迄今为止最硬核的「Java8时间系统」设计原理与使用方法
编程新说(李新杰) 人气:1为了使本篇文章更容易让读者读懂,我特意写了上一篇《任何人都需要知道的「世界时间系统」构成原理,尤其开发人员》的科普文章。本文才是重点,绝对要读,走起!
Java平台时间系统的设计方案
几乎任何事物都会有“起点”这样的概念,比如人生的起点就是我们出生的那一刻。
Java平台时间系统的起点就是世界时间(UTC)1970年1月1日凌晨零点零分零秒。用专业的写法是“1970-01-01T00:00:00Z”,最后的大写字母“Z”指的是0时区的意思。
在Java平台时间系统里,这个起点用单词“epoch”表示,就是“新纪元、新时代”的意思。
一般来说如果一个事物有起点,那么通常该事物也会有一个叫做“偏移量”的概念。人一出生,就有了年龄,这就是个偏移量,一旦工作,就有了工龄,这也是个偏移量。
Java平台时间系统就是用偏移量来表示时间的,表面上看起来有年月日时分秒,其实底层就是一个long类型的整数,就是自起点开始经过的毫秒数。
这一点可以很容易说明:
Date now = new Date();
System.out.println(now);
System.out.println(now.getTime());
System.out.println(System.currentTimeMillis());
输出结果如下:
Fri Mar 06 13:52:41 CST 2020
1583473961398
1583473961398
可能有的读者会问,那如何表示1970年以前的时间呢?
当然也是采用偏移量啊,只不过这个偏移量是个负的罢了,估计很多人都没见过负的毫秒数,那就来看看吧。
那就把年份设置成1969年试试吧:
Calendar before = Calendar.getInstance();
before.set(Calendar.YEAR, 1969);
System.out.println(before.getTimeInMillis());
输出结果如下:
-25985142623
看到了吧,就是一个负的整数。
偏移量和时区有关吗?
有一个更有意思的问题浮现了出来,全球有24个时区,那这个偏移量和时区有关吗?
如果无关,则所有时区的偏移量都一样,那时间也应该都一样啊,可事实是都不一样。
如果有关,则所有时区的偏移量都不一样,那就有24个偏移量,感觉似乎也不太对。
孰对孰错,试试便知,那就干起来吧。
获取上海、伦敦、芝加哥三个地方(所在时区)的时间:
Calendar cn = Calendar.getInstance(TimeZone.getTimeZone("Asia/Shanghai"));
Calendar en = Calendar.getInstance(TimeZone.getTimeZone("Europe/London"));
Calendar us = Calendar.getInstance(TimeZone.getTimeZone("America/Chicago"));
打印出来看看:
System.out.println(getDate(cn));
System.out.println(getDate(en));
System.out.println(getDate(us));
输出结果如下:
2020-2-6 13:54:17
2020-2-6 05:54:17
2020-2-5 23:54:17
可以看到,时间是正确的。
再把它们的毫秒数打印出来看看:
System.out.println(cn.getTimeInMillis());
System.out.println(en.getTimeInMillis());
System.out.println(us.getTimeInMillis());
输出结果如下:
1583474057356
1583474057356
1583474057356
结论是:偏移量都一样,和时区是无关的。那日期为啥是不同的呢?这就是时区的功劳了。
再用Java8的时间API来验证一遍。
同样创建三个地方的当地时间:
LocalDateTime cnldt = LocalDateTime.now(ZoneId.of("Asia/Shanghai"));
LocalDateTime enldt = LocalDateTime.now(ZoneId.of("Europe/London"));
LocalDateTime usldt = LocalDateTime.now(ZoneId.of("America/Chicago"));
打印出来看看:
System.out.println(cnldt);
System.out.println(enldt);
System.out.println(usldt);
输出结果如下:
2020-03-06T13:54:17.370
2020-03-06T05:54:17.372
