python基本数据类型
爱吃苹果的派大星 人气:0题目[1]:格式输出练习。在交互式状态下完成以下练习。

运行结果截图:
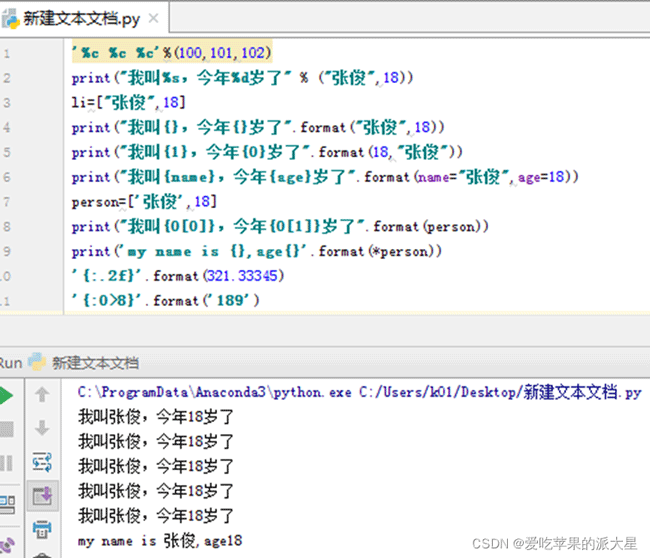
题目[2]:格式输出练习。在.py的文件中完成以下练习
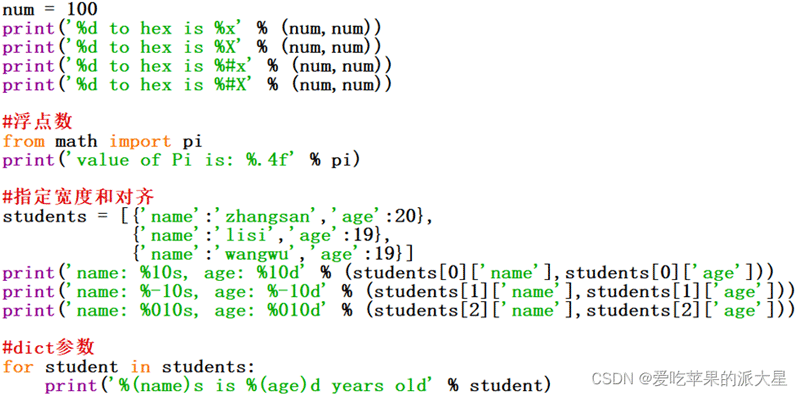
代码:
num = 100
print('%d to hex is %x' % (num,num))
print('%d to hex is %X' % (num,num))
print('%d to hex is %#x' % (num,num))
print('%d to hex is %#X' % (num,num))
from math import pi
print('value of Pi is: %.4f' % pi)
students = [{'name':'zhangsan','age':20},
{'name': 'lisi', 'age': 19},
{'name': 'wangwu', 'age': 19}]
print('name: %10s, age: %10d' % (students[0]['name'],students[0]['age']))
print('name: %-10s, age: %-10d' % (students[1]['name'],students[1]['age']))
print('name: %10s, age: %10d' % (students[2]['name'],students[2]['age']))
for student in students:
print('%(name)s is %(age)d years old' % student)运行:
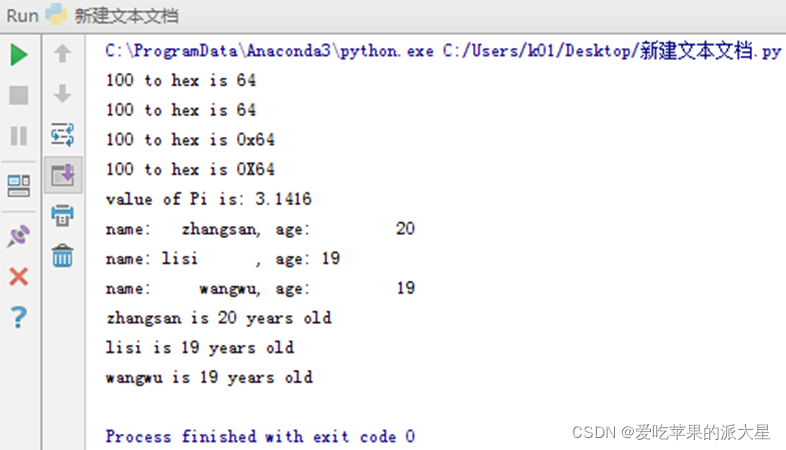
题目[3]:凯撒加密:

原理功能:
通过把字母移动一定的位数来实现加解密
明文中的所有字母从字母表向后(或向前)按照一个固定步长进行偏移后被替换成密文。
例如:当步长为3时,A被替换成D,B被替换成E,依此类推,X替换成A。
代码:
import string #ascii_letters = 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ' #ascii_lowercase = 'abcdefghijklmnopqrstuvwxyz' #ascii_uppercase = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ' def kaisa(s, k): lower = string.ascii_lowercase upper = string.ascii_uppercase before = string.ascii_letters after = lower[k:] + lower[:k] + upper[k:] + upper[:k] table = ''.maketrans(before,after) return s.translate(table) s = 'Python is a great programming language. I like it!' print(kaisa(s,3))
运行:
- 1)用字典记录下其豆瓣评分,并输出字典;
- 2)现又新出了两部影片及其评分(中国机长: 7.0,银河补习班: 6.2),将此影评加入1)中的字典中,同时输出字典中所有的影片名称。
- 3)现找出2)中的字典中影评得分最高的影片。
代码和运行结果:
1>
films = {'肖申克的救赎':9.7, '摔跤吧!爸爸':9.0,
'阿甘正传':9.5,'我和我的祖国':8.0,
'哪吒之魔童降世':8.5, '千与千寻':9.3,
'疯狂动物城':9.2,'攀登者':6.5}
print(films)
2>
films_new = {'中国机长':7.0,'银河补习班':6.2}
films.update(films_new) #字典中元素的插入 dict.update()函数
print("所有影片名称: ", films.keys())
题目[5]:编程实现:生成2组随机6位的数字验证码,每组10000个,且每组内不可重复。输出这2组的验证码重复个数。
代码和运行结果:
import random
code1 = [] #存储校验码列表
code2 = []
t = 0 #标志出现重复校验码个数
dict={}
#第一组校验码
for i in range(10000):
x = ''
for j in range(6):
x = x + str(random.randint(0, 9))
code1.append(x) # 生成的数字校验码追加到列表
#第二组校验码
for i in range(10000):
x = ''
for j in range(6):
x = x + str(random.randint(0, 9))
code2.append(x) # 生成的数字校验码追加到列表
#找重复
for i in range(len(code1)):
for j in range(len(code2)): # 对code1和code2所有校验码遍历
if (code1[i] == code2[j]):
t = t+1 #如果存在相同的,则t+1
if t > 0:
dict[code1[i]] = t # 如果重复次数大于0,用t表示其个数,存储在字典
#输出所有重复的校验码及其个数
for key in dict:
print(key + ":" + str(dict[key]))截取几张:

题目[6]:统计英文句子“Life is short, we need Python."中各字符出现的次数。
代码和运行结果:
#去空格,转化为list,然后再转化为字典
str = 'Life is short, we need Python.'
list = []
list2 = []
dict={}
i= 0
for w in str:
if w!=' ':
list.append(w)
#将str字符串的空格去掉放在list列表
for w in list:
c = list.count(w) #用count()函数返回当前字符的个数
dict[w] = c #针对字符w,用c表示其个数,存储在字典
print(dict) #输出字典
题目[7]:输入一句英文句子,输出其中最长的单词及其长度。
提示:可以使用split方法将英文句子中的单词分离出来存入列表后处理。
代码和运行结果:
test0 = 'It is better to live a beautiful life with all one''s ' \
'strength than to comfort oneself with ordinary and precious things!.'
test1 = test0.replace(',','').replace('.','') #用空格代替句子中“,”的空格和“。”
test2 = test1.split () #将英文句子中的单词分离出来存入列表
maxlen = max(len(word) for word in test2) #找到最大长度的单词长度值
C=[word for word in test2 if len(word)== maxlen] #找到最大长度的单词对应单词
print("最长的单词是:“{}” , 里面有 {} 个字母".format(C[0],maxlen))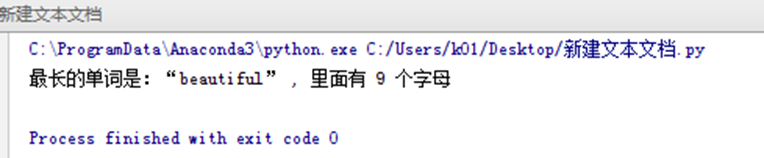
加载全部内容