Java操作hdfs文件系统
小码农叔叔 人气:01.前置准备
- 默认服务器上的
hadoop服务已经启动 - 本地如果是
windows环境,需要本地配置下hadoop的环境变量
本地配置hadoop的环境变量:
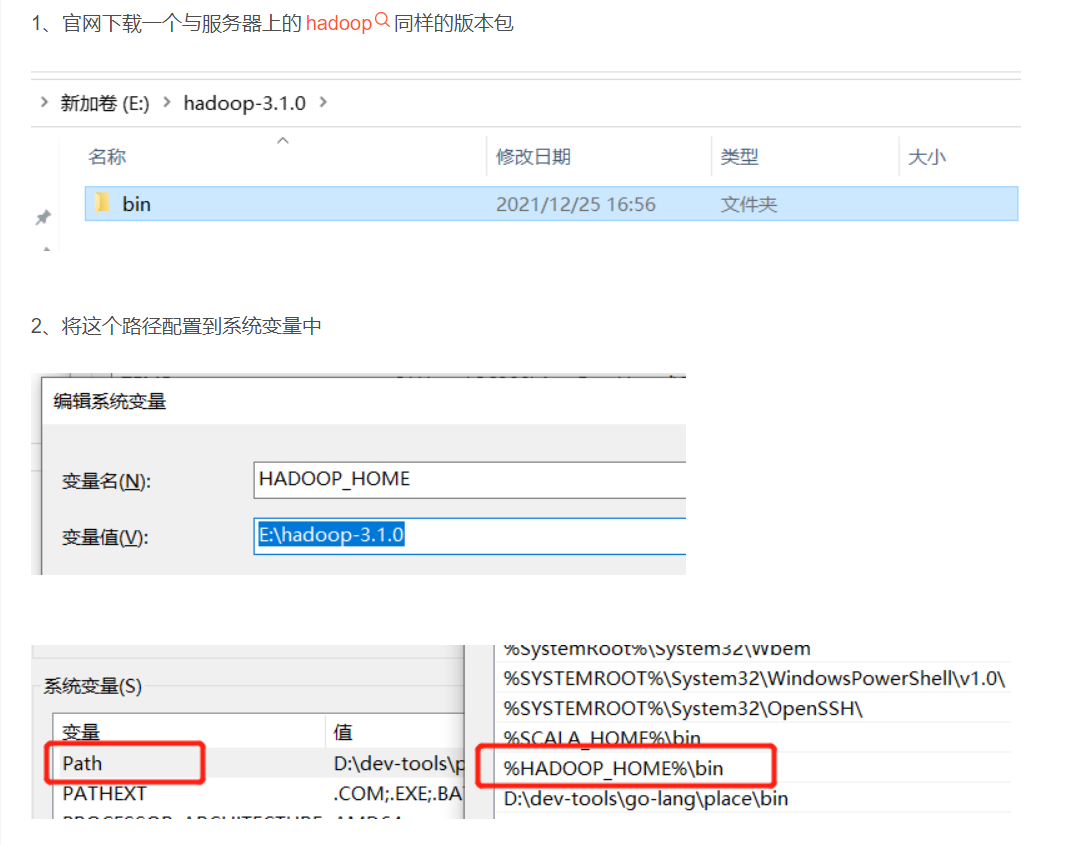
2.编码环境前置准备
使用idea快速构建一个springoot的工程:
1、导入maven依赖
<dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>3.1.3</version> </dependency> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.12</version> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> <version>1.7.30</version> </dependency>
2、添加一个log4j.properties 文件
为方便输出日志,在springoot工程的resources目录下添加一个log4j.properties 文件
log4j.rootLogger=INFO, stdout log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n log4j.appender.logfile=org.apache.log4j.FileAppender log4j.appender.logfile.File=target/spring.log log4j.appender.logfile.layout=org.apache.log4j.PatternLayout log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
以上所有的前置准备和代码运行环境就准备完毕了,下面就开始具体的API编码操作hdfs文件
3.API使用环节
1、创建hdfs文件目录
public class HdfsClientTest {
static Configuration configuration = null;
static FileSystem fs = null;
static {
configuration = new Configuration();
configuration.set("dfs.client.use.datanode.hostname", "true");
try {
fs = FileSystem.get(new URI("hdfs://IP:9000"), configuration, "hadoop");