2020-03-05T23:54:17.372
同样时间是正确的。然后再打印出秒数:
System.out.println(cnldt.toEpochSecond(ZoneOffset.of("+8")));
System.out.println(enldt.toEpochSecond(ZoneOffset.of("Z")));
System.out.println(usldt.toEpochSecond(ZoneOffset.of("-6")));
输出结果如下:
1583474057
1583474057
1583474057
可以看到,它们经过的秒数是一样的。
备注:中国时间东8时区,英国时间0时区,美国时间西6时区。
这里主要想说的是,在之前的Java中是使用毫秒来衡量偏移量的,自Java8开始就使用秒和纳秒来衡量偏移量,纳秒是指最后那一个不完整的1秒。
纳秒是10的9次方分之一秒,比毫秒精确了100万倍,所有Java8的时间系统较之以前更精确了,当然是理论上的啦。
时区是颇为复杂的
大家不要小看时区,它绝对比我们认为的“不就是差几个小时嘛”要复杂些。
时区在划分时主要考虑当地的居民生活和上班情况,所以时区是和地区有密切关联的。因此时区的名字也都以地理位置来标识的。
具体格式是:大洲或大洋名称/城市或著名地点或方位名称,如Asia/Shanghai,Europe/London,America/Chicago。
当然了也有一些不规则的,如MST7MDT、US/Hawaii、SystemV/CST6、Zulu、NZ-CHAT,也许是历史遗留问题或其它原因吧,不去深究了。
在Java8中时区用ZoneId表示,意思是一个地区的ID,ID就是标识嘛,所以我觉得ZoneId更应该理解为一个地区而非一个时区。可能有人会觉得为啥不用TimeZone来表示时区呢?遗憾的是在JDK1.1的时候这个名字就被用了,而且表示的就是时区。
时区可以按如下的方式创建:
ZoneId.of("Asia/Shanghai");
ZoneId.of("Europe/London");
ZoneId.of("America/Chicago");
采用地理位置的方式来命名时区是比较生活化的,貌似一下子很难和时间计算联系在一起。
其实时区的本质不就是距离标准(0时区)时间的偏移量嘛,所以时区就是基于起点(0时区)的偏移量。这样是不是仿佛一下具有了计算性。
这个偏移量用ZoneOffset表示,0时区偏移量是0,可以表示为:
ZoneOffset.of("+0");
ZoneOffset.of("-0");
注意,虽然“+0”和“-0”在算术上是相等的,但这里是时区格式的字符串,所以“+”和“-”是不能省略的。
0时区是时区的起点,比较特殊,因此还专门有一个字母来表示,就是大写字母“Z”,因此可以这样:
ZoneOffset.of("Z");加号(+)表示0时区东边的时区,如中国的东8时区,可以表示为:
ZoneOffset.of("+8");
减号(-)表示0时区西边的时区,如美国的西6时区,可以表示为:
ZoneOffset.of("-6");
上面的“+8”表示比标准时间早8个小时,“-6”表示比标准时间晚6个小时。
既然整小时都被支持了,那分钟也应该被支持的啊,没错,分钟也是支持的,像这样:
ZoneOffset.of("+01:30");
ZoneOffset.of("-02:20");
"+01:30"表示比标准时间早1小时30分,"-02:20"表示比标准时间晚2小时20分。
既然分钟都支持了,那干脆连秒也支持了吧,是的,秒也是支持的,像这样:
ZoneOffset.of("+03:40:50");
ZoneOffset.of("-04:50:30");
含义和上面一样,只是多了个秒而已。
需要说明的是,Java8支持的时间偏移量范围是从“-18:00”到“+18:00”,横跨36个小时,远超过24个时区。
理论上讲,ZoneId和ZoneOffset应该具有某种联系,因为它们的目的是一样的,只是从不同的角度来描述,都表示一个地方的当地时间距离标准时间的差值。
实际上ZoneOffset继承了ZoneId,所以“Asia/Shanghai”和“+8”其实是一样的,表示上海的当地时间比标准时间早8个小时,很简单吧,要是都这么简单那就好了。
曾经混乱的地理时区及其转换
世界时间标准是一步步建立起来的,那么在标准建立之前,一定会有相对混乱的地方。一段时间用这个时区,一段时间又改为别的时区,而且还有可能反复。
空口无凭?那就上证据,从爱国主义角度出发,先看中国的时区情况:
1[Overlap at 1901-01-01T00:00+08:05:43 to +08:00],
2[Gap at 1940-06-01T00:00+08:00 to +09:00],
3[Overlap at 1940-10-13T00:00+09:00 to +08:00],
