jvm垃圾回收GC调优
金色梦想 人气:0说明:
Capacity: 性能,能力,系统容量; 文中翻译为”系统容量“; 意为硬件配置。
GC调优(Tuning Garbage Collection)和其他性能调优是同样的原理。初学者可能会被 200 多个 GC参数弄得一头雾水, 然后随便调整几个来试试结果,又或者修改几行代码来测试。其实只要参照下面的步骤,就能保证你的调优方向正确:
- 列出性能调优指标(State your performance goals)
- 执行测试(Run tests)
- 检查结果(Measure the results)
- 与目标进行对比(Compare the results with the goals)
- 如果达不到指标, 修改配置参数, 然后继续测试(go back to running tests)
第一步, 我们需要做的事情就是: 制定明确的GC性能指标。对所有性能监控和管理来说, 有三个维度是通用的:
- Latency(延迟)
- Throughput(吞吐量)
- Capacity(系统容量)
我们先讲解基本概念,然后再演示如何使用这些指标。如果您对 延迟、吞吐量和系统容量等概念很熟悉, 可以跳过这一小节。
核心概念(Core Concepts)
我们先来看一家工厂的装配流水线。工人在流水线将现成的组件按顺序拼接,组装成自行车。通过实地观测, 我们发现从组件进入生产线,到另一端组装成自行车需要4小时。
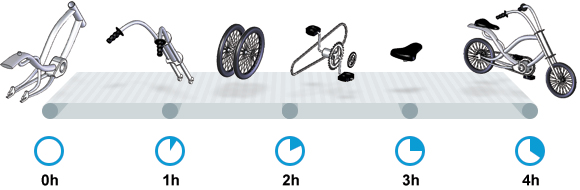
继续观察,我们还发现,此后每分钟就有1辆自行车完成组装, 每天24小时,一直如此。将这个模型简化, 并忽略维护窗口期后得出结论: 这条流水线每小时可以组装60辆自行车。
说明: 时间窗口/窗口期,请类比车站卖票的窗口,是一段规定/限定做某件事的时间段。
通过这两种测量方法, 就知道了生产线的相关性能信息: 延迟与吞吐量:
- 生产线的延迟: 4小时
- 生产线的吞吐量: 60辆/小时
请注意, 衡量延迟的时间单位根据具体需要而确定 —— 从纳秒(nanosecond)到几千年(millennia)都有可能。系统的吞吐量是每个单位时间内完成的操作。操作(Operations)一般是特定系统相关的东西。在本例中,选择的时间单位是小时, 操作就是对自行车的组装。
掌握了延迟和吞吐量两个概念之后, 让我们对这个工厂来进行实际的调优。自行车的需求在一段时间内都很稳定, 生产线组装自行车有四个小时延迟, 而吞吐量在几个月以来都很稳定: 60辆/小时。假设某个销售团队突然业绩暴涨, 对自行车的需求增加了1倍。客户每天需要的自行车不再是 60 24 = 1440辆, 而是 21440 = 2880辆/天。老板对工厂的产能不满意,想要做些调整以提升产能。
看起来总经理很容易得出正确的判断, 系统的延迟没法子进行处理 —— 他关注的是每天的自行车生产总量。得出这个结论以后, 假若工厂资金充足, 那么应该立即采取措施, 改善吞吐量以增加产能。
我们很快会看到, 这家工厂有两条相同的生产线。每条生产线一分钟可以组装一辆成品自行车。 可以想象,每天生产的自行车数量会增加一倍。达到 2880辆/天。要注意的是, 不需要减少自行车的装配时间 —— 从开始到结束依然需要 4 小时。
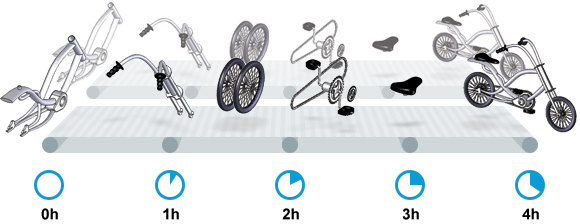
巧合的是,这样进行的性能优化,同时增加了吞吐量和产能。一般来说,我们会先测量当前的系统性能, 再设定新目标, 只优化系统的某个方面来满足性能指标。
在这里做了一个很重要的决定 —— 要增加吞吐量,而不是减小延迟。在增加吞吐量的同时, 也需要增加系统容量。比起原来的情况, 现在需要两条流水线来生产出所需的自行车。在这种情况下, 增加系统的吞吐量并不是免费的, 需要水平扩展, 以满足增加的吞吐量需求。
在处理性能问题时, 应该考虑到还有另一种看似不相关的解决办法。假如生产线的延迟从1分钟降低为30秒,那么吞吐量同样可以增长 1 倍。
或者是降低延迟, 或者是客户非常有钱。软件工程里有一种相似的说法 —— 每个性能问题背后,总有两种不同的解决办法。 可以用更多的机器, 或者是花精力来改善性能低下的代码。
Latency(延迟)
GC的延迟指标由一般的延迟需求决定。延迟指标通常如下所述:
- 所有交易必须在10秒内得到响应
- 90%的订单付款操作必须在3秒以内处理完成
- 推荐商品必须在 100 ms 内展示到用户面前
面对这类性能指标时, 需要确保在交易过程中, GC暂停不能占用太多时间,否则就满足不了指标。“不能占用太多” 的意思需要视具体情况而定, 还要考虑到其他因素, 比如外部数据源的交互时间(round-trips), 锁竞争(lock contention), 以及其他的安全点等等。
