python tkinter treeview列表显示
IronSimon 人气:0素材文件
- result.txt
- result2.txt
result.txt文件的数据来源是爬取猫眼电影前一百名的电影,而result2.txt文件只不过是内容上把result.txt的内容复制几十次,使其数据足够多,现截选如下:
{"排名": "1", "片名": "霸王别姬", "主演": "张国荣,张丰毅,巩俐", "上映时间": "1993-01-01(中国香港)", "评分": "9.6"}
{"排名": "2", "片名": "罗马假日", "主演": "格利高里·派克,奥黛丽·赫本,埃迪·艾伯特", "上映时间": "1953-09-02(美国)", "评分": "9.1"}
{"排名": "3", "片名": "肖申克的救赎", "主演": "蒂姆·罗宾斯,摩根·弗里曼,鲍勃·冈顿", "上映时间": "1994-10-14(美国)", "评分": "9.5"}
{"排名": "4", "片名": "这个杀手不太冷", "主演": "让·雷诺,加里·奥德曼,娜塔莉·波特曼", "上映时间": "1994-09-14(法国)", "评分": "9.5"}
{"排名": "5", "片名": "教父", "主演": "马龙·白兰度,阿尔·帕西诺,詹姆斯·肯恩", "上映时间": "1972-03-24(美国)", "评分": "9.3"}
{"排名": "6", "片名": "泰坦尼克号", "主演": "莱昂纳多·迪卡普里奥,凯特·温丝莱特,比利·赞恩", "上映时间": "1998-04-03", "评分": "9.5"}
{"排名": "7", "片名": "龙猫", "主演": "日高法子,坂本千夏,糸井重里", "上映时间": "1988-04-16(日本)", "评分": "9.2"}
{"排名": "8", "片名": "唐伯虎点秋香", "主演": "周星驰,巩俐,郑佩佩", "上映时间": "1993-07-01(中国香港)", "评分": "9.2"}
{"排名": "9", "片名": "千与千寻", "主演": "柊瑠美,入野自由,夏木真理", "上映时间": "2001-07-20(日本)", "评分": "9.3"}
{"排名": "10", "片名": "魂断蓝桥", "主演": "费雯·丽,罗伯特·泰勒,露塞尔·沃特森", "上映时间": "1940-05-17(美国)", "评分": "9.2"}
{"排名": "11", "片名": "乱世佳人", "主演": "费雯·丽,克拉克·盖博,奥利维娅·德哈维兰", "上映时间": "1939-12-15(美国)", "评分": "9.1"}实现效果
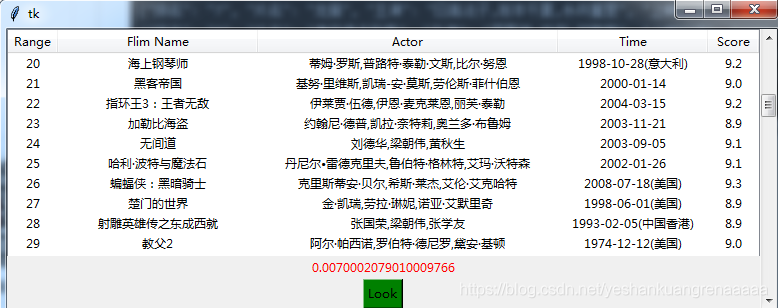
版本一实现的代码:
# -*- coding: utf-8 -*-
"""
Created on Fri Jan 4 13:44:40 2019
@author: HJY
"""
import tkinter as tk
from tkinter import ttk
import re
import time
#固定
pattern = '{"排名": "(.*?)", "片名": "(.*?)", "主演": "(.*?)", "上映时间": "(.*?)", "评分": "(.*?)"}\n'
patch = re.compile(pattern)
class info():
def __init__(self,):
self.root = tk.Tk()
self._setpage()
def _setpage(self,):
start= time.time()
self.scrollbar = tk.Scrollbar(self.root,)
self.scrollbar.pack(side=tk.RIGHT,fill=tk.Y)
title=['1','2','3','4','5',]
self.box = ttk.Treeview(self.root,columns=title,
yscrollcommand=self.scrollbar.set,
show='headings')
self.box.column('1',width=50,anchor='center')
self.box.column('2',width=200,anchor='center')
self.box.column('3',width=300,anchor='center')
self.box.column('4',width=150,anchor='center')
self.box.column('5',width=50,anchor='center')
self.box.heading('1',text='Range')
self.box.heading('2',text='Flim Name')
self.box.heading('3',text='Actor')
self.box.heading('4',text='Time')
self.box.heading('5',text='Score')
self.dealline()
self.scrollbar.config(command=self.box.yview)
self.box.pack()
end=time.time()
tk.Label(self.root,text=end-start,fg='red').pack()
tk.Button(self.root,text='Look',bg='green',).pack()
def readdata(self,):
"""逐行读取文件"""
#读取gbk编码文件,需要加encoding='utf-8'
f = open('result.txt','r',encoding='utf-8')
line = f.readline()
while line:
yield line
line = f.readline()
f.close()
def dealline(self,):
op = self.readdata()
while 1:
try:
line = next(op)
except StopIteration as e:
break
else:
result = patch.match(line)
self.box.insert('','end',values=[result.group(i) for i in range(1,6)])
if __name__ == '__main__':
op = info()
op.root.mainloop()首先这里引入yield的用法,实现逐行读取文件,迭代器只有在每一次next()的时候才会产生下一条数据,而不需要一次性读取整份文件,处理文件中的每行数据并且保存结果,这种方式可以有效的避免面对大文件时的处理时间以及内存等问题。
但这里还是等文件中的数据都处理好都插入tkinter控件中时,才执行下一步的程序(也就是self.dealline()之后的程序语句),这会造成什么问题呢?如果处理的是result.txt文件那种只有100条数据的文件,用户不会感受到什么,但若处理result2.txt那样的文件,那么就会感觉到卡顿,似乎要等一会才显示应用程序。
解决思路
可否一开始只向控件中插入10条或者50条数据,当用户浏览到第10条数据时就马上加载接下来的10条数据?