4[Gap at 1941-03-15T00:00+08:00 to +09:00],
5[Overlap at 1941-11-02T00:00+09:00 to +08:00],
6[Gap at 1942-01-31T00:00+08:00 to +09:00],
7[Overlap at 1945-09-02T00:00+09:00 to +08:00],
8[Gap at 1946-05-15T00:00+08:00 to +09:00],
9[Overlap at 1946-10-01T00:00+09:00 to +08:00],
10[Gap at 1947-04-15T00:00+08:00 to +09:00],
11[Overlap at 1947-11-01T00:00+09:00 to +08:00],
12[Gap at 1948-05-01T00:00+08:00 to +09:00],
13[Overlap at 1948-10-01T00:00+09:00 to +08:00],
14[Gap at 1949-05-01T00:00+08:00 to +09:00],
15[Overlap at 1949-05-28T00:00+09:00 to +08:00],
16[Gap at 1986-05-04T02:00+08:00 to +09:00],
17[Overlap at 1986-09-14T02:00+09:00 to +08:00],
18[Gap at 1987-04-12T02:00+08:00 to +09:00],
19[Overlap at 1987-09-13T02:00+09:00 to +08:00],
20[Gap at 1988-04-17T02:00+08:00 to +09:00],
21[Overlap at 1988-09-11T02:00+09:00 to +08:00],
22[Gap at 1989-04-16T02:00+08:00 to +09:00],
23[Overlap at 1989-09-17T02:00+09:00 to +08:00],
24[Gap at 1990-04-15T02:00+08:00 to +09:00],
25[Overlap at 1990-09-16T02:00+09:00 to +08:00],
26[Gap at 1991-04-14T02:00+08:00 to +09:00],
27[Overlap at 1991-09-15T02:00+09:00 to +08:00]
我们来解释下,这些都是什么意思。“Overlap”是重叠的意思,比如我把时间从9点调整到8点,那么从8点到9点这1个小时会再走一遍,这就是时间重叠。
“Gap”是裂缝的意思,比如我把时间从9点调整到10点,那么从9点到10点这1个小时就不用走了,相当于直接蹦过去了,这就是时间裂缝。
再进一步说,有重叠的说明时间是往回(后)调了,有裂缝的说明时间是往早(前)调了。
所以,“1901-01-01T00:00+08:05:43 to +08:00”表达的意思是,中国在“1901-01-01T00:00”的时刻,把我们的时间偏移量从“+08:05:43”调整到“+08:00”,就是往回调整了5分43秒。所以是“Overlap”,即重叠。
中国后续的全部都是在东8时区和东9时区之间的调整,最后一次是在“1991年09月15日凌晨02点00分”从“+09:00(东9区)”到“+08:00(东8区)”,自此直到现在,中国都是使用的东8区时间。
这些都是已经发生过的历史,Java时间系统在设计时不可能不管它的,是要支持的,所以我说时区还是有点复杂的。哈哈,历史的包袱还是有点沉重的。
美国啊,就更复杂了,中国好歹只有北京时间,美国的时间就不统一了,有东部时间、中部时间、山地时间、太平洋时间、阿拉斯加时间、夏威夷时间。
而且它的时区变换也是异常多的,大概将近200次,这里只展示一部分,这里展示的是芝加哥的当地时间,属于美国中部时间:
1[Overlap at 1883-11-18T12:09:24-05:50:36 to -06:00],
2
3[Gap at 1918-03-31T02:00-06:00 to -05:00],
4[Overlap at 1918-10-27T02:00-05:00 to -06:00],
5[Gap at 1919-03-30T02:00-06:00 to -05:00],
6[Overlap at 1919-10-26T02:00-05:00 to -06:00],
7[Gap at 1920-06-13T02:00-06:00 to -05:00],
8[Overlap at 1920-10-31T02:00-05:00 to -06:00],
9[Gap at 1921-03-27T02:00-06:00 to -05:00],
