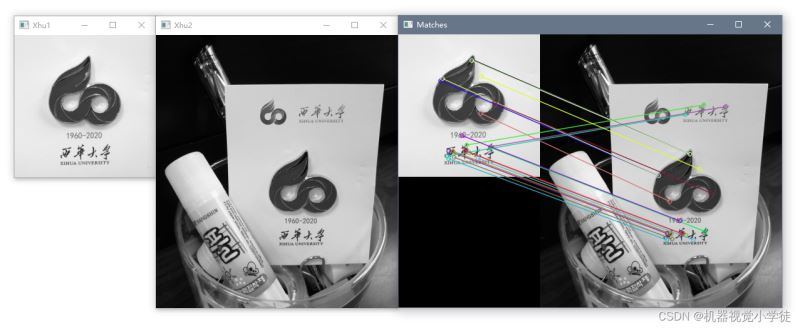
# 暴力匹配器、ORB描述符和match()方法
import cv2
img1 = cv2.imread("xhu1.jpg", cv2.IMREAD_GRAYSCALE)
img2 = cv2.imread("xhu2.jpg", cv2.IMREAD_GRAYSCALE)
orb = cv2.ORB_create()
kp1, des1 = orb.detectAndCompute(img1, None)
kp2, des2 = orb.detectAndCompute(img2, None)
bf = cv2.BFMatcher_create(cv2.NORM_HAMMING, crossCheck = False)
ms = bf.match(des1, des2)
ms = sorted(ms, key = lambda x:x.distance)
img3 = cv2.drawMatches(img1, kp1, img2, kp2, ms[:20], None, flags=cv2.DrawMatchesFlags_NOT_DRAW_SINGLE_POINTS)
cv2.imshow("Xhu1", img1)
cv2.imshow("Xhu2", img2)
cv2.imshow("Matches", img3)
cv2.waitKey(0)
cv2.destroyAllWindows()

# 暴力匹配器、SIFT描述符和match()方法
import cv2
img1 = cv2.imread("xhu1.jpg", cv2.IMREAD_GRAYSCALE)
img2 = cv2.imread("xhu2.jpg", cv2.IMREAD_GRAYSCALE)
sift=cv2.SIFT_create()
kp1, des1 = sift.detectAndCompute(img1, None)
kp2, des2 = sift.detectAndCompute(img2, None)
bf = cv2.BFMatcher_create(cv2.NORM_L1, crossCheck = False)
ms = bf.match(des1, des2)
ms = sorted(ms, key = lambda x:x.distance)
img3 = cv2.drawMatches(img1, kp1, img2, kp2, ms[:20], None, flags=cv2.DrawMatchesFlags_NOT_DRAW_SINGLE_POINTS)
# ms = np.expand_dims(ms,1)
# img3 = cv2.drawMatchesKnn(img1, kp1, img2, kp2, ms[:20], None, flags=cv2.DrawMatchesFlags_NOT_DRAW_SINGLE_POINTS)
cv2.imshow("Xhu1", img1)
cv2.imshow("Xhu2", img2)
cv2.imshow("Matches", img3)
cv2.waitKey(0)
cv2.destroyAllWindows()
暴力匹配器对象的knnMatch()方法可返回指定数量的最佳匹配结果,其基本格式如下:
ms = knnMatch(des1, des2, k=n)
ms为返回的匹配结果, 每个列表元素是一个子列表, 它包含了由参数k指定个数的DMatch对象
des1为查询描述符
des2为训练描述符
k为返回的最佳匹配个数
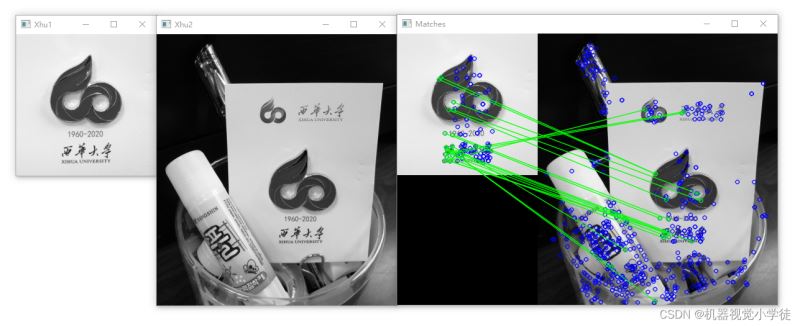
# 暴力匹配器、ORB描述符和knnMatch()方法
import cv2
img1 = cv2.imread("xhu1.jpg", cv2.IMREAD_GRAYSCALE)
img2 = cv2.imread("xhu2.jpg", cv2.IMREAD_GRAYSCALE)
orb = cv2.ORB_create()
kp1, des1 = orb.detectAndCompute(img1, None)
kp2, des2 = orb.detectAndCompute(img2, None)
bf = cv2.BFMatcher_create(cv2.NORM_HAMMING, crossCheck = False)
ms = bf.knnMatch(des1, des2, k=2)
# 应用比例测试选择要使用的匹配结果
good = []
for m, n in ms:
if m.distance < 0.75 * n.distance:
good.append(m)
img3 = cv2.drawMatches(img1, kp1, img2, kp2, good[:20], None, flags=cv2.DrawMatchesFlags_NOT_DRAW_SINGLE_POINTS)
# good = np.expand_dims(good,1)
#img3 = cv2.drawMatchesKnn(img1, kp1, img2, kp2, good[:20], None, flags=cv2.DrawMatchesFlags_NOT_DRAW_SINGLE_POINTS)