假设性能需求为: 90%的交易要在 1000ms 以内完成, 每次交易最长不能超过 10秒。 根据经验, 假设GC暂停时间比例不能超过10%。 也就是说, 90%的GC暂停必须在 100ms 内结束, 也不能有超过 1000ms 的GC暂停。为简单起见, 我们忽略在同一次交易过程中发生多次GC停顿的可能性。
有了正式的需求,下一步就是检查暂停时间。有许多工具可以使用, 在接下来的 6. GC 调优(工具篇) 中会进行详细的介绍, 在本节中我们通过查看GC日志, 检查一下GC暂停的时间。相关的信息散落在不同的日志片段中, 看下面的数据:
****-06-04T13:34:16.974-0200: 2.578: [Full GC (Ergonomics) [PSYoungGen: 93677K->70109K(254976K)] [ParOldGen: 499597K->511230K(761856K)] 593275K->581339K(1016832K), [Metaspace: 2936K->2936K(1056768K)] , 0.0713174 secs] [Times: user=0.21 sys=0.02, real=0.07 secs
这表示一次GC暂停, 在 ****-06-04T13:34:16 这个时刻触发. 对应于JVM启动之后的 2,578 ms。
此事件将应用线程暂停了 0.0713174 秒。虽然花费的总时间为 210 ms, 但因为是多核CPU机器, 所以最重要的数字是应用线程被暂停的总时间, 这里使用的是并行GC, 所以暂停时间大约为 70ms 。 这次GC的暂停时间小于 100ms 的阈值,满足需求。
继续分析, 从所有GC日志中提取出暂停相关的数据, 汇总之后就可以得知是否满足需求。
Throughput(吞吐量)
吞吐量和延迟指标有很大区别。当然两者都是根据一般吞吐量需求而得出的。一般吞吐量需求(Generic requirements for throughput) 类似这样:
- 解决方案每天必须处理 100万个订单
- 解决方案必须支持1000个登录用户,同时在5-10秒内执行某个操作: A、B或C
- 每周对所有客户进行统计, 时间不能超过6小时,时间窗口为每周日晚12点到次日6点之间。
可以看出,吞吐量需求不是针对单个操作的, 而是在给定的时间内, 系统必须完成多少个操作。和延迟需求类似, GC调优也需要确定GC行为所消耗的总时间。每个系统能接受的时间不同, 一般来说, GC占用的总时间比不能超过 10%。
现在假设需求为: 每分钟处理 1000 笔交易。同时, 每分钟GC暂停的总时间不能超过6秒(即10%)。
有了正式的需求, 下一步就是获取相关的信息。依然是从GC日志中提取数据, 可以看到类似这样的信息:
****-06-04T13:34:16.974-0200: 2.578: [Full GC (Ergonomics) [PSYoungGen: 93677K->70109K(254976K)] [ParOldGen: 499597K->511230K(761856K)] 593275K->581339K(1016832K), [Metaspace: 2936K->2936K(1056768K)], 0.0713174 secs] [Times: user=0.21 sys=0.02, real=0.07 secs
此时我们对 用户耗时(user)和系统耗时(sys)感兴趣, 而不关心实际耗时(real)。在这里, 我们关心的时间为 0.23s(user + sys = 0.21 + 0.02 s), 这段时间内, GC暂停占用了 cpu 资源。 重要的是, 系统运行在多核机器上, 转换为实际的停顿时间(stop-the-world)为 0.0713174秒, 下面的计算会用到这个数字。
提取出有用的信息后, 剩下要做的就是统计每分钟内GC暂停的总时间。看看是否满足需求: 每分钟内总的暂停时间不得超过6000毫秒(6秒)。
Capacity(系统容量)
系统容量(Capacity)需求,是在达成吞吐量和延迟指标的情况下,对硬件环境的额外约束。这类需求大多是来源于计算资源或者预算方面的原因。例如:
- 系统必须能部署到小于512 MB内存的Android设备上
- 系统必须部署在Amazon EC2实例上, 配置不得超过 c3.xlarge(4核8GB)。
- 每月的 Amazon EC2 账单不得超过
$12,000
因此, 在满足延迟和吞吐量需求的基础上必须考虑系统容量。可以说, 假若有无限的计算资源可供挥霍, 那么任何 延迟和吞吐量指标 都不成问题, 但现实情况是, 预算(budget)和其他约束限制了可用的资源。
相关示例
介绍完性能调优的三个维度后, 我们来进行实际的操作以达成GC性能指标。
请看下面的代码:
//imports skipped for brevity
public class Producer implements Runnable {
private static ScheduledExecutorService executorService