10[Overlap at 1921-10-30T02:00-05:00 to -06:00],
11[Gap at 1922-04-30T02:00-06:00 to -05:00],
12[Overlap at 1922-09-24T02:00-05:00 to -06:00],
13
14。。。。。。。。。。
15
16[Gap at 2005-04-03T02:00-06:00 to -05:00],
17[Overlap at 2005-10-30T02:00-05:00 to -06:00],
18[Gap at 2006-04-02T02:00-06:00 to -05:00],
19[Overlap at 2006-10-29T02:00-05:00 to -06:00],
20[Gap at 2007-03-11T02:00-06:00 to -05:00],
21[Overlap at 2007-11-04T02:00-05:00 to -06:00],
22[Gap at 2008-03-09T02:00-06:00 to -05:00],
23[Overlap at 2008-11-02T02:00-05:00 to -06:00]
可以看到首次调整是在“1883-11-18T12:09:24”的时候把时间偏移量从“-05:50:36”调整到了“-06:00”,等于回调了9分24秒,所以是“Overlap”,即重叠。
仔细看的话会发现后续的调整都集中到每年的3/4/6月份和9/10/11月份,而且都是在西5区和西6区之间的变换。
相信大家都已经猜出来了,美国是分“冬令时(正常时间)”和“夏令时”的国家。所以每年都会调整2次,那为什么上面的最后一次调整是2008年呢?后续的调整呢?
上面那些都是历史了,所以需要都记录下来,其实这个调整是有规律的,因此只需要记录下规律,而不需要记录每次变更的日志了。
美国芝加哥(中部时间)当地的冬令时和夏令时的变换规律是:
[Gap -06:00 to -05:00, SUNDAY on or after MARCH 8 at 02:00 WALL, standard offset -06:00],
[Overlap -05:00 to -06:00, SUNDAY on or after NOVEMBER 1 at 02:00 WALL, standard offset -06:00]
冬令时到夏令时的转换是在,每年3月8日及其之后最近的一个周日凌晨2点,把时区从“-6”变到“-5”,即提前1小时,所以是“Gap”裂缝。
夏令时到冬令时的转换是在,每年11月1日及其之后最近的一个周日凌晨2点,把时区从“-5”变到“-6”,即延后1小时,所以是“Overlap”重叠。
“standard offset -06:00”的意思是,这里(当地)的标准时间偏移量是比UTC晚6个小时,为了照顾当地人们的生活和上班习惯,在夏天到来时,把时间提前1个小时。
“WALL”这个单词是墙的意思,所以“at 02:00 WALL”的意思就是在你看到墙上挂的钟表是凌晨2点的时候。是对当前正在使用(还未调整)的时间的一种指代吧。
上面那些已经记录下来的转换历史日志,是为了对过去时间的计算用的,而这个转换规则,是为了对未来的时间计算用的。
还好中国没有冬令时和夏令时的概念,中国只是改变了上下班的时间,冬天下班早些,因此中国没有转换规则,一年四季都是比UTC早8小时。
“当地时间”的计算方法
在Java时间系统里,时间就是自“时间起点”开始经过的毫秒数,这对全球24个时区都是一样的。
如果把这个毫秒数直接转化为时间,它对应的就是UTC时间,即0时区的时间,也是英国伦敦的时间。
如果某地不是位于0时区的话,那就再加上或减去当地时区对应的时间偏移量,得到的就是当地时间。
比如中国就是“毫秒数”再加上8个小时对应的毫秒数,美国中部就是”毫秒数“再减去6个小时对应的毫秒数。
不要以为这样就完事了,历史上同一个地方的时区都是比较混乱的,可能反复变换过几十次甚至上百次,那么这个地方对应的时区到底该怎么取呢?
还好,上面说了,Java时间系统已经记录下了每个地方时区变更历史日志了,这些反复的变更其实构成了一个个连续的区间。
每个区间的两端都是一个日期(时间),其实也是一个“毫秒数”。这样当我们拿到一个时间“毫秒数”后,就去和这个地方的所有变更区间两端的“毫秒数”进行比对。
确认出我们拿到的这个“毫秒数”落到了哪个区间,然后就使用这个区间对应的时区时间偏移量即可。这样所有的历史(过去的)时间就都算出来了。
那对于未来的时间呢?像美国那样的有冬令时和夏令时变换规则的,就按规则去计算。像中国这种没有变换规则的,就按历史上最后一次变换后对应的时区时间偏移量去计算。
即如果不出意外的话,中国永远是采用东8区,时间永远比UTC早8小时。
从“毫秒数”计算出具体时间
首先需要说明的是,Java8获取的还是毫秒级别的偏移量,而且和之前的方法是一样,并不是直接获取的纳秒。
证明如下图01:

