python实现十大经典排序算法
HoLoong 人气:0
# Python实现十大经典排序算法
代码最后面会给出完整版,或者可以从[我的Github](https://github.com/NemoHoHaloAi/DSAA/tree/master/Sort)fork,想看动图的同学可以去[这里](https://blog.csdn.net/weixin_41190227/articlehttps://img.qb5200.com/download-x/details/86600821)看看;
小结:
1. 运行方式,将最后面的代码copy出去,直接python sort.py运行即可;
1. 代码中的健壮性没有太多处理,直接使用的同学还要检查检查;
2. 对于希尔排序,gap的选择至关重要,需要结合实际情况更改;
3. 在我的测试中,由于待排序数组很小,长度仅为10,且最大值为10,因此计数排序是最快的,实际情况中往往不是这样;
4. 堆排序没来得及实现,是的,就是懒了;
5. 关键在于理解算法的思路,至于实现只是将思路以合理的方式落地而已;
6. 推荐大家到上面那个链接去看动图,确实更好理解,不过读读代码也不错,是吧;
7. 分治法被使用的很多,事实上我不太清楚它背后的数学原理是什么,以及为什么分治法可以降低时间复杂度,有同学直到麻烦评论区告诉我一下哈,多谢;
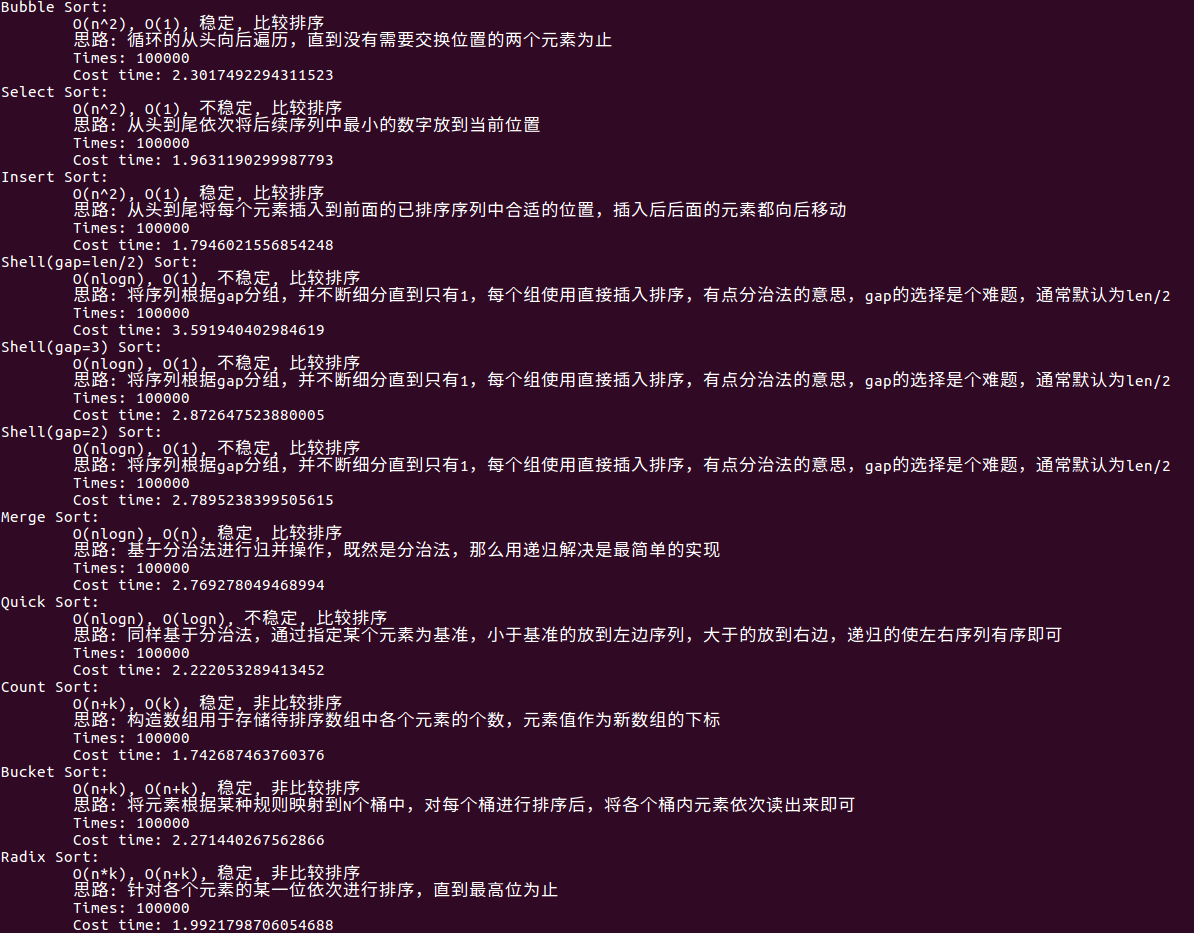
## 运行图
由于数组小,且范围在1到10之间,这其实对于计数排序这种非比较类算法是比较友好的,因为没有多大的空间压力,因此计数排序速度第一很容易理解,而之所以选择、插入比希尔归并要快,主要还是因为问题规模本身太小,而我的分治法的实现是基于递归,因此看不出分治法的优势,事实上如果对超大的数组进行排序的话,这个区别会体现出来;
## 完整代码
可以看到,全部代码不包括测试代码总共才170行,这还包括了空行和函数名等等,所以本身算法实现是很简单的,大家还是要把注意力放在思路上;
```python
import sys,random,time
def bubble(list_):
running = True
while running:
have_change = False
for i in range(len(list_)-1):
if list_[i]>list_[i+1]:
list_[i],list_[i+1] = list_[i+1],list_[i]
have_change = True
if not have_change:
break
return list_
def select(list_):
for i in range(len(list_)-1):
min_idx = i
for j in range(i,len(list_)):
if list_[min_idx]>list_[j]:
min_idx = j
list_[i],list_[min_idx] = list_[min_idx],list_[i]
return list_
def insert(list_):
for i in range(1,len(list_)):
idx = i
for j in range(i):
if list_[j]>list_[idx]:
idx = j
break
if idx != i:
tmp = list_[i]
list_[idx+1:i+1] = list_[idx:i]
list_[idx] = tmp
return list_
def shell(list_,gap=None):
'''
