GC垃圾优先算法
金色梦想 人气:0G1 – Garbage First(垃圾优先算法)
G1最主要的设计目标是: 将STW停顿的时间和分布变成可预期以及可配置的。事实上, G1是一款软实时垃圾收集器, 也就是说可以为其设置某项特定的性能指标. 可以指定: 在任意 xx 毫秒的时间范围内, STW停顿不得超过 x 毫秒。 如: 任意1秒暂停时间不得超过5毫秒. Garbage-First GC 会尽力达成这个目标(有很大的概率会满足, 但并不完全确定,具体是多少将是硬实时的[hard real-time])。
为了达成这项指标, G1 有一些独特的实现。首先, 堆不再分成连续的年轻代和老年代空间。而是划分为多个(通常是2048个)可以存放对象的 小堆区(**aller heap regions)。每个小堆区都可能是 Eden区, Survivor区或者Old区. 在逻辑上, 所有的Eden区和Survivor区合起来就是年轻代, 所有的Old区拼在一起那就是老年代:

这样的划分使得 GC不必每次都去收集整个堆空间, 而是以增量的方式来处理: 每次只处理一部分小堆区,称为此次的回收集(collection set). 每次暂停都会收集所有年轻代的小堆区, 但可能只包含一部分老年代小堆区:
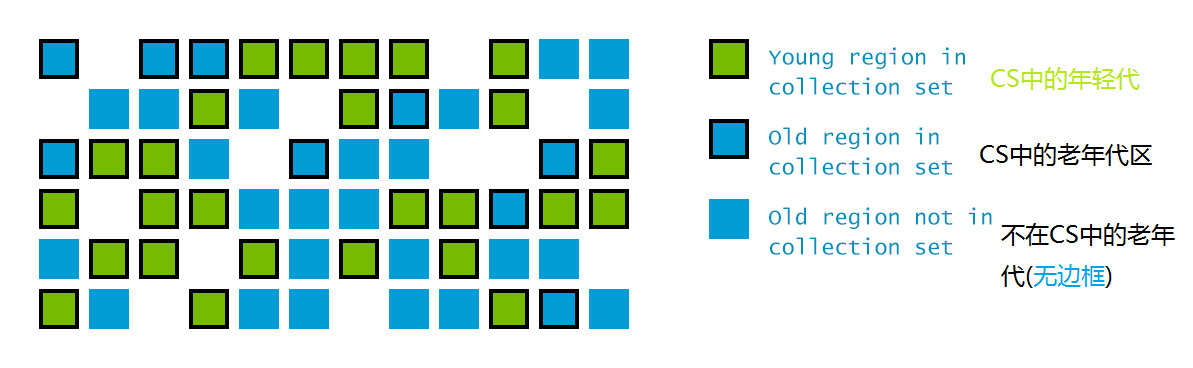
G1的另一项创新, 是在并发阶段估算每个小堆区存活对象的总数。用来构建回收集(collection set)的原则是: 垃圾最多的小堆区会被优先收集。这也是G1名称的由来: garbage-first。
要启用G1收集器, 使用的命令行参数为:
java -XX:+UseG1GC com.mypackages.MyExecutableClass
Evacuation Pause: Fully Young(转移暂停:纯年轻代模式)
在应用程序刚启动时, G1还未执行过(not-yet-executed)并发阶段, 也就没有获得任何额外的信息, 处于初始的 fully-young 模式. 在年轻代空间用满之后, 应用线程被暂停, 年轻代堆区中的存活对象被复制到存活区, 如果还没有存活区,则选择任意一部分空闲的小堆区用作存活区。
复制的过程称为转移(Evacuation), 这和前面讲过的年轻代收集器基本上是一样的工作原理。转移暂停的日志信息很长,为简单起见, 我们去除了一些不重要的信息. 在并发阶段之后我们会进行详细的讲解。此外, 由于日志记录很多, 所以并行阶段和“其他”阶段的日志将拆分为多个部分来进行讲解:
0.134: [GC pause (G1 Evacuation Pause) (young), 0.0144119 secs] [Parallel Time: 13.9 ms, GC Workers: 8] … [Code Root Fixup: 0.0 ms] [Code Root Purge: 0.0 ms] [Clear CT: 0.1 ms] [Other: 0.4 ms] … [Eden: 24.0M(24.0M)->0.0B(13.0M) Survivors: 0.0B->3072.0K Heap: 24.0M(256.0M)->21.9M(256.0M)] [Times: user=0.04 sys=0.04, real=0.02 secs]
>
0.134: [GC pause (G1 Evacuation Pause) (young), 0.0144119 secs] – G1转移暂停,只清理年轻代空间。暂停在JVM启动之后 134 ms 开始, 持续的系统时间为 0.0144秒 。
[Parallel Time: 13.9 ms, GC Workers: 8] – 表明后面的活动由8个 Worker 线程并行执行, 消耗时间为13.9毫秒(real time)。