后来又将毫秒转换为秒和纳秒,证明如下图02:
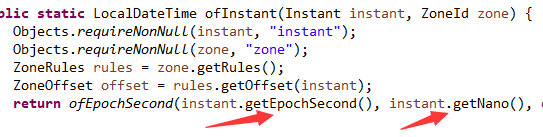
所以说Java8时间系统的精度并没有提升,至少在某些方面没有提升。
当毫秒被转化为秒和纳秒后,首先要加上或减去时区的时间偏移量,这个偏移量是精确到秒级的。所以不影响纳秒的数值。
然后开始计算日期和时间,日期和时间肯定要分开计算的,用秒数除以86400(每天的秒数)并取整得到的就是自1970-01-01经过的天数,这个天数可能是负的。
由于大月为31天/月,小月为30天/月,2月份为平年28天/闰年29天,所以从天数转化为年/月/日的时候也是比较繁琐的,而且正的天数是往后算,负的天数是往前算,也是不一样的。
日期这就算出来了,然后再算时间。用计算天数时剩下(不足1天)的秒数,再加上纳秒那部分,去计算出时/分/秒/纳秒,这部分的计算要相对容易些了。
这样时间(LocalTime)也计算出来了,在加上前面算出来的日期(LocalDate),就是现在的日期时间(LocalDateTime)了。
这就是JDK8里面的计算方法,如下图03:

时间的获取与跨时区转换
获取自己所在地区的当前时间,是这样子的:
LocalDateTime.now();
Java会利用操作系统设置的地区信息。
如果要获取指定地区的当前时间,需要自己指定一个时区(地区),是这样子的:
LocalDateTime.now(ZoneId.of("America/Chicago"));
如果知道了一个地区的时间偏移量,那就指定一个时区偏(地区)移量,也可以这样子:
LocalDateTime.now(ZoneOffset.of("-6"));
如果要获取UTC(标准)时间,可以这样子:
LocalDateTime.now(ZoneId.of("Europe/London"));
LocalDateTime.now(ZoneOffset.of("Z"));
因为伦敦时间就是标准时间,也是0时区时间,也是没有时区偏移量的时间,“Z”的意思就是偏移量为0。
如果在一个非常确定的情况下进行跨时区转换时间的话,是这样子的:
ZoneOffsetTransition zot = ZoneOffsetTransition.of(LocalDateTime.now().withNano(0), ZoneOffset.of("+8"), ZoneOffset.of("-6"));
zot.getDateTimeBefore();
zot.getDateTimeAfter();
of方法的第一个参数是待转换的时间,第二个参数是该时间对应的偏移量,第三个参数是转换后的偏移量。
其实内部原理很简单,就是加上或减去这两个偏移量之间的差值。
由于过去很多地方都进行过时区的多次反复变更,如果想知道某个地方过去的某个时间当时所采用的时区,可以这样子:
ZoneRules rules = ZoneId.of("Asia/Shanghai").getRules();
LocalDateTime someTime = //过去的某个时间;
ZoneOffset offset = rules.getOffset(someTime);
就是根据地区获取到该地区的变换规则,根据规则获取过去某个时间当时的偏移量,当然这个时间也可以是未来的时间。
这在一般情况下都会得到唯一的准确的结果,但发生在日期调整的特殊时刻时就不是这样的了。
比如美国在夏天到来时会在某个周日的凌晨2点把时间往前调一个小时,就是从2点直接蹦到3点,时间偏移量就是从-6变为-5。
如果我们要找2点半对应的时间偏移量,其实是没有的。因为这个时间根本就没有出现过,是被蹦过去了。这是时间裂缝,我们等于掉到裂缝里了。
同样美国在冬天到来时会在某个周日的凌晨2点把时间往回调一个小时,就是从2点直接退到1点,时间偏移量就是从-5变为-6。
如果我们要找1点半对应的时间偏移量,其实是有2个。因为这个时间实际上出现过两次,因为1点到2点又重复走了一遍。这就是时间重复,我们等于掉到重复里了。
对于这两种情况,系统给的是调整前的时间偏移量,而且明确说明这只是个“最佳”结果而非“正确”结果,应用程序应该自己认真对待这种情况。
系统给出的这个“最佳”结果,对于过去的时间和未来的时间都是一样的,即在“临界区”的时间段内选的都是调整前的时间偏移量。
这个是使用当地的时间获取当地的时间变换规则,其实还有更麻烦的场景。像下面这个。
就是我们想知道在中国过去(或未来)的某个时间的时候,美国的芝加哥对应时间是几点?
这时候其实需要知道在中国的这个时间的时候,美国芝加哥的时间的偏移量是多少?
因为芝加哥的时间偏移量也是反复变化的,所以还需像上面那样去获取,就是这样子:
ZoneRules usaRules = ZoneId.of("America/Chicago").getRules();
LocalDateTime chinaTime = //中国过去的某个时间;
可是遗憾的是,我们不能用中国的当地时间去获取芝加哥对应时候的时间偏移量。因为中国的时间是按中国的偏移量算出来的哦。
那怎么办呢?方法还是有的。有一点一定要记清楚,就是在某一瞬间,虽然全球时间各不一样,但是经过的“毫秒数”却都是一样的。
所以先把中国过去的这个时间转化为“毫秒数”,或者说转化为那一瞬间,然后再用这一瞬间去获取芝加哥在这一瞬间的时间偏移量。
因为这一瞬间是全球都一样的。首先用中国的变换规则获取中国过去那个时间的偏移量,因为从时间到瞬间的变换需要知道时间偏移量。
因为不知道时间偏移量的话,我们无法确定这个时间是哪里的时间,可能是现在东8区的时间,也可能是1个小时前东9区的时间,还可能是1个小时后东7区的时间。
我去,好麻烦啊,先用中国变换规则和中国时间计算出那一瞬间吧,像这样子:
ZoneRules chinaRules = ZoneId.of("Asia/Shanghai").getRules();
ZoneOffset chinaOffset = chinaRules.getOffset(chinaTime);
Instant instant = chinaTime.toInstant(chinaOffset);
算出的这个瞬间instant是世界通用的,然后用它去计算芝加哥在这一瞬间的时间偏移量,像这样子:
ZoneRules usaRules = ZoneId.of("America/Chicago").getRules();
ZoneOffset usaOffset = usaRules.getOffset(instant);
现在事情已经明朗了,待转换的时间,转换前时间偏移量,转换后时间偏移量这三者都有了,就变成一个确定的情况了。
方法和一开始用的是一样的,像这样子:
ZoneOffsetTransition china2usa = ZoneOffsetTransition.of(chinaTime, chinaOffset, usaOffset);
china2usa.getDateTimeBefore();
china2usa.getDateTimeAfter();
现在终于可以说一句,时区不是颇为复杂,而是相当复杂啊。
时间系统的常用类揭秘
对系统默认时区的获取依然是依赖TimeZone这个很早期的类,如下图04:

