python写福字
上进小菜猪 人气:0前言:
支付宝 2022 集五福活动正式开启
数据显示,过去六年累计参与支付宝集五福的人数已经超过了 7 亿,每 2 个中国人里就有 1 个曾扫福、集福、送福。
一,扫五福活动如此火爆,为何不自己利用编程来生成福字!
首先作品奉上:

①,导入python库
import io from PIL import Image import requests
②,利用爬虫,获取单个汉字
def get_word(ch, quality):
fp = io.BytesIO(requests.post(url='http://xufive.sdysit.com/tk', data={'ch':ch}).content)
im = Image.open(fp)
w, h = im.size
if quality == 'M':
w, h = int(w*0.75), int(0.75*h)
elif quality == 'L':
w, h = int(w*0.5), int(0.5*h)
return im.resize((w,h))
def get_word 的作用为爬取我们需要的汉字模型。
如图:

③,爬取背景底图
def get_bg(quality):
return get_word('bg', quality)
④,图片格式大小,配置函数
def write_couplets(text, HorV='V', quality='L', out_file=None):
usize = {'H':(640,23), 'M':(480,18), 'L':(320,12)}
bg_im = get_bg(quality)
text_list = [list(item) for item in text.split()]
rows = len(text_list)
cols = max([len(item) for item in text_list])
if HorV == 'V':
ow, oh = 40+rows*usize[quality][0]+(rows-1)*10, 40+cols*usize[quality][0]
else:
ow, oh = 40+cols*usize[quality][0], 40+rows*usize[quality][0]+(rows-1)*10
out_im = Image.new('RGBA', (ow, oh), '#f0f0f0')
for row in range(rows):
if HorV == 'V':
row_im = Image.new('RGBA', (usize[quality][0], cols*usize[quality][0]), 'white')
offset = (ow-(usize[quality][0]+10)*(row+1)-10, 20)
else:
row_im = Image.new('RGBA', (cols*usize[quality][0], usize[quality][0]), 'white')
offset = (20, 20+(usize[quality][0]+10)*row)
for col, ch in enumerate(text_list[row]):
if HorV == 'V':
pos = (0, col*usize[quality][0])
else:
pos = (col*usize[quality][0],0)
ch_im = get_word(ch, quality)
row_im.paste(bg_im, pos)
row_im.paste(ch_im, (pos[0]+usize[quality][1], pos[1]+usize[quality][1]), mask=ch_im)
out_im.paste(row_im, offset)
if out_file:
out_im.convert('RGB').save(out_file)
out_im.show()
⑤,成品展示
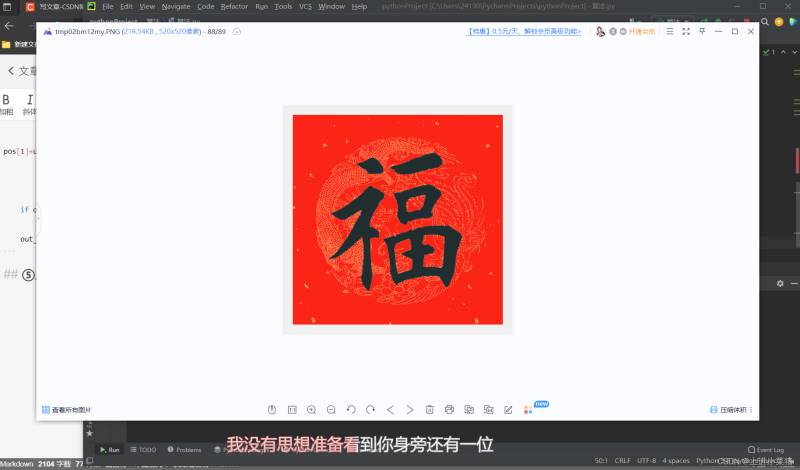
二,完整代码
完整代码奉上,需要先安装需要的python库。
import io
from PIL import Image
import requests
def get_word(ch, quality):
fp = io.BytesIO(requests.post(url='http://xufive.sdysit.com/tk', data={'ch':ch}).content)
im = Image.open(fp)
w, h = im.size
if quality == 'M':
w, h = int(w*0.75), int(0.75*h)
elif quality == 'L':
w, h = int(w*0.5), int(0.5*h)
return im.resize((w,h))
def get_bg(quality):
return get_word('bg', quality)
def write_couplets(text, HorV='V', quality='L', out_file=None):
usize = {'H':(640,23), 'M':(480,18), 'L':(320,12)}
bg_im = get_bg(quality)
text_list = [list(item) for item in text.split()]
rows = len(text_list)
cols = max([len(item) for item in text_list])
if HorV == 'V':
ow, oh = 40+rows*usize[quality][0]+(rows-1)*10, 40+cols*usize[quality][0]
else:
ow, oh = 40+cols*usize[quality][0], 40+rows*usize[quality][0]+(rows-1)*10
out_im = Image.new('RGBA', (ow, oh), '#f0f0f0')
for row in range(rows):
if HorV == 'V':
row_im = Image.new('RGBA', (usize[quality][0], cols*usize[quality][0]), 'white')
offset = (ow-(usize[quality][0]+10)*(row+1)-10, 20)
else:
row_im = Image.new('RGBA', (cols*usize[quality][0], usize[quality][0]), 'white')
offset = (20, 20+(usize[quality][0]+10)*row)
for col, ch in enumerate(text_list[row]):
if HorV == 'V':
pos = (0, col*usize[quality][0])
else:
pos = (col*usize[quality][0],0)
ch_im = get_word(ch, quality)
row_im.paste(bg_im, pos)
row_im.paste(ch_im, (pos[0]+usize[quality][1], pos[1]+usize[quality][1]), mask=ch_im)
out_im.paste(row_im, offset)
if out_file:
out_im.convert('RGB').save(out_file)
out_im.show()
text = '福'
write_couplets(text, HorV='V', quality='M', out_file='福.jpg')
三,总结
加载全部内容