… – 为阅读方便, 省略了部分内容,请参考后文。
[Code Root Fixup: 0.0 ms] – 释放用于管理并行活动的内部数据。一般都接近于零。这是串行执行的过程。
[Code Root Purge: 0.0 ms] – 清理其他部分数据, 也是非常快的, 但如非必要则几乎等于零。这是串行执行的过程。
[Other: 0.4 ms] – 其他活动消耗的时间, 其中有很多是并行执行的。
… – 请参考后文。
[Eden: 24.0M(24.0M)->0.0B(13.0M) – 暂停之前和暂停之后, Eden 区的使用量/总容量。
Survivors: 0.0B->3072.0K – 暂停之前和暂停之后, 存活区的使用量。
Heap: 24.0M(256.0M)->21.9M(256.0M)] – 暂停之前和暂停之后, 整个堆内存的使用量与总容量。
[Times: user=0.04 sys=0.04, real=0.02 secs] – GC事件的持续时间, 通过三个部分来衡量:
- user – 在此次垃圾回收过程中, 由GC线程所消耗的总的CPU时间。
- sys – GC过程中, 系统调用和系统等待事件所消耗的时间。
- real – 应用程序暂停的时间。在并行GC(Parallel GC)中, 这个数字约等于: (user time + system time)/GC线程数。 这里使用的是8个线程。 请注意,总是有一定比例的处理过程是不能并行化的。
说明: 系统时间(wall clock time, elapsed time), 是指一段程序从运行到终止,系统时钟走过的时间。一般来说,系统时间都是要大于CPU时间
最繁重的GC任务由多个专用的 worker 线程来执行。下面的日志描述了他们的行为:
[Parallel Time: 13.9 ms, GC Workers: 8] [GC Worker Start (ms): Min: 134.0, Avg: 134.1, Max: 134.1, Diff: 0.1] [Ext Root Scanning (ms): Min: 0.1, Avg: 0.2, Max: 0.3, Diff: 0.2, Sum: 1.2] [Update RS (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0] [Processed Buffers: Min: 0, Avg: 0.0, Max: 0, Diff: 0, Sum: 0] [Scan RS (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0] [Code Root Scanning (ms): Min: 0.0, Avg: 0.0, Max: 0.2, Diff: 0.2, Sum: 0.2] [Object Copy (ms): Min: 10.8, Avg: 12.1, Max: 12.6, Diff: 1.9, Sum: 96.5] [Termination (ms): Min: 0.8, Avg: 1.5, Max: 2.8, Diff: 1.9, Sum: 12.2] [Termination Attempts: Min: 173, Avg: 293.2, Max: 362, Diff: 189, Sum: 2346] [GC Worker Other (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.1] GC Worker Total (ms): Min: 13.7, Avg: 13.8, Max: 13.8, Diff: 0.1, Sum: 110.2] [GC Worker End (ms): Min: 147.8, Avg: 147.8, Max: 147.8, Diff: 0.0]