gap的选择对结果影响很大,是个难题,希尔本人推荐是len/2
这个gap其实是间隙,也就是间隔多少个元素取一组的元素
例如对于[1,2,3,4,5,6,7,8,9,10]
当gap为len/2也就是5时,每一组的元素都是间隔5个的元素组成,也就是1和6,2和7,3和8等等
'''
len_ = len(list_)
gap = int(len_/2) if not gap else gap
while gap >= 1:
for i in range(gap):
list_[i:len_:gap] = insert(list_[i:len_:gap])
gap = int(gap/2)
return list_
def merge(list_):
'''
归并排序的递归实现
思路:将数据划分到每两个为一组为止,将这两个排序后范围,2个包含2个元素的组继续排序为1个4个元素的组,
直到回溯到整个序列,此时其实是由两个有序子序列组成的,典型的递归问题
'''
if len(list_)<=1:
return list_
if len(list_)==2:
return list_ if list_[0]<=list_[1] else list_[::-1]
len_ = len(list_)
left = merge(list_[:int(len_/2)])
right = merge(list_[int(len_/2):])
tmp = []
left_idx,right_idx = 0,0
while len(tmp)max_:
max_ = list_[i]
count_list = [0]*(max_-min_+1)
for item in list_:
count_list[item-min_] += 1
list_ = []
for i in range(len(count_list)):
for j in range(count_list[i]):
list_.append(i+min_)
return list_
def heap(list_):
'''
'''
pass
def bucket(list_):
'''
每个桶使用选择排序,分桶方式为最大值除以5,也就是分为5个桶
桶排序的速度取决于分桶的方式
'''
bucket = [[],[],[],[],[]] # 注意长度为5
max_ = list_[0]
for item in list_[1:]:
if item > max_:
max_ = item
gap = max_/5 # 对应bucket的长度
for item in list_:
bucket[int((item-1)/gap)].append(item)
for i in range(len(bucket)):
bucket[i] = select(bucket[i])
list_ = []
for item in bucket:
list_ += item
return list_
def radix(list_):
'''
基数排序:对数值的不同位数分别进行排序,比如先从个位开始,然后十位,百位,以此类推;
注意此处代码是假设待排序数值都是整型
'''
max_ = list_[0]
for item in list_[1:]:
if item > max_:
max_ = item
max_radix = len(str(max_))
radix_list = [[],[],[],[],[],[],[],[],[],[]] # 对应每个位上可能的9个数字
cur_radix = 0
while cur_radix
加载全部内容
- 猜你喜欢
- 用户评论