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (URISyntaxException e) {
e.printStackTrace();
}
}
/**
* 创建目录
*/
public static void mkDir(String dirName){
try {
fs.mkdirs(new Path(dirName));
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) throws Exception {
//创建文件目录
mkDir("/songguo");
fs.close();
}
} 运行这段程序,然后去web页面观察是否创建成功
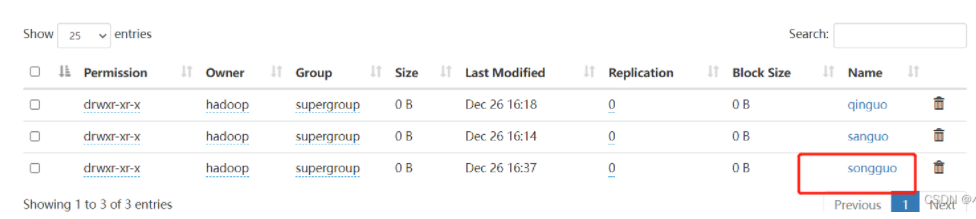
2、上传文件到hdfs文件目录
/**
* 上传文件到hdfs
*/
public static void uploadFile(String localPath,String hdfsPath){
try {
fs.copyFromLocalFile(new Path(localPath), new Path(hdfsPath));
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) throws Exception {
//创建文件目录
//mkDir("/songguo");
//上传文件到hdfs
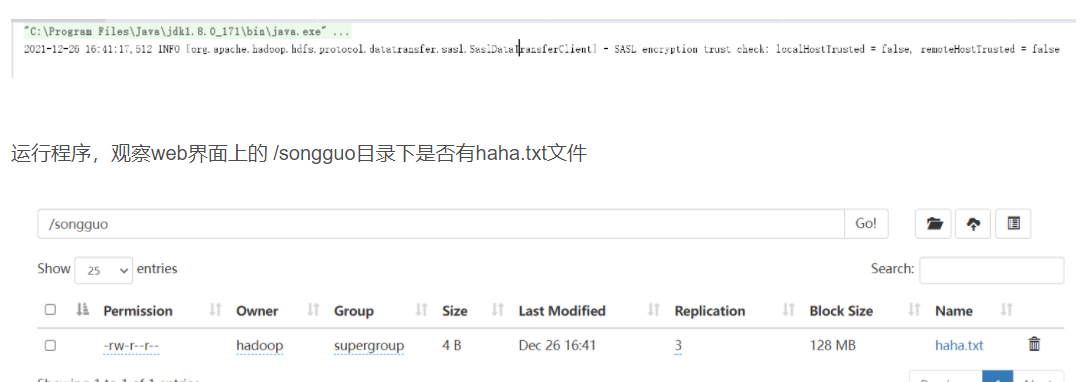
uploadFile("E:\\haha.txt", "/songguo");
fs.close();
}
3、从hdfs上面下载文件到本地
/**
* 从hdfs上面下载文件到本地
*/
public static void loadFileFromDfs(String localPath,String hdfsPath){
try {
fs.copyToLocalFile(false,new Path(hdfsPath),new Path(localPath),false);
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) throws Exception {
//创建文件目录
//mkDir("/songguo");
//上传文件到hdfs
//uploadFile("E:\\haha.txt", "/songguo");
//从hdfs上面下载文件到本地
loadFileFromDfs("E:\\haha_1.txt","/songguo/haha.txt");
fs.close();
}运行这段程序,观察E盘下是否成功下载到haha_1.txt文件

4、删除hdfs文件
/**
* 删除hdfs文件
* @param hdfsPath 文件路径