[Parallel Time: 13.9 ms, GC Workers: 8] – 表明下列活动由8个线程并行执行,消耗的时间为13.9毫秒(real time)。
[GC Worker Start (ms) – GC的worker线程开始启动时,相对于 pause 开始的时间戳。如果 Min 和 Max 差别很大,则表明本机其他进程所使用的线程数量过多, 挤占了GC的CPU时间。
[Ext Root Scanning (ms) – 用了多长时间来扫描堆外(non-heap)的root, 如 classloaders, JNI引用, JVM的系统root等。后面显示了运行时间, “Sum” 指的是CPU时间。
[Code Root Scanning (ms) – 用了多长时间来扫描实际代码中的 root: 例如局部变量等等(local vars)。
[Object Copy (ms) – 用了多长时间来拷贝收集区内的存活对象。
[Termination (ms) – GC的worker线程用了多长时间来确保自身可以安全地停止, 这段时间什么也不用做, stop 之后该线程就终止运行了。
[Termination Attempts – GC的worker 线程尝试多少次 try 和 teminate。如果worker发现还有一些任务没处理完,则这一次尝试就是失败的, 暂时还不能终止。
[GC Worker Other (ms) – 一些琐碎的小活动,在GC日志中不值得单独列出来。
GC Worker Total (ms) – GC的worker 线程的工作时间总计。
[GC Worker End (ms) – GC的worker 线程完成作业的时间戳。通常来说这部分数字应该大致相等, 否则就说明有太多的线程被挂起, 很可能是因为坏邻居效应(noisy neighbor) 所导致的。
此外,在转移暂停期间,还有一些琐碎执行的小活动。这里我们只介绍其中的一部分, 其余的会在后面进行讨论。
[Other: 0.4 ms] [Choose CSet: 0.0 ms] [Ref Proc: 0.2 ms] [Ref Enq: 0.0 ms] [Redirty Cards: 0.1 ms] [Humongous Register: 0.0 ms] [Humongous Reclaim: 0.0 ms] [Free CSet: 0.0 ms]
[Other: 0.4 ms] – 其他活动消耗的时间, 其中有很多也是并行执行的。
[Ref Proc: 0.2 ms] – 处理非强引用(non-strong)的时间: 进行清理或者决定是否需要清理。
[Ref Enq: 0.0 ms] – 用来将剩下的 non-strong 引用排列到合适的 ReferenceQueue中。
[Free CSet: 0.0 ms] – 将回收集中被释放的小堆归还所消耗的时间, 以便他们能用来分配新的对象。
Concurrent Marking(并发标记)
G1收集器的很多概念建立在CMS的基础上,所以下面的内容需要你对CMS有一定的理解. 虽然也有很多地方不同, 但并发标记的目标基本上是一样的. G1的并发标记通过 Snapshot-At-The-Beginning(开始时快照) 的方式, 在标记阶段开始时记下所有的存活对象。即使在标记的同时又有一些变成了垃圾. 通过对象是存活信息, 可以构建出每个小堆区的存活状态, 以便回收集能高效地进行选择。