cv2.imshow("Xhu1", img1)
cv2.imshow("Xhu2", img2)
cv2.imshow("Matches", img3)
cv2.waitKey(0)
cv2.destroyAllWindows()
二、FLANN匹配器
FLANN(Fast Library for Approximate Nearest Neignbors)为近似最近邻的快速库,FLANN特征匹配算法比其它的最近邻算法更快。
在创建FLANN匹配器时,需要传递两参数:index_params和search_params。
index_params用来指定索引树的算法类型和数量。SIFT算法可以使用下面的代码来设置。
FLANN_INDEX_KDTREE = 1
index_params = dict(algorithm = FLANN_INDEX_KDTREE,
trees= 5)
ORB算法可以使用下面的代码来设置。
FLANN_INDEX_LSH = 6
index_params = dict(algorithm = FLANN_INDEX_LSH,
table_number = 6,
key_size = 12,
multi_probe_level = 1)
search_params用于指定索引树的遍历次数,遍历次数越多,匹配结果越精细,通常设置为50即可,如下所示:
search_params = dict(check = 50)
# FLANN匹配器、ORB描述符
import cv2
img1 = cv2.imread("xhu1.jpg", cv2.IMREAD_GRAYSCALE)
img2 = cv2.imread("xhu2.jpg", cv2.IMREAD_GRAYSCALE)
orb = cv2.ORB_create()
kp1, des1 = orb.detectAndCompute(img1, None)
kp2, des2 = orb.detectAndCompute(img2, None)
# 定义FLANN参数
FLANN_INDEX_LSH = 6
index_params = dict(algorithm = FLANN_INDEX_LSH,
table_number = 6,
key_size = 12,
multi_probe_level = 1)
search_params = dict(check = 50)
flann = cv2.FlannBasedMatcher(index_params, search_params)
matches = flann.match(des1, des2)
draw_params = dict(matchColor = (0,255,0),
singlePointColor = (255,0,0),
matchesMask = None,
flags = cv2.DrawMatchesFlags_DEFAULT)
img3 = cv2.drawMatches(img1, kp1, img2, kp2, matches[:20], None, **draw_params)
cv2.imshow("Xhu1", img1)
cv2.imshow("Xhu2", img2)
cv2.imshow("Matches", img3)
cv2.waitKey(0)
cv2.destroyAllWindows()

# FLANN匹配器、SIFT描述符
import cv2
img1 = cv2.imread("xhu1.jpg", cv2.IMREAD_GRAYSCALE)
img2 = cv2.imread("xhu2.jpg", cv2.IMREAD_GRAYSCALE)
sift = cv2.SIFT_create()
kp1, des1 = sift.detectAndCompute(img1, None)
kp2, des2 = sift.detectAndCompute(img2, None)
# 定义FLANN参数
FLANN_INDEX_KDTREE = 1
index_params = dict(algorithm = FLANN_INDEX_KDTREE,
trees = 5)
search_params = dict(check = 50)
flann = cv2.FlannBasedMatcher(index_params, search_params)
matches = flann.match(des1, des2)
draw_params = dict(matchColor = (0,255,0),
singlePointColor = (255,0,0),
matchesMask = None,
flags = cv2.DrawMatchesFlags_DEFAULT)
img3 = cv2.drawMatches(img1, kp1, img2, kp2, matches[:20], None, **draw_params)
cv2.imshow("Xhu1", img1)
cv2.imshow("Xhu2", img2)
cv2.imshow("Matches", img3)
cv2.waitKey(0)
cv2.destroyAllWindows()
加载全部内容