Python 采集拉钩网招聘信息数据 Python爬虫实战演练之采集拉钩网招聘信息数据
松鼠爱吃饼干 人气:0想了解Python爬虫实战演练之采集拉钩网招聘信息数据的相关内容吗,松鼠爱吃饼干在本文为您仔细讲解Python 采集拉钩网招聘信息数据的相关知识和一些Code实例,欢迎阅读和指正,我们先划重点:Python,采集拉钩网,Python,实战,下面大家一起来学习吧。
本文要点:
- 爬虫的基本流程
- requests模块的使用
- 保存csv
- 可视化分析展示
环境介绍
- python 3.8
- pycharm 2021专业版 激活码
- Jupyter Notebook
pycharm 是编辑器 >> 用来写代码的 (更方便写代码, 写代码更加舒适)
python 是解释器 >>> 运行解释python代码的
本次目标

爬虫块使用
内置模块:
- import pprint >>> 格式化输入模块
- import csv >>> 保存csv文件
- import re >>> re 正则表达式
- import time >>> 时间模块
第三方模块:
- import requests >>> 数据请求模块 pip install requests
win + R 输入cmd,回车输入安装命令pip install 模块名。
如果出现爆红,可能是因为,网络连接超时,切换国内镜像源
代码实现步骤: (爬虫代码基本步骤)
- 发送请求
- 获取数据
- 解析数据
- 保存数据
开始代码
导入模块
import requests # 数据请求模块 第三方模块 pip install requests import pprint # 格式化输出模块 import csv # csv保存数据 import time
发送请求
url = 'https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false'
# headers 请求头 用来伪装python代码, 防止被识别出是爬虫程序, 然后被反爬
# user-agent: 浏览器的基本标识
headers = {
'cookie': 'privacyPolicyPopup=false; user_trace_token=20211016201224-ba4d90f0-3db5-4647-a86e-411ee3d5bfef; __lg_stoken__=08639898fbdd53a7ebf88fa16e895b59a51e47738f45faef6a32b9a88d6537bf9459b2c6d956a636a99ff599c6a260f04514df42cb77f83065d55f48a2549e60381e8da811b8; JSESSIONID=ABAAAECAAEBABIIE72FFC38A79322951663B5C7AF10CD12; WEBTJ-ID=20211016201225-17c89047f4293-0d7a7cd583dc83-b7a1438-2073600-17c89047f43a90; sajssdk_2015_cross_new_user=1; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2217c8904800d57b-04f17ed5193984-b7a1438-2073600-17c8904800e765%22%2C%22%24device_id%22%3A%2217c8904800d57b-04f17ed5193984-b7a1438-2073600-17c8904800e765%22%7D; PRE_UTM=; PRE_HOST=; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2Fjobs%2Flist%5Fpython%3FlabelWords%3D%26fromSearch%3Dtrue%26suginput%3D; LGSID=20211016201225-7b