这些信息在接下来的阶段会用来执行老年代区域的垃圾收集。在两种情况下是完全地并发执行的: 一、如果在标记阶段确定某个小堆区只包含垃圾; 二、在STW转移暂停期间, 同时包含垃圾和存活对象的老年代小堆区。
当堆内存的总体使用比例达到一定数值时,就会触发并发标记。默认值为 45%, 但也可以通过JVM参数 InitiatingHeapOccupancyPercent 来设置。和CMS一样, G1的并发标记也是由多个阶段组成, 其中一些是完全并发的, 还有一些阶段需要暂停应用线程。
阶段 1: Initial Mark(初始标记)。 此阶段标记所有从GC root 直接可达的对象。在CMS中需要一次STW暂停, 但G1里面通常是在转移暂停的同时处理这些事情, 所以它的开销是很小的. 可以在 Evacuation Pause 日志中的第一行看到(initial-mark)暂停:
1.631: [GC pause (G1 Evacuation Pause) (young) (initial-mark), 0.0062656 secs]
阶段 2: Root Region Scan(Root区扫描). 此阶段标记所有从 “根区域” 可达的存活对象。 根区域包括: 非空的区域, 以及在标记过程中不得不收集的区域。因为在并发标记的过程中迁移对象会造成很多麻烦, 所以此阶段必须在下一次转移暂停之前完成。如果必须启动转移暂停, 则会先要求根区域扫描中止, 等它完成才能继续扫描. 在当前版本的实现中, 根区域是存活的小堆区: y包括下一次转移暂停中肯定会被清理的那部分年轻代小堆区。
1.362: [GC concurrent-root-region-scan-start] 1.364: [GC concurrent-root-region-scan-end, 0.0028513 secs]
阶段 3: Concurrent Mark(并发标记). 此阶段非常类似于CMS: 它只是遍历对象图, 并在一个特殊的位图中标记能访问到的对象. 为了确保标记开始时的快照准确性, 所有应用线程并发对对象图执行的引用更新,G1 要求放弃前面阶段为了标记目的而引用的过时引用。
这是通过使用 Pre-Write 屏障来实现的,(不要和之后介绍的 Post-Write 混淆, 也不要和多线程开发中的内存屏障(memory barriers)相混淆)。Pre-Write屏障的作用是: G1在进行并发标记时, 如果程序将对象的某个属性做了变更, 就会在 log buffers 中存储之前的引用。 由并发标记线程负责处理。
1.364: [GC concurrent-mark-start] 1.645: [GC co ncurrent-mark-end, 0.2803470 secs]
阶段 4: Remark(再次标记). 和CMS类似,这也是一次STW停顿,以完成标记过程。对于G1,它短暂地停止应用线程, 停止并发更新日志的写入, 处理其中的少量信息, 并标记所有在并发标记开始时未被标记的存活对象。这一阶段也执行某些额外的清理, 如引用处理(参见 Evacuation Pause log) 或者类卸载(class unloading)。
1.645: [GC remark 1.645: [Finalize Marking, 0.0009461 secs] 1.646: [GC ref-proc, 0.0000417 secs] 1.646: [Unloading, 0.0011301 secs], 0.0074056 secs] [Times: user=0.01 sys=0.00, real=0.01 secs]
阶段 5: Cleanup(清理). 最后这个小阶段为即将到来的转移阶段做准备, 统计小堆区中所有存活的对象, 并将小堆区进行排序, 以提升GC的效率. 此阶段也为下一次标记执行所有必需的整理工作(house-keeping activities): 维护并发标记的内部状态。