* @param recuDelete 是否递归删除
*/
public static void deleteFile(String hdfsPath,boolean recuDelete){
try {
fs.delete(new Path(hdfsPath),recuDelete);
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) throws Exception {
//删除文件
deleteFile("/songguo/haha.txt",false);
fs.close();
}运行程序,观察web界面的 /songguo目录下文件是否被删除

5、修改hdfs文件名称
/**
* 文件重命名
* @param sourceFilePath
* @param targetFilePath
*/
public static void renameFile(String sourceFilePath,String targetFilePath){
try {
fs.rename(new Path(sourceFilePath),new Path(targetFilePath));
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) throws Exception {
//文件重命名
renameFile("/qinguo/haha.txt","/qinguo/haha_rename.txt");
fs.close();
}在 /qinguo 目录下有一个haha.txt文件,我们对它进行重命名操作,运行上面的代码

6、移动同时修改hdfs文件名称
这个和上面的API一样,仍然使用rename即可,比如将/songuo/haha_rename.txt 移动到 /sanguo目录下 ,只需要在传入的参数上面更改即可
//文件重命名
renameFile("/qinguo/haha_rename.txt","/sanguo/haha.txt");
上面是目录下的具体文件的更名和移动操作,对hdfs文件目录同样适用
7、文件查看相关
查看文件目录:
public static void main(String[] args) throws Exception {
RemoteIterator<LocatedFileStatus> files = fs.listFiles(new Path("/"), true);
while (files.hasNext()){
//迭代目录下的具体的文件信息
LocatedFileStatus fileStatus= files.next();
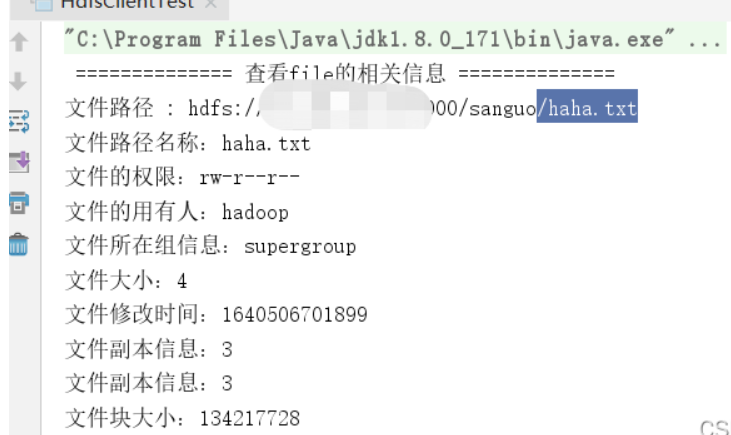
