opencv 剪裁图片 python opencv通过4坐标剪裁图片
程序员进化不脱发! 人气:0本文主要介绍了python opencv通过4坐标剪裁图片,分享给大家,具体如下:
效果展示,

裁剪出的单词图像(如下)


这里程序我是用在paddleOCR里面,通过识别模型将识别出的图根据程序提供的坐标(即四个顶点的值)进行抠图的程序(上面的our和and就是扣的图),并进行了封装,相同格式的在这个基础上改就是了
[[[368.0, 380.0], [437.0, 380.0], [437.0, 395.0], [368.0, 395.0]], [[496.0, 376.0], [539.0, 378.0], [538.0, 397.0], [495.0, 395.0]], [[466.0, 379.0], [498.0, 379.0], [498.0, 395.0], [466.0, 395.0]], [[438.0, 379
.0], [466.0, 379.0], [466.0, 395.0], [438.0, 395.0]], ]
从程序得到的数据格式大概长上面的样子,由多个四个坐标一组的数据(如下)组成,即下面的[368.0, 380.0]为要裁剪图片左上角坐标,[437.0, 380.0]为要裁剪图片右上角坐标,[437.0, 395.0]为要裁剪图片右下角坐标,[368.0, 395.0]为要裁剪图片左下角坐标.
[[368.0, 380.0], [437.0, 380.0], [437.0, 395.0], [368.0, 395.0]]
而这里剪裁图片使用的是opencv(由于参数的原因没有设置角度的话就只能裁剪出平行的矩形,如果需要裁减出不与矩形图片编译平行的图片的话,参考这个博客进行进一步的改进点击进入)
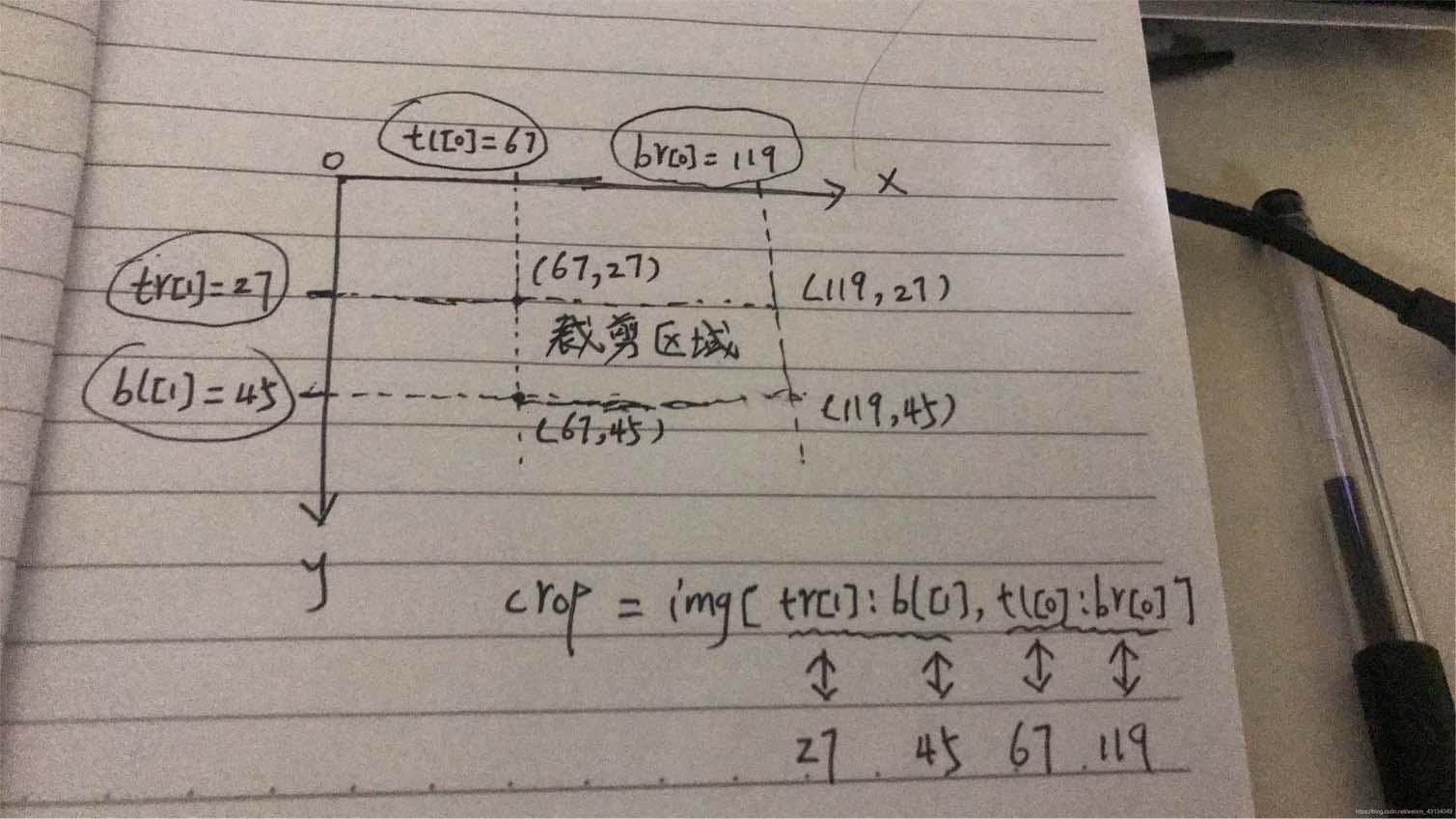
裁剪部分主要是根据下面这一行代码进行的,这里要记住(我被这里坑了一下午),
参数 tr[1]:左上角或右上角的纵坐标值
参数bl[1]:左下角或右下角的纵坐标值
参数tl[0]:左上角或左下角的横坐标值
参数br[0]:右上角或右下角的横坐标值
crop = img[int(tr[1]):int(bl[1]), int(tl[0]):int(br[0]) ]
总的程序代码如下
import numpy as np
import cv2
def np_list_int(tb):
tb_2 = tb.tolist() #将np转换为列表
return tb_2
def shot(img, dt_boxes):#应用于predict_det.py中,通过dt_boxes中获得的四个坐标点,裁剪出图像
dt_boxes = np_list_int(dt_boxes)
boxes_len = len(dt_boxes)
num = 0
while 1:
if (num < boxes_len):
box = dt_boxes[num]
tl = box[0]
tr = box[1]
br = box[2]
bl = box[3]
print("打印转换成功数据num =" + str(num))
print("tl:" + str(tl), "tr:" + str(tr), "br:" + str(br), "bl:" + str(bl))
print(tr[1],bl[1], tl[0],br[0])
crop = img[int(tr[1]):int(bl[1]), int(tl[0]):int(br[0]) ]
# crop = img[27:45, 67:119] #测试
# crop = img[380:395, 368:119]
cv2.imwrite("K:/paddleOCR/PaddleOCR/screenshot/a/" + str(num) + ".jpg", crop)
num = num + 1
else:
break
def shot1(img_path,tl, tr, br, bl,i):
tl = np_list_int(tl)
tr = np_list_int(tr)
br = np_list_int(br)
bl = np_list_int(bl)
print("打印转换成功数据")
print("tl:"+str(tl),"tr:" + str(tr), "br:" + str(br), "bl:"+ str(bl))
img = cv2.imread(img_path)
crop = img[tr[1]:bl[1], tl[0]:br[0]]
# crop = img[27:45, 67:119]
cv2.imwrite("K:/paddleOCR/PaddleOCR/screenshot/shot/" + str(i) + ".jpg", crop)