最后要提醒的是, 所有不包含存活对象的小堆区在此阶段都被回收了。有一部分是并发的: 例如空堆区的回收,还有大部分的存活率计算, 此阶段也需要一个短暂的STW暂停, 以不受应用线程的影响来完成作业. 这种STW停顿的日志如下:
1.652: [GC cleanup 1213M->1213M(1885M), 0.0030492 secs] [Times: user=0.01 sys=0.00, real=0.00 secs]
如果发现某些小堆区中只包含垃圾, 则日志格式可能会有点不同, 如:
1.872: [GC cleanup 1357M->173M(1996M), 0.0015664 secs] [Times: user=0.01 sys=0.00, real=0.01 secs] 1.874: [GC concurrent-cleanup-start] 1.876: [GC concurrent-cleanup-end, 0.0014846 secs]
Evacuation Pause: Mixed (转移暂停: 混合模式)
能并发清理老年代中整个整个的小堆区是一种最优情形, 但有时候并不是这样。并发标记完成之后, G1将执行一次混合收集(mixed collection), 不只清理年轻代, 还将一部分老年代区域也加入到 collection set 中。
混合模式的转移暂停(Evacuation pause)不一定紧跟着并发标记阶段。有很多规则和历史数据会影响混合模式的启动时机。比如, 假若在老年代中可以并发地腾出很多的小堆区,就没有必要启动混合模式。
因此, 在并发标记与混合转移暂停之间, 很可能会存在多次 fully-young 转移暂停。
添加到回收集的老年代小堆区的具体数字及其顺序, 也是基于许多规则来判定的。 其中包括指定的软实时性能指标, 存活性,以及在并发标记期间收集的GC效率等数据, 外加一些可配置的JVM选项. 混合收集的过程, 很大程度上和前面的 fully-young gc 是一样的, 但这里我们还要介绍一个概念: remembered sets(历史记忆集)。
Remembered sets (历史记忆集)是用来支持不同的小堆区进行独立回收的。例如,在收集A、B、C区时, 我们必须要知道是否有从D区或者E区指向其中的引用, 以确定他们的存活性. 但是遍历整个堆需要相当长的时间, 这就违背了增量收集的初衷, 因此必须采取某种优化手段. 其他GC算法有独立的 Card Table 来支持年轻代的垃圾收集一样, 而G1中使用的是 Remembered Sets。
如下图所示, 每个小堆区都有一个 remembered set, 列出了从外部指向本区的所有引用。这些引用将被视为附加的 GC root. 注意,在并发标记过程中,老年代中被确定为垃圾的对象会被忽略, 即使有外部引用指向他们: 因为在这种情况下引用者也是垃圾。
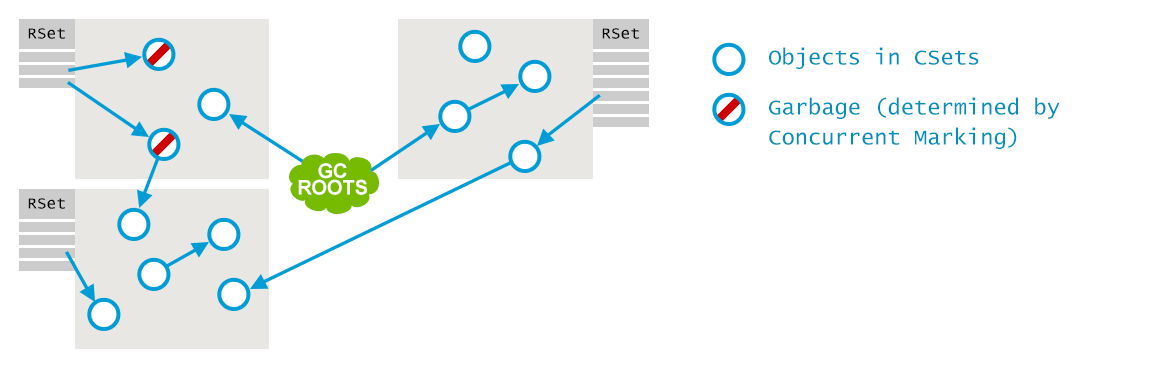
接下来的行为,和其他垃圾收集器一样: 多个GC线程并行地找出哪些是存活对象,确定哪些是垃圾:
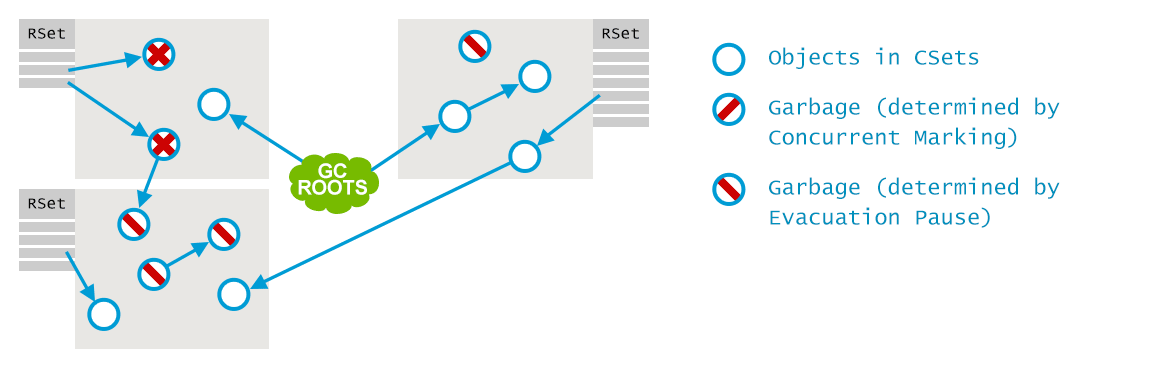
最后, 存活对象被转移到存活区(survivor regions), 在必要时会创建新的小堆区。现在,空的小堆区被释放, 可用于存放新的对象了。
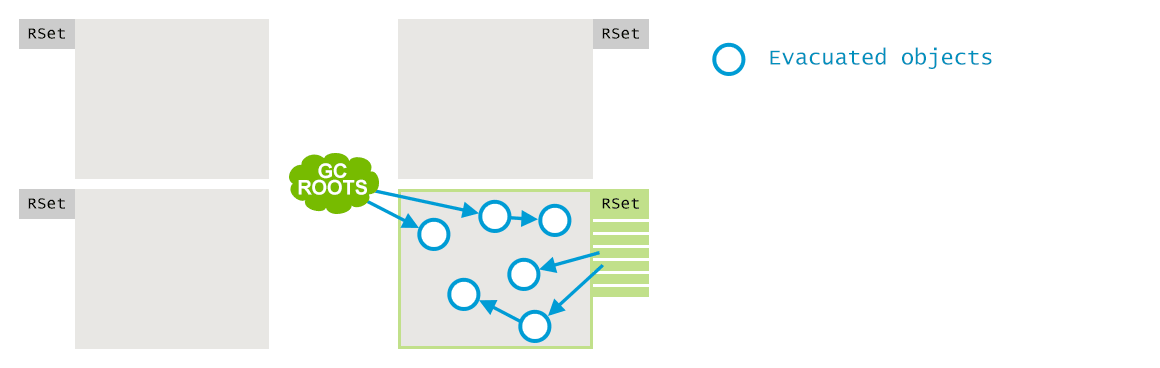