8aa578-74ab-4b09-885c-ebbe57a6029a; PRE_SITE=; LGUID=20211016201225-fda15dbb-7823-4a2d-9d80-258caf018f02; _ga=GA1.2.903785807.1634386346; _gat=1; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1634386346; _gid=GA1.2.701447082.1634386346; X_HTTP_TOKEN=ba154973a88f2f64153683436141effc1d544fa2ed; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1634386352; LGRID=20211016201232-8913a057-d37d-41c3-b094-a04cf36515a7; SEARCH_ID=ff32d1294b464305b4e0907f659ef2a7',
'referer': 'https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput=',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36',
}
data = {
'first': 'false',
'pn': page,
'kd': 'python',
'sid': 'bf8ed05047294473875b2c8373df0357'
}
# response 自定义变量 可以自己定义
response = requests.post(url=url, data=data, headers=headers)
<Response [200]> 获取服务器给我们响应数据
解析数据
json数据最好解析 非常好解析, 就根据字典键值对取值
result = response.json()['content']['positionResult']['result']
# 循环遍历 从 result 列表里面 把元素一个一个提取出来
for index in result:
# pprint.pprint(index)
# href = index['positionId']
href = f'https://www.lagou.com/jobs/{index["positionId"]}.html'
dit = {
'标题': index['positionName'],
'地区': index['city'],
'公司名字': index['companyFullName'],
'薪资': index['salary'],
'学历': index['education'],
'经验': index['workYear'],
'公司标签': ','.join(index['companyLabelList']),
'详情页': href,
}
# ''.join() 把列表转成字符串 '免费班车',
csv_writer.writerow(dit)
print(dit)
加翻页
for page in range(1, 31):
print(f'------------------------正在爬取第{page}页-------------------------')
time.sleep(1)
保存数据
f = open('招聘数据.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=[
'标题',
'地区',
'公司名字',
'薪资',
'学历',
'经验',
'公司标签',
'详情页',
])
csv_writer.writeheader() # 写入表头
运行代码,得到数据

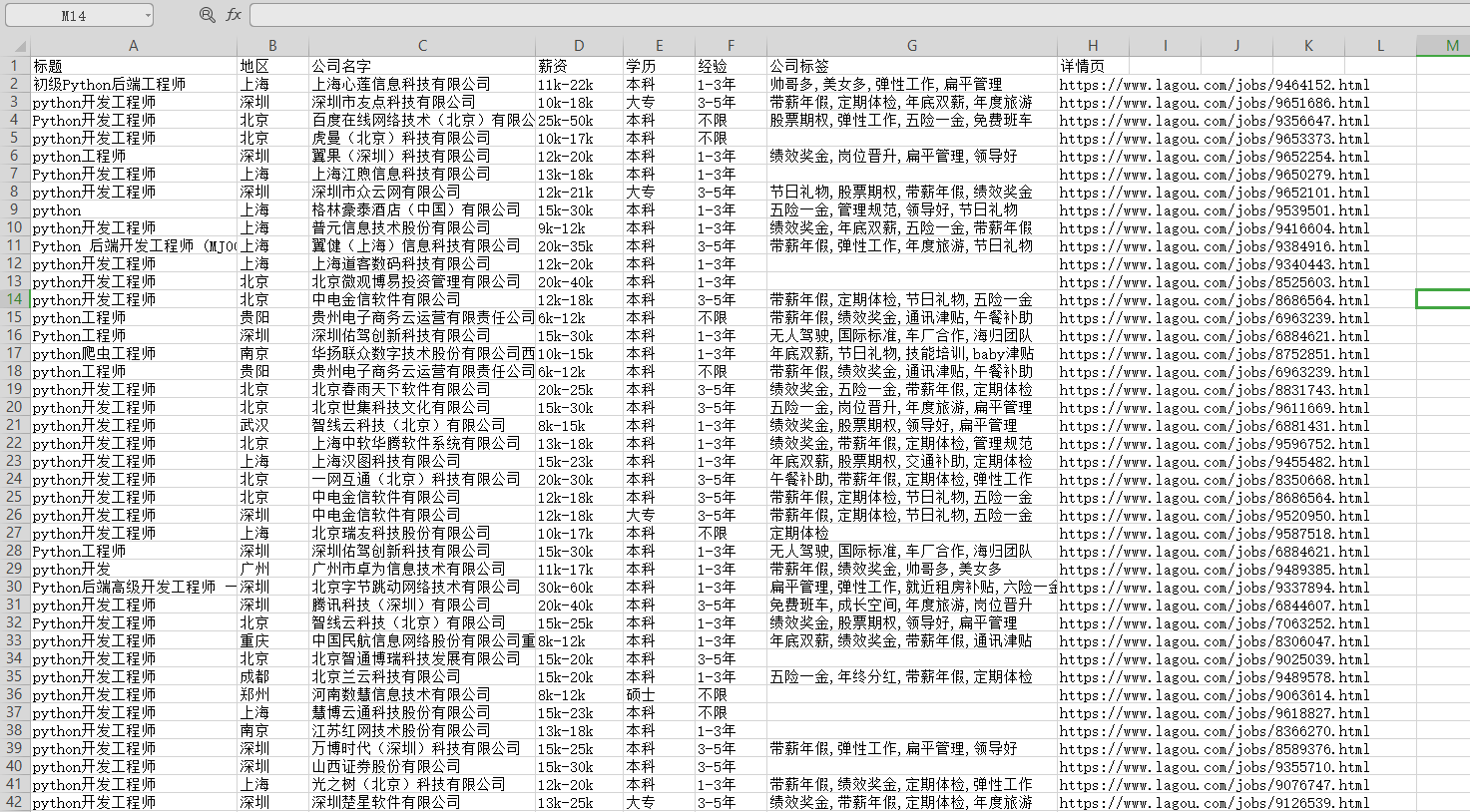
【付费VIP完整版】只要看了就能学会的教程,80集Python基础入门视频教学
加载全部内容