= Executors.newScheduledThreadPool(2);
private Deque<byte[]> deque;
private int objectSize;
private int queueSize;
public Producer(int objectSize, int ttl) {
this.deque = new ArrayDeque<byte[]>();
this.objectSize = objectSize;
this.queueSize = ttl * 1000;
}
@Override
public void run() {
for (int i = 0; i < 100; i++) {
deque.add(new byte[objectSize]);
if (deque.size() > queueSize) {
deque.poll();
}
}
}
public static void main(String[] args)
throws InterruptedException {
executorService.scheduleAtFixedRate(
new Producer(200 * 1024 * 1024 / 1000, 5),
0, 100, TimeUnit.MILLISECONDS
);
executorService.scheduleAtFixedRate(
new Producer(50 * 1024 * 1024 / 1000, 120),
0, 100, TimeUnit.MILLISECONDS);
TimeUnit.MINUTES.sleep(10);
executorService.shutdownNow();
}
}这段程序代码, 每 100毫秒 提交两个作业(job)来。每个作业都模拟特定的生命周期: 创建对象, 然后在预定的时间释放, 接着就不管了, 由GC来自动回收占用的内存。
在运行这个示例程序时,通过以下JVM参数打开GC日志记录:
-XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps
还应该加上JVM参数 -Xloggc以指定GC日志的存储位置,类似这样:
-Xloggc:C:\\Producer_gc.log
在日志文件中可以看到GC的行为, 类似下面这样:
****-06-04T13:34:16.119-0200: 1.723: [GC (Allocation Failure)
[PSYoungGen: 114016K->73191K(234496K)]
421540K->421269K(745984K),
0.0858176 secs]
[Times: user=0.04 sys=0.06, real=0.09 secs]
****-06-04T13:34:16.738-0200: 2.342: [GC (Allocation Failure)
[PSYoungGen: 234462K->93677K(254976K)]
582540K->593275K(766464K),
0.2357086 secs]
[Times: user=0.11 sys=0.14, real=0.24 secs]
****-06-04T13:34:16.974-0200: 2.578: [Full GC (Ergonomics)
[PSYoungGen: 93677K->70109K(254976K)]
[ParOldGen: 499597K->511230K(761856K)]
593275K->581339K(1016832K),
[Metaspace: 2936K->2936K(1056768K)],
0.0713174 secs]
[Times: user=0.21 sys=0.02, real=0.07 secs]基于日志中的信息, 可以通过三个优化目标来提升性能:
- 确保最坏情况下,GC暂停时间不超过预定阀值
- 确保线程暂停的总时间不超过预定阀值
- 在确保达到延迟和吞吐量指标的情况下, 降低硬件配置以及成本。
为此, 用三种不同的配置, 将代码运行10分钟, 得到了三种不同的结果, 汇总如下:
| 堆内存大小(Heap) | GC算法(GC Algorithm) | 有效时间比(Useful work) | 最长停顿时间(Longest pause) |
|---|---|---|---|
| -Xmx12g | -XX:+UseConcMarkSweepGC | 89.8% | 560 ms |
| -Xmx12g | -XX:+UseParallelGC | 91.5% | 1,104 ms |
| -Xmx8g | -XX:+UseConcMarkSweepGC | 66.3% | 1,610 ms |
使用不同的GC算法,和不同的内存配置,运行相同的代码, 以测量GC暂停时间与 延迟、吞吐量的关系。实验的细节和结果在后面章节详细介绍。
