python高阶函数 python中三种高阶函数(map,reduce,filter)详解
网名余先生 人气:0想了解python中三种高阶函数(map,reduce,filter)详解的相关内容吗,网名余先生在本文为您仔细讲解python高阶函数的相关知识和一些Code实例,欢迎阅读和指正,我们先划重点:python高阶函数,python,map,reduce,filter,下面大家一起来学习吧。
- map(function,seq[,seq2]) 接收至少两个参数,基本作用为将传入的函数依次作用到序列的每个元素,并且把结果作为新的序列 返回一个可迭代的map对象
function:函数对象
py2中可为None,作用等同于zip()
如:

py3中不可为None,None是不可调用、不可迭代对象
seq:可迭代对象,可以传一个或多个
# 传一个: def func(i):return i*2 print([i for i in map(func,[1,'2'])]) # [2,'22'] # 传多个 def func2(x,y):return x+y print([i for i in map(func2,[1,2],[2,3])]) # [3, 5]
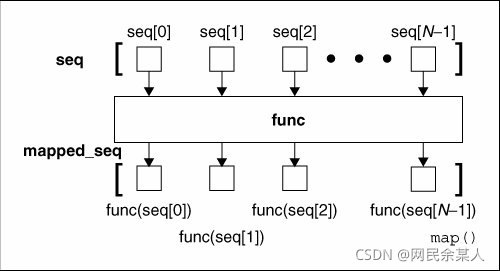
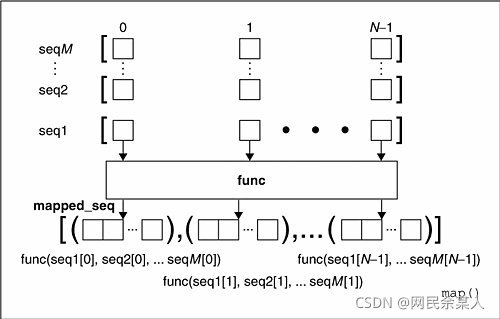
结合图 map()的作用可以理解为:
# 传一个时 seq=[1,'2'] result=[] def func(x):return x*2 for i in seq: result.append(func(i)) print(result) # 传多个时 seq1=[1,2] seq2=[2,3] result=[] def func2(x,y):return x+y for x,y in zip(seq1,seq2): result.append(func2(x,y)) print(result)
当多个可迭代对象的长度不一致时,map只会取最短组合;同时每个可迭代对象相应位置参数类型需一致!(除了py支持的"str"*n)
如:
seq1=[1,2] seq2=[2,3,4] result=[] def func2(x,y):return x+y for x,y in zip(seq1,seq2): result.append(func2(x,y)) print(result) #[3,5]
map的function参数可以是lambda对象
如:
print([i for i in map(lambda x, y, z: (f'x:{x}', f'y:{y}', f'z:{z}'), [1, 2, 3, 4, 5], [1, 2, 3, 4], [1, 2])])
# [('x:1', 'y:1', 'z:1'), ('x:2', 'y:2', 'z:2')]
- filter(function, seq)接收两个参数,基本作用是对可迭代对象中的元素进行过滤;并返回一个新的可迭代filter对象
function:函数对象,返回值必须是个boolean值
seq:可迭代对象
如:获取所有小写的字符串
print([i for i in filter(lambda k: str(k).islower(), ['Java', 'Python', 'js', 'php'])]) # ['js', 'php']
等同于:
_list=['Java','Python','js','php'] result=[] def is_lower(str_obj):return str(str_obj).islower() for i in _list: if is_lower(i): result.append(i) print(result)
- reduce(function,seq[,initial])接收三个参数,基本作用为对序列进行累积;并返回结果。python3中reduce需从functools模块导入
function:函数对象
seq: 可迭代对象
initial:初始值,选填参数
工作过程是:
reduce在迭代seq的过程中,第一次先把 seq的前两个元素传给 函数function,函数处理后,再把得到的结果和第三个元素作为两个参数再次传递给函数function, 函数处理后得到的结果又和第四个元素作为两个参数传给函数function 依次类推,直至seq被迭代完。 如果传入了 initial 值, 那么首次传递的两个元素则是 initial值 和 第一个元素。经过一次次累计计算之后得到一个汇总返回值。
如:求和
def _add(x, y): return x + y # 指定initial print(reduce(_add,[1],3)) # 4 print(reduce(_add, [1, 2], 2)) # 5 # 不指定initial print(reduce(_add, [1, 2])) # 3 print(reduce(_add,[1])) # 1 print(reduce(_add, [1, 2, 3, 4, 5])) # 15
等同于:
def fact(n): if n == 1: return 1 return n + fact(n - 1) print(fact(5)) # 15
借助lambda:
print(reduce(lambda x, y: x + y, range(1, 6))) # 15
结合实际:假设我们要取出字典的key中包含某个关键字的键值对
如:取出下列字典中key值包含ECU的键值对
key = "ECU"
file_dict = {'value': 'name',
'刷写ECU': 'burn_ecu_version=ecu_name,burn_package_url,(flash_method)',
'BD升级ECU': 'bd_ecu_version=ecu_name,doip_package_url',
'设置证书': 'set_ecu_certs=set_method,ecu_name,(bench_name)', 'x': {"ECU": "xx"}}
方法一:引入其他变量
result = {}
for k, v in file_dict.items():
if key in k:
result[k] = v
print(result)
# {'刷写ECU': 'burn_ecu_version=ecu_name,burn_package_url,(flash_method)', 'BD升级ECU': 'bd_ecu_version=ecu_name,doip_package_url'}
方法二:使用推导式
print(dict((k, v) for k, v in file_dict.items() if key in k))
方法三:reduce+map+filter
from functools import reduce
print(reduce(lambda x, y: x.update(y) or x,
[i for i in map(lambda k: {k: file_dict[k]}, filter(lambda k: key in k, file_dict))]))
细心的同学肯定发现无法过滤出嵌套key。这是弊端
解决方案:递归
class GetResource:
def __init__(self):
self.result = {}
def get_resource(self, key_str, data):
"""
从dict中获取包含指定key的k,v
:param key_str:
:param data:
:return:
"""
if not isinstance(data, (dict, list, tuple)):
pass
elif isinstance(data, (list, tuple)):
for index in data:
self.get_resource(key_str, index)
elif isinstance(data, dict):
for k, v in data.items():
if isinstance(v, str):
if key_str in k:
self.result[k] = v
else:
self.get_resource(key_str, v)
return self.result
print(GetResource().get_resource(key, file_dict))
# {'刷写ECU': 'burn_ecu_version=ecu_name,burn_package_url,(flash_method)', 'BD升级ECU': 'bd_ecu_version=ecu_name,doip_package_url', 'ECU': 'xx'}
加载全部内容