为了维护 remembered set, 在程序运行的过程中, 只要写入某个字段,就会产生一个 Post-Write 屏障。如果生成的引用是跨区域的(cross-region),即从一个区指向另一个区, 就会在目标区的Remembered Set中,出现一个对应的条目。为了减少 Write Barrier 造成的开销, 将卡片放入Remembered Set 的过程是异步的, 而且经过了很多的优化. 总体上是这样: Write Barrier 把脏卡信息存放到本地缓冲区(local buffer), 有专门的GC线程负责收集, 并将相关信息传给被引用区的 remembered set。
混合模式下的日志, 和纯年轻代模式相比, 可以发现一些有趣的地方:
[[Update RS (ms): Min: 0.7, Avg: 0.8, Max: 0.9, Diff: 0.2, Sum: 6.1] [Processed Buffers: Min: 0, Avg: 2.2, Max: 5, Diff: 5, Sum: 18] [Scan RS (ms): Min: 0.0, Avg: 0.1, Max: 0.2, Diff: 0.2, Sum: 0.8] [Clear CT: 0.2 ms] [Redirty Cards: 0.1 ms]
[Update RS (ms) – 因为 Remembered Sets 是并发处理的,必须确保在实际的垃圾收集之前, 缓冲区中的 card 得到处理。如果card数量很多, 则GC并发线程的负载可能就会很高。可能的原因是, 修改的字段过多, 或者CPU资源受限。
[Processed Buffers – 每个 worker 线程处理了多少个本地缓冲区(local buffer)。
[Scan RS (ms) – 用了多长时间扫描来自RSet的引用。
[Clear CT: 0.2 ms] – 清理 card table 中 cards 的时间。清理工作只是简单地删除“脏”状态, 此状态用来标识一个字段是否被更新的, 供Remembered Sets使用。
[Redirty Cards: 0.1 ms] – 将 card table 中适当的位置标记为 dirty 所花费的时间。”适当的位置”是由GC本身执行的堆内存改变所决定的, 例如引用排队等。
总结
通过本节内容的学习, 你应该对G1垃圾收集器有了一定了解。当然, 为了简洁, 我们省略了很多实现细节, 例如如何处理巨无霸对象(humongous objects)。 综合来看, G1是HotSpot中最先进的准产品级(production-ready)垃圾收集器。重要的是, HotSpot 工程师的主要精力都放在不断改进G1上面, 在新的java版本中,将会带来新的功能和优化。
可以看到, G1 解决了 CMS 中的各种疑难问题, 包括暂停时间的可预测性, 并终结了堆内存的碎片化。对单业务延迟非常敏感的系统来说, 如果CPU资源不受限制,那么G1可以说是 HotSpot 中最好的选择, 特别是在最新版本的Java虚拟机中。当然,这种降低延迟的优化也不是没有代价的: 由于额外的写屏障(write barriers)和更积极的守护线程, G1的开销会更大。所以, 如果系统属于吞吐量优先型的, 又或者CPU持续占用100%, 而又不在乎单次GC的暂停时间, 那么CMS是更好的选择。
总之: G1适合大内存,需要低延迟的场景。
选择正确的GC算法,唯一可行的方式就是去尝试,并找出不对劲的地方, 在下一章我们将给出一般指导原则。
注意,G1可能会成为Java 9的默认GC: http://openjdk.java.net/jeps/248
原文链接:http://plumbr.io/handbook/garbage-collection-algorithms-implementations#g1
加载全部内容