实现一:绑定鼠标的滚轮事件,一旦监听到下滚事件,就触发加载。
实现二:当用户点击按钮时,就加载数据。这种一般用于翻页等等。
实现三:当用户拖拽滑块到底端时,若还有数据没加载完,就触发加载(为实现)。
改进后代码实现
# -*- coding: utf-8 -*-
"""
Created on Tue Jan 8 13:45:21 2019
@author: HJY
"""
# -*- coding: utf-8 -*-
"""
Created on Fri Jan 4 13:44:40 2019
@author: HJY
"""
import tkinter as tk
from tkinter import ttk
import re
import time
#固定
pattern = '{"排名": "(.*?)", "片名": "(.*?)", "主演": "(.*?)", "上映时间": "(.*?)", "评分": "(.*?)"}\n'
patch = re.compile(pattern)
class info():
def __init__(self,):
self.root = tk.Tk()
self._setpage()
def _setpage(self,):
start= time.time()
self.scrollbar = tk.Scrollbar(self.root,command=self.moveScroll)
self.scrollbar.bind("<MouseWheel>",self.moveScroll)
self.scrollbar.pack(side=tk.RIGHT,fill=tk.Y)
title=['1','2','3','4','5',]
self.box = ttk.Treeview(self.root,columns=title,
yscrollcommand=self.scrollbar.set,
show='headings')
self.box.bind("<MouseWheel>",self.moveScroll)
self.box.column('1',width=50,anchor='center')
self.box.column('2',width=200,anchor='center')
self.box.column('3',width=300,anchor='center')
self.box.column('4',width=150,anchor='center')
self.box.column('5',width=50,anchor='center')
self.box.heading('1',text='Range')
self.box.heading('2',text='Flim Name')
self.box.heading('3',text='Actor')
self.box.heading('4',text='Time')
self.box.heading('5',text='Score')
#对象处理
self.op = self.readdata()
self.dealline(self.op)
self.scrollbar.config(command=self.box.yview)
self.box.pack()
end=time.time()
tk.Label(self.root,text=end-start,fg='red').pack()
tk.Button(self.root,text='Look',bg='green',command=self.turn).pack()
#翻页模式,每点击一次,加载多10条数据
def turn(self):
# self.scrollbar.set(0.89,0.99)
# print(self.scrollbar.get())
self.dealline(self.op)
#鼠标滚动模式,下滑时加载数据
def moveScroll(self,event):
if event.delta < 0:
self.dealline(self.op)
def dragScroll(self):
#未实现
pass
def readdata(self,):
"""逐行读取文件"""
#读取gbk编码文件,需要加encoding='utf-8'
f = open('result2.txt','r',encoding='utf-8')
line = f.readline()
while line:
yield line
line = f.readline()
f.close()
def dealline(self,op):
self.cal = 0
while 1:
try:
line = next(op)
except StopIteration:
break
else:
result = patch.match(line)
self.box.insert('','end',values=[result.group(i) for i in range(1,6)])
self.cal +=1
if self.cal == 10:
break
if __name__ == '__main__':
op = info()
op.root.mainloop()评注
这种模式的问题:
1、如果是数据是用来搜索的,而用户没有触发加载,且所要搜索的数据并未在已经加载的数据中,那么就会导致搜索不到。当然,如果搜索时不基于控件中的数据,而基于文件本身或者数据库等,就不存在这种考虑的必要。另外,如果要求展
示搜索到的数据所在的行,那么就需要一旦搜索的数据行未加载,就要马上加载到所搜索的数据为止的所有未加载数据。
2、滚轮下滚时,用户还没将数据翻到底端数据,就触发了加载。
新的想法
可以利用scrollbar控件的get()方法,获得滑块的位置,一旦滑块的底端位置为1,则滑块已经到底端,此时触发加载,又由于next()迭代器再没有数据时会触发stopiteration异常阻止加载,而若还有数据则加载。我们可以将这一过程实现为函数,与scrollbar控件的command属性绑定,这样只要滑动滑块就会触发函数调用。
但是我们已经将其与treeview控件的yview函数绑定,联动实现滑块滑动列表框,所以我们需要把我们自己的实现嵌入这个yview函数,或者yview函数嵌入我们实现的函数里,只是中间一些环节只有理解了yview函数的处理模式,才好做了。
加载全部内容