PyTorch部署模型
ronghuaiyang 人气:0导读
演示了使用PyTorch最近发布的新工具torchserve来进行PyTorch模型的部署。

最近,PyTorch推出了名为torchserve.的新生产框架来为模型提供服务。我们看一下今天的roadmap:
1、使用Docker安装
2、导出模型
3、定义handler
4、保存模型
为了展示torchserve,我们将提供一个经过全面训练的ResNet34进行图像分类的服务。
使用Docker安装
官方文档:https://github.com/pytorch/serve/blob/master/README.md##install-torchserve
安装torchserve最好的方法是使用docker。你只需要把镜像拉下来。
可以使用以下命令保存最新的镜像。
docker pull pytorch/torchserve:latest
所有可用的tags:https://hub.docker.com/r/pytorch/torchserve/tags
关于docker和torchserve的更多信息:https://github.com/pytorch/serve#quick-start-with-docker
Handlers
官方文档:https://github.com/pytorch/serve/blob/master/docs/custom_service.md
处理程序负责使用模型对一个或多个HTTP请求进行预测。
默认 handlers
Torchserve支持以下默认 handlers
image_classifierobject_detectortext_classifierimage_segmenter
但是请记住,它们都不支持batching请求!
自定义 handlers
torchserve提供了一个丰富的接口,可以做几乎所有你想做的事情。一个Handler是一个必须有三个函数的类。
- preprocess
- inference
- postprocess
你可以创建你自己的类或者子类BaseHandler。子类化BaseHandler 的主要优点是可以在self.model上访问加载的模型。下面的代码片段展示了如何子类化BaseHandler。

子类化BaseHandler以创建自己的handler
回到图像分类的例子。我们需要
- 从每个请求中获取图像并对其进行预处理
- 从模型中得到预测
- 发送回一个响应
预处理
.preprocess函数接受请求数组。假设我们正在向服务器发送一个图像,可以从请求的data或body字段访问序列化的图像。因此,我们可以遍历所有请求并单独预处理每个图像。完整的代码如下所示。
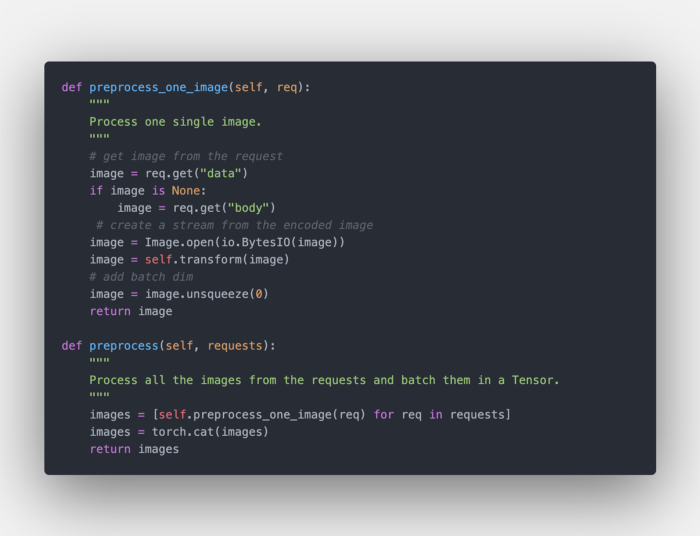
预处理每个请求中的每个图像
self.transform是我们的预处理变换,没什么花哨的。对于在ImageNet上训练的模型来说,这是一个经典的预处理步骤。
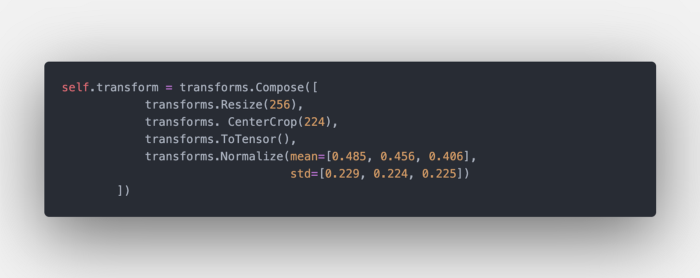
我们的transform
在我们对每个请求中的每个图像进行预处理之后,我们将它们连接起来创建一个pytorch张量。
推理

在模型上进行推理
这一步很简单,我们从 .preprocess得到张量。然后对每幅图像提取预测结果。
后处理
现在我们有了对每个图像的预测,我们需要向客户返回一些内容。Torchserve总是返回一个数组。BaseHandler也会自动打开一个.json 文件带有index -> label的映射(稍后我们将看到如何提供这样的文件),并将其存储self.mapping中。我们可以为每个预测返回一个字典数组,其中包含label和index 的类别。

把所有的东西打包到一起,我们的handler是这样的:

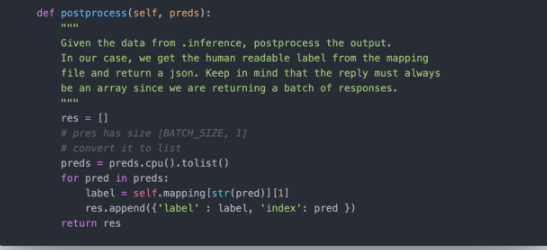
因为所有的处理逻辑都封装在一个类中,所以你可以轻松地对它进行单元测试!
导出你的模型
官方文档:https://github.com/pytorch/serve/tree/master/model-archiver#creating-a-model-archive
Torchserve 需要提供一个.mar文件,简而言之,该文件只是把你的模型和所有依赖打包在一起。要进行打包,首先需要导出经过训练的模型。
导出模型
有三种方法可以导出torchserve的模型。到目前为止,我发现的最好的方法是trace模型并存储结果。这样我们就不需要向torchserve添加任何额外的文件。
让我们来看一个例子,我们将部署一个经过充分训练的ResNet34模型。
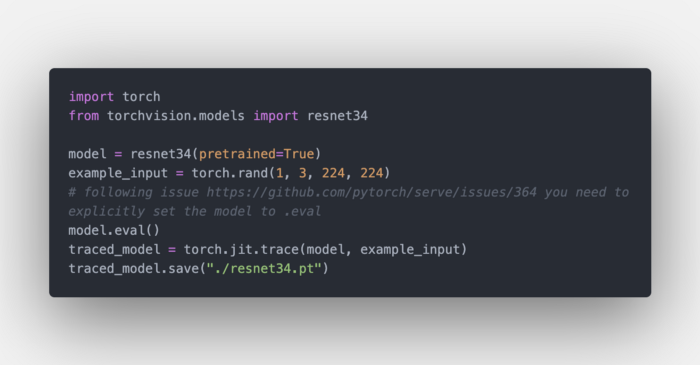
按照顺序,我们:
- 加载模型
- 创建一个dummy输入
- 使用
torch.jit.trace来trace模型的输入 - 保存模型
创建 .mar 文件
官方文档:https://github.com/pytorch/serve/blob/master/model-archiver/README.md
你需要安装torch-model-archiver
git clone https://github.com/pytorch/serve.git cd serve/model-archiver pip install .
然后,我们准备好通过使用下面的命令来创建.mar文件。
torch-model-archiver --model-name resnet34 \--version 1.0 \--serialized-file resnet34.pt \--extra-files ./index_to_name.json,./MyHandler.py \--handler my_handler.py \--export-path model-store -f
按照顺序。变量--model-name定义了模型的最终名称。这是非常重要的,因为它将是endpoint的名称空间,负责进行预测。你还可以指定一个--version。--serialized-file指向我们之前创建的存储的 .pt模型。--handler 是一个python文件,我们在其中调用我们的自定义handler。一般来说,是这样的:
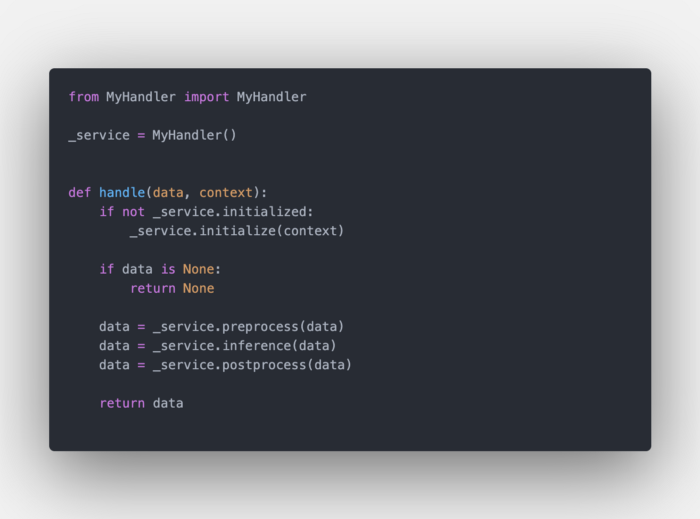
my_handler.py
它暴露了一个handle函数,我们从该函数调用自定义handler中的方法。你可以使用默认名称来使用默认handler(例如,--handler image_classifier)。
在--extra-files中,你需要将路径传递给你的handlers正在使用的所有文件。在本例中,我们必须向.json文件中添加路径。使用所有人类可读标签名称,并在MyHandler.py 中定义每个类别。
如果你传递一个index_to_name.json文件,它将自动加载到handler ,并通过self.mapping访问。
--export-path就是 .mar存放的地方,我还添加了-f来覆盖原有的文件。
如果一切顺利的话,你可以看到resnet34.mar存放在./model-store路径中。
用模型进行服务
这是一个简单的步骤,我们可以运行带有所有必需参数的torchserve docker容器。
docker run --rm -it \-p 3000:8080 -p 3001:8081 \-v $(pwd)/model-store:/home/model-server/model-store pytorch/torchserve:0.1-cpu \torchserve --start --model-store model-store --models resnet34=resnet34.mar
我将容器端口8080和8081分别绑定到3000和3001(8080/8081已经在我的机器中使用)。然后,我从./model-store 创建一个volume。最后,我通过padding model-store并通过key-value列表的方式指定模型的名称来调用torchserve。
这里,torchserve有一个endpoint /predictions/resnet34,我们可以通过发送图像来预测。这可以使用curl来实现。
curl -X POST http://127.0.0.1:3000/predictions/resnet34 -T inputs/kitten.jpg

kitten.jpg
回复:
{
"label": "tiger_cat",
"index": 282
}工作正常!
总结
使用docker安装torchserve
默认以及自定义handlers
模型打包生成
使用docker提供模型服务到此这篇关于用PyTorch部署模型的文章就介绍到这了,更多相关PyTorch部署模型内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
加载全部内容