pytorch实现图像识别
AI AX AT 人气:01. 代码讲解
1.1 导库
import os.path from os import listdir import numpy as np import pandas as pd from PIL import Image import torch import torch.nn as nn import torch.nn.functional as F import torch.optim as optim from torch.nn import AdaptiveAvgPool2d from torch.utils.data.sampler import SubsetRandomSampler from torch.utils.data import Dataset import torchvision.transforms as transforms from sklearn.model_selection import train_test_split
1.2 标准化、transform、设置GPU
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
normalize = transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
transform = transforms.Compose([transforms.ToTensor(), normalize]) # 转换1.3 预处理数据
class DogDataset(Dataset):
# 定义变量
def __init__(self, img_paths, img_labels, size_of_images):
self.img_paths = img_paths
self.img_labels = img_labels
self.size_of_images = size_of_images
# 多少长图片
def __len__(self):
return len(self.img_paths)
# 打开每组图片并处理每张图片
def __getitem__(self, index):
PIL_IMAGE = Image.open(self.img_paths[index]).resize(self.size_of_images)
TENSOR_IMAGE = transform(PIL_IMAGE)
label = self.img_labels[index]
return TENSOR_IMAGE, label
print(len(listdir(r'C:\Users\AIAXIT\Desktop\DeepLearningProject\Deep_Learning_Data\dog-breed-identification\train')))
print(len(pd.read_csv(r'C:\Users\AIAXIT\Desktop\DeepLearningProject\Deep_Learning_Data\dog-breed-identification\labels.csv')))
print(len(listdir(r'C:\Users\AIAXIT\Desktop\DeepLearningProject\Deep_Learning_Data\dog-breed-identification\test')))
train_paths = []
test_paths = []
labels = []
# 训练集图片路径
train_paths_lir = r'C:\Users\AIAXIT\Desktop\DeepLearningProject\Deep_Learning_Data\dog-breed-identification\train'
for path in listdir(train_paths_lir):
train_paths.append(os.path.join(train_paths_lir, path))
# 测试集图片路径
labels_data = pd.read_csv(r'C:\Users\AIAXIT\Desktop\DeepLearningProject\Deep_Learning_Data\dog-breed-identification\labels.csv')
labels_data = pd.DataFrame(labels_data)
# 把字符标签离散化,因为数据有120种狗,不离散化后面把数据给模型时会报错:字符标签过多。把字符标签从0-119编号
size_mapping = {}
value = 0
size_mapping = dict(labels_data['breed'].value_counts())
for kay in size_mapping:
size_mapping[kay] = value
value += 1
# print(size_mapping)
labels = labels_data['breed'].map(size_mapping)
labels = list(labels)
# print(labels)
print(len(labels))
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(train_paths, labels, test_size=0.2)
train_set = DogDataset(X_train, y_train, (32, 32))
test_set = DogDataset(X_test, y_test, (32, 32))
train_loader = torch.utils.data.DataLoader(train_set, batch_size=64)
test_loader = torch.utils.data.DataLoader(test_set, batch_size=64)1.4 建立模型
class LeNet(nn.Module): def __init__(self): super(LeNet, self).__init__() self.features = nn.Sequential( nn.Conv2d(in_channels=3, out_channels=6, kernel_size=5), nn.ReLU(), nn.AvgPool2d(kernel_size=2, stride=2), nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5), nn.ReLU(), nn.AvgPool2d(kernel_size=2, stride=2) ) self.classifier = nn.Sequential( nn.Linear(16 * 5 * 5, 120), nn.ReLU(), nn.Linear(120, 84), nn.ReLU(), nn.Linear(84, 120) ) def forward(self, x): batch_size = x.shape[0] x = self.features(x) x = x.view(batch_size, -1) x = self.classifier(x) return x model = LeNet().to(device) criterion = nn.CrossEntropyLoss().to(device) optimizer = optim.Adam(model.parameters()) TRAIN_LOSS = [] # 损失 TRAIN_ACCURACY = [] # 准确率
1.5 训练模型
def train(epoch):
model.train()
epoch_loss = 0.0 # 损失
correct = 0 # 精确率
for batch_index, (Data, Label) in enumerate(train_loader):
# 扔到GPU中
Data = Data.to(device)
Label = Label.to(device)
output_train = model(Data)
# 计算损失
loss_train = criterion(output_train, Label)
epoch_loss = epoch_loss + loss_train.item()
# 计算精确率
pred = torch.max(output_train, 1)[1]
train_correct = (pred == Label).sum()
correct = correct + train_correct.item()
# 梯度归零、反向传播、更新参数
optimizer.zero_grad()
loss_train.backward()
optimizer.step()
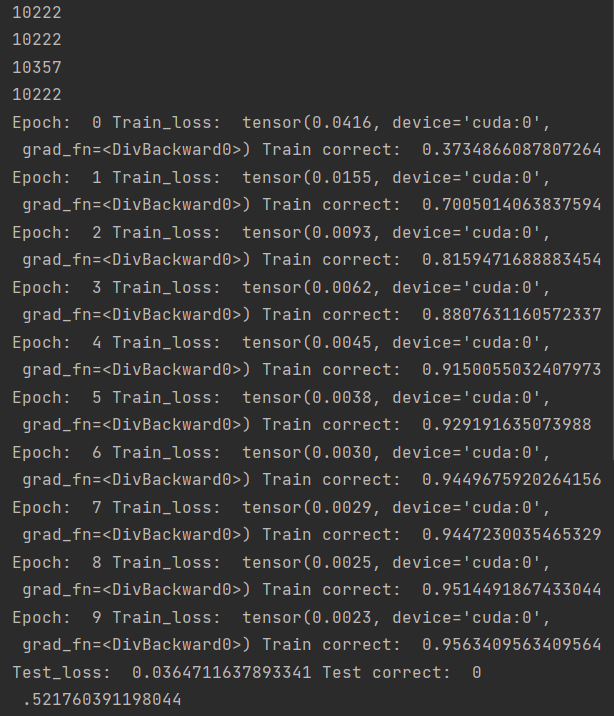
print('Epoch: ', epoch, 'Train_loss: ', epoch_loss / len(train_set), 'Train correct: ', correct / len(train_set))1.6 测试模型
和训练集差不多。
def test():
model.eval()
correct = 0.0
test_loss = 0.0
with torch.no_grad():
for Data, Label in test_loader:
Data = Data.to(device)
Label = Label.to(device)
test_output = model(Data)
loss = criterion(test_output, Label)
pred = torch.max(test_output, 1)[1]
test_correct = (pred == Label).sum()
correct = correct + test_correct.item()
test_loss = test_loss + loss.item()
print('Test_loss: ', test_loss / len(test_set), 'Test correct: ', correct / len(test_set))1.7结果
epoch = 10 for n_epoch in range(epoch): train(n_epoch) test()
加载全部内容