# tl1 = np.array([67,27])
# tl2= np.array([119,27])
# tl3 = np.array([119,45])
# tl4 = np.array([67,45])
# shot("K:\paddleOCR\PaddleOCR\screenshot\zong.jpg",tl1, tl2 ,tl3 , tl4 , 0)
特别注意对np类型转换成列表,以及crop = img[tr[1]:bl[1], tl[0]:br[0]]的中参数的位置,
实例
用了两种方法保存图片,opencv和Image,实践证明opencv非常快
from PIL import Image
import os
import cv2
import time
import matplotlib.pyplot as plt
def label2picture(cropImg,framenum,tracker):
pathnew ="E:\\img2\\"
# cv2.imshow("image", cropImg)
# cv2.waitKey(1)
if (os.path.exists(pathnew + tracker)):
cv2.imwrite(pathnew + tracker+'\\'+framenum + '.jpg', cropImg,[int(cv2.IMWRITE_JPEG_QUALITY), 100])
else:
os.makedirs(pathnew + tracker)
cv2.imwrite(pathnew + tracker+'\\'+framenum + '.jpg', cropImg,[int(cv2.IMWRITE_JPEG_QUALITY), 100])
f = open("E:\\hypotheses.txt","r")
lines = f.readlines()
for line in lines:
li = line.split(',')
print(li[0],li[1],li[2],li[3],li[4],li[5])
filename = li[0]+'.jpg'
img = cv2.imread("E:\\DeeCamp\\img1\\" + filename)
crop_img = img[int(li[3][:-3]):(int(li[3][:-3]) + int(li[5][:-3])),
int(li[2][:-3]):(int(li[2][:-3]) + int(li[4][:-3]))]
# print(int(li[2][:-3]),int(li[3][:-3]),int(li[4][:-3]),int(li[5][:-3]))
label2picture(crop_img, li[0], li[1])
# #
# x,y,w,h = 87,158,109,222
# img = cv2.imread("E:\\DeeCamp\\img1\\1606.jpg")
# # print(img.shape)
# crop = img[y:(h+y),x:(w+x)]
# cv2.imshow("image", crop)
# cv2.waitKey(0)
# img = Image.open("E:\\DeeCamp\\img1\\3217.jpg")
#
# cropImg = img.crop((x,y,x+w,y+h))
# cropImg.show()
# img = Image.open("E:\\deep_sort-master\\MOT16\\train\\try1\\img1\\"+filename)
# print(int(li[2][:-3]),(int(li[2][:-3])+int(li[4][:-3])), int(li[3][:-3]),(int(li[3][:-3])+int(li[5][:-3])))
# #裁切图片
# # cropImg = img.crop(region)
# # cropImg.show()
# framenum ,tracker= li[0],li[1]
# pathnew = 'E:\\DeeCamp\\deecamp项目\\deep_sort-master\\crop_picture\\'
# if (os.path.exists(pathnew + tracker)):
# # 保存裁切后的图片
# plt.imshow(cropImg)
# plt.savefig(pathnew + tracker+'\\'+framenum + '.jpg')
# else:
# os.makedirs(pathnew + tracker)
# plt.imshow(cropImg)
# plt.savefig(pathnew + tracker+'\\'+framenum + '.jpg')
加载全部内容