使用这个默认的时区获取系统默认时钟,如下图05:

在默认时钟里其实就是获取了当前经过的毫秒数,还是用的老方法,如下图06:

至此,毫秒数和时区都已经具备,一个具体的时间就此产生了。这不就是Java时间系统的原理嘛!
LocalDate类揭秘,先看它的存储字段,如下图07:

只存储年/月/日三个字段。
系统当前日期的获取方法,就是用系统当前默认时钟,算出来的,如下图08:

算法也简单,从时钟里取出经过的秒数和时区偏移量对应的秒数,加起来,然后再转换为天数。
这就是自1970年1月1日起经过的天数,然后再计算出具体日期即可,如下图09:
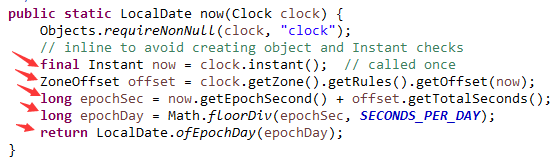
LocalTime类揭秘,先看它的存储字段,如下图10:

只存储时/分/秒/纳秒四个字段。
系统当前时间的获取方法,就是用系统当前默认时钟,算出来的,如下图11:

算法也简单,从时钟里取出经过的秒数和时区偏移量对应的秒数,加起来,然后再算出最后那部分不能构成整天的剩余秒数。
将这部分秒数转换为纳秒,再加上时钟里原本的那部分纳秒,这就是不能构成整天的总纳秒,然后算出时间,如下图12:

LocalDateTime类揭秘,先看它的存储字段,如下图13:

只存储了日期和时间两个字段。
系统当前日期时间的获取方法,也是用系统当前默认时钟,算出来的,如下图14:

具体算法和上面算日期、算时间的一模一样。
OffsetDateTime类揭秘,先看它的存储字段,如下图15:

一个本地日期时间和一个时区偏移量两个字段。
说明一下,只要是算时间的,都会用的时区偏移量,只不过是前面算LocalDateTime时没有存而已,这里存了。
系统当前带时区偏移量的日期时间获取方法,和之前的也完全一样,如下图16:

OffsetTime类揭秘,先看它的存储字段,如下图17:

一个本地时间和一个时区偏移量两个字段。
系统当前带时区偏移量的时间获取方法,和之前的也完全一样,如下图18:

ZonedDateTime类揭秘,先看它的存储字段,如下图19:

一个本地日期时间、一个时区偏移量和一个地区三个字段。
这里的ZoneId和ZoneOffset同时出现并不意味着重复的意思,因为一个ZoneId在不同的历史时期或一年中不同的时候可能对应的ZoneOffset是不同的。
系统当前带地区偏移量的日期时间获取方法,和之前的也完全一样,如下图20:

ZoneOffset类揭秘,先看它的存储字段,如下图21:

一个总秒数和一个偏移量Id。
其本质就是偏移的秒数,但是直接用秒数在有些时候不够人性化,所以还给了个字符串类型的Id,它的格式如下图22:

这种格式比较友好、比较直观,但最后还是要给算成一个总秒数。算是换了一种好的表达方式吧。
Instant类揭秘,先看它的存储字段,如下图23:

一个秒数和一个纳秒数两个字段。
这两个字段的值就是从系统当前经过的“毫秒数”里算出来的。所以它是一个时刻,就是一瞬间的意思。
系统当前默认时刻的获取方法,如下图24:

可以看到是UTC的时刻,即0时区的时刻。再次说明全世界任何地方的时刻都是一样的,而时间的不同就是因为时区的不同造成的时间偏移量不同。
Duration类揭秘,先看它的存储字段,如下图25:

一个秒数和一个纳秒数两个字段。
这两字段存储的是一段时间(也称时长),所有这个类表示一段时间,这段时间可以是正的,也可以是负的。
Period类揭秘,先看它的存储字段,如下图26:

一个年数、一个月数和一个日数三个字段。
这个类也表示一段时间(也称时长),只不过它是以对人类有意义的方式来存储,比如截止到今天,我已经工作了10年9个月6天啦。
Duration类和Period类都表示一段时间,除了表达方式上的不同之外,还有一个重要的点,Duration类在进行加减的时候,都是加减的精确时间,比如1天就是24小时。
Period类在进行加减的时候,加减的都是概念上的时间,特别是在时区调整的时候,它会维持当地时间的合理性,而Duration类则不会。
比如夏令时到来,在时区即