System.out.println(" ============== 查看file的相关信息 ==============");
System.out.println("文件路径 : "+ fileStatus.getPath() );
System.out.println("文件路径名称:" + fileStatus.getPath().getName());
System.out.println("文件的权限:" + fileStatus.getPermission());
System.out.println("文件的用有人:" + fileStatus.getOwner());
System.out.println("文件所在组信息:" + fileStatus.getGroup());
System.out.println("文件大小:" + fileStatus.getLen());
System.out.println("文件修改时间:" + fileStatus.getModificationTime());
System.out.println("文件副本信息:" + fileStatus.getReplication());
System.out.println("文件副本信息:" + fileStatus.getReplication());
System.out.println("文件块大小:" + fileStatus.getBlockSize());
}
fs.close();
}
当然,关于文件信息,hdfs还有更加丰富的信息展示,有兴趣的同学可以参考官网资料查看
8、hdfs文件与文件夹的判断
从目前对hdfs的了解,我们知道文件和文件夹是有区别的,下面来看如何使用api来进行判断
public static void main(String[] args) throws Exception {
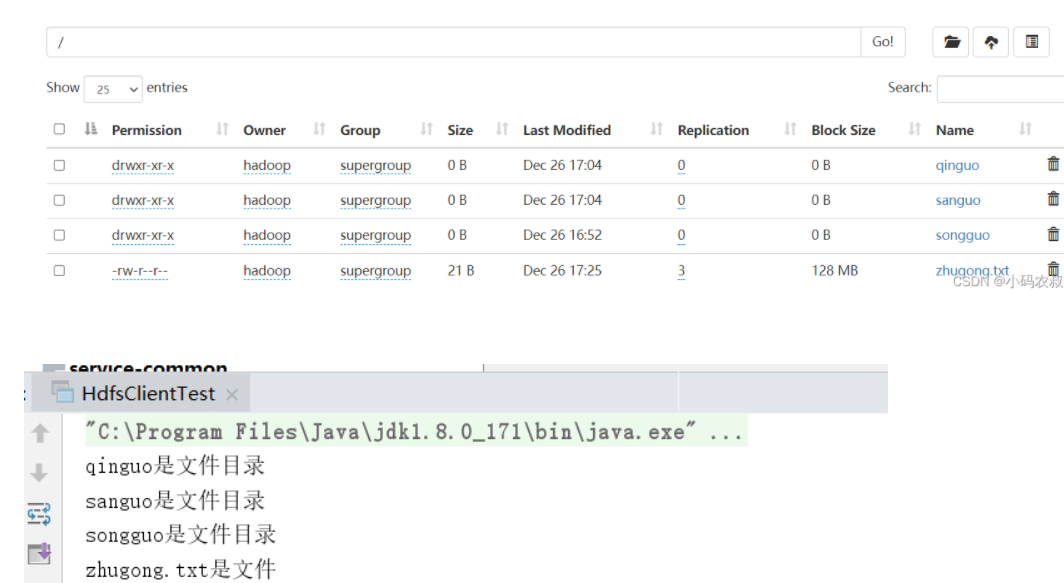
FileStatus[] fileStatuses = fs.listStatus(new Path("/"));
for (FileStatus fileStatus : fileStatuses) {
boolean directory = fileStatus.isDirectory();
if(directory){
System.out.println(fileStatus.getPath().getName() + "是文件目录");
}
boolean file = fileStatus.isFile();
if(file){
System.out.println(fileStatus.getPath().getName() + "是文件");
}
}
fs.close();
}可以看到,在根目录下有3个目录,和一个文件,运行这段程序,看是否能给出正确的判断呢