注意, 为了尽量简单, 示例中只改变了很少的输入参数, 此实验也没有在不同CPU数量或者不同的堆布局下进行测试。
Tuning for Latency(调优延迟指标)
假设有一个需求, 每次作业必须在 1000ms 内处理完成。我们知道, 实际的作业处理只需要100 ms,简化后, 两者相减就可以算出对 GC暂停的延迟要求。现在需求变成: GC暂停不能超过900ms。这个问题很容易找到答案, 只需要解析GC日志文件, 并找出GC暂停中最大的那个暂停时间即可。
再来看测试所用的三个配置:
| 堆内存大小(Heap) | GC算法(GC Algorithm) | 有效时间比(Useful work) | 最长停顿时间(Longest pause) |
|---|---|---|---|
| -Xmx12g | -XX:+UseConcMarkSweepGC | 89.8% | 560 ms |
| -Xmx12g | -XX:+UseParallelGC | 91.5% | 1,104 ms |
| -Xmx8g | -XX:+UseConcMarkSweepGC | 66.3% | 1,610 ms |
可以看到,其中有一个配置达到了要求。运行的参数为:
java -Xmx12g -XX:+UseConcMarkSweepGC Producer
对应的GC日志中,暂停时间最大为 560 ms, 这达到了延迟指标 900 ms 的要求。如果还满足吞吐量和系统容量需求的话,就可以说成功达成了GC调优目标, 调优结束。
Tuning for Throughput(吞吐量调优)
假定吞吐量指标为: 每小时完成 1300万次操作处理。同样是上面的配置, 其中有一种配置满足了需求:
| 堆内存大小(Heap) | GC算法(GC Algorithm) | 有效时间比(Useful work) | 最长停顿时间(Longest pause) |
|---|---|---|---|
| -Xmx12g | -XX:+UseConcMarkSweepGC | 89.8% | 560 ms |
| -Xmx12g | -XX:+UseParallelGC | 91.5% | 1,104 ms |
| -Xmx8g | -XX:+UseConcMarkSweepGC | 66.3% | 1,610 ms |
此配置对应的命令行参数为:
java -Xmx12g -XX:+UseParallelGC Producer
可以看到,GC占用了 8.5%的CPU时间,剩下的 91.5% 是有效的计算时间。为简单起见, 忽略示例中的其他安全点。现在需要考虑:
- 每个CPU核心处理一次作业需要耗时 100ms
- 因此, 一分钟内每个核心可以执行 60,000 次操作(每个job完成100次操作)
- 一小时内, 一个核心可以执行 360万次操作
- 有四个CPU内核, 则每小时可以执行: 4 x 3.6M = 1440万次操作
理论上,通过简单的计算就可以得出结论, 每小时可以执行的操作数为: 次, 满足需求。
值得一提的是, 假若还要满足延迟指标, 那就有问题了, 最坏情况下, GC暂停时间为 1,104 ms最大延迟时间是前一种配置的两倍。
Tuning for Capacity(调优系统容量)
假设需要将软件部署到服务器上(commodity-class hardware), 配置为 4核10G。这样的话, 系统容量的要求就变成: 最大的堆内存空间不能超过 8GB有了这个需求, 我们需要调整为第三套配置进行测试:
| 堆内存大小(Heap) | GC算法(GC Algorithm) | 有效时间比(Useful work) | 最长停顿时间(Longest pause) |
|---|---|---|---|
| -Xmx12g | -XX:+UseConcMarkSweepGC | 89.8% | 560 ms |
| -Xmx12g | -XX:+UseParallelGC | 91.5% | 1,104 ms |
| -Xmx8g | -XX:+UseConcMarkSweepGC | 66.3% | 1,610 ms |
程序可以通过如下参数执行:
java -Xmx8g -XX:+UseConcMarkSweepGC Producer
测试结果是延迟大幅增长, 吞吐量同样大幅降低:
- 现在,GC占用了更多的CPU资源, 这个配置只有 66.3%的有效CPU时间。因此,这个配置让吞吐量从最好的情况 13,176,000 操作/小时 下降到 不足 9,547,200次操作/小时.
- 最坏情况下的延迟变成了 1,610 ms, 而不再是 560ms。
通过对这三个维度的介绍, 你应该了解, 不是简单的进行“性能(performance)”优化, 而是需要从三种不同的维度来进行考虑, 测量, 并调优延迟和吞吐量, 此外还需要考虑系统容量的约束。
原文链接:http://plumbr.io/handbook/gc-tuning加载全部内容