通过以上内容,我们基本上了解了如何基于JavaAPI 对hdfs文件系统的常用操作,也是工作中经常会打交道的内容之一,更多的内容可以在此基础上继续深究
4.整合Java 客户端过程中遇到的几个坑
事实上,真正在idea中编写代码实现的时候,并非这么顺利,遇到了不少坑,下面分享几个本次编写代码过程的几个坑点,希望看到的同学可以合理规避开
1、运行程序直接报无法连接问题
解决方案:
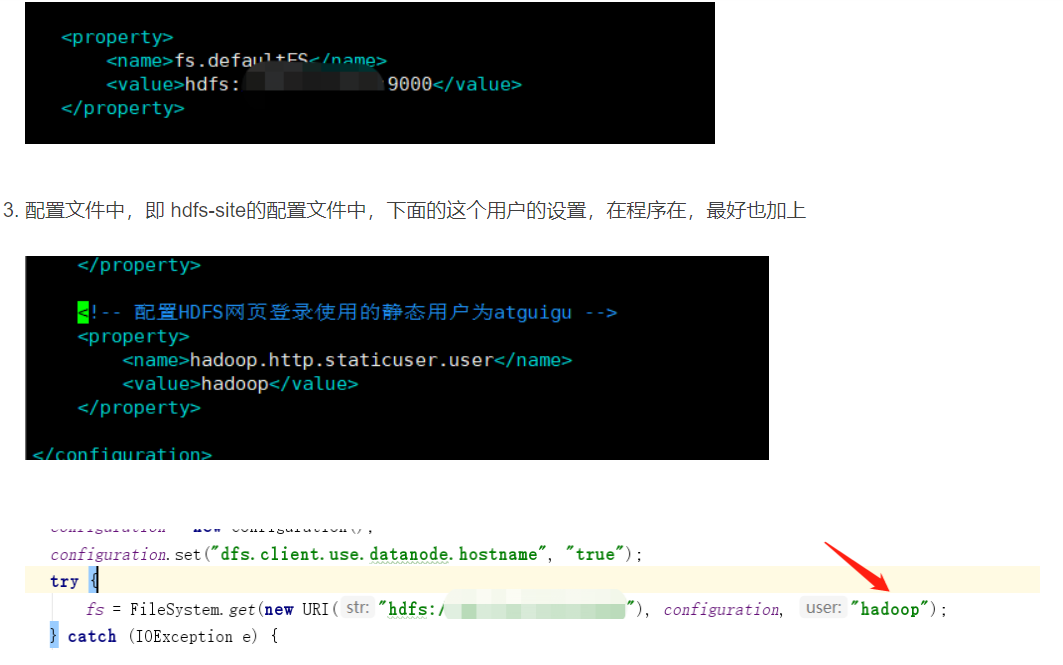
1.在configuration那里的地址,一定要确认和hdfs里面的 dataNode的那里的配置保持一致

2.如果使用的是阿里云或腾讯云,那么在 hdfs-site下面这里,填上内网地址吧【生产环境下不建议这么做】,反正我是碰到了
2、上传文件情况
上传文件到hdfs目录下,能上传,但是上传上去的文件为空,并且控制台报错
报错信息如下:
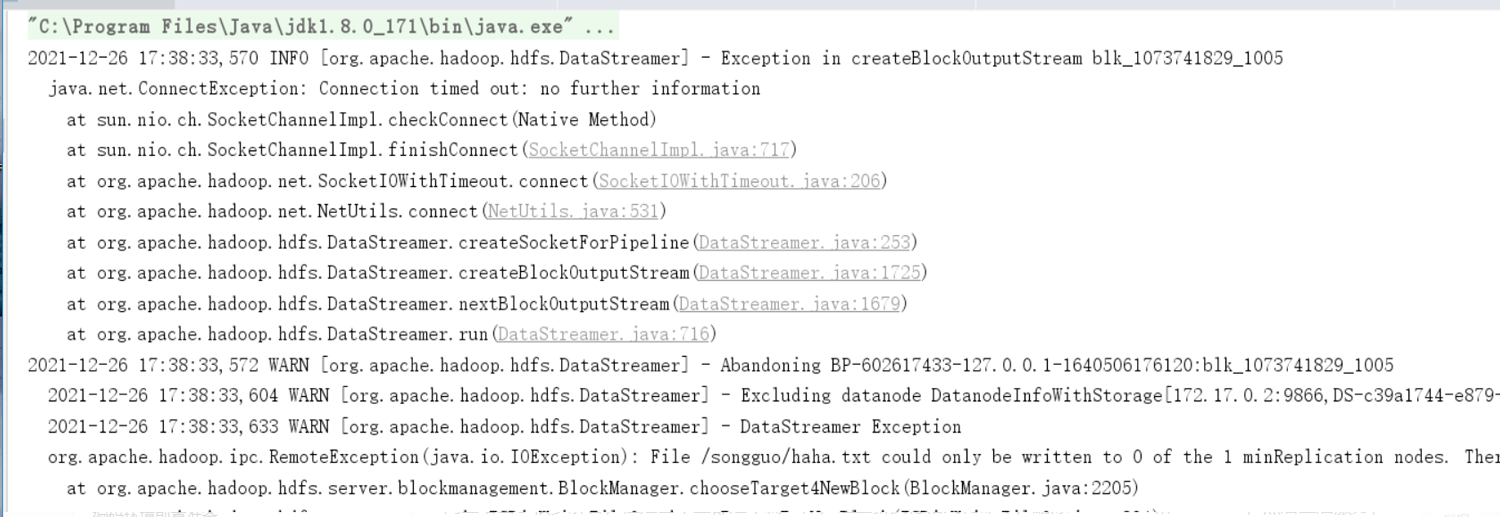
其中比较关键的错误内容是下面这行:
org.apache.hadoop.ipc.RemoteException(java.io.IOException): File /songguo/haha.txt could only be written to 0 of the 1 minReplication nodes. There are 1 datanode(s) running and 1 node(s) are excluded in this operation.
at org.apache.hadoop.hdfs.server.blockmanagement.BlockManager.chooseTarget4NewBlock(BlockManager.java:2205)
网上给出了很多解答,但是基本上都是千篇一律,让重新执行格式化命令,删除namenode和datanode,然后重启服务,其实只需要在代码中的configuration那里添加下面一行代码配置即可
configuration.set("dfs.client.use.datanode.hostname", "true");直接给出我们的分析结果:
NameNode节点存放的是文件目录,也就是文件夹、文件名称,本地可以通过公网访问 NameNode,所以可以进行文件夹的创建,当上传文件需要写入数据到DataNode时,NameNode 和DataNode 是通过局域网进行通信,NameNode返回地址为 DataNode 的私有 IP,本地无法访问
返回的IP地址无法返回公网IP,只能返回主机名,通过主机名与公网地址的映射便可以访问到DataNode节点,问题将解决。
由于代码的设置的优先级为最高,所以直接进行代码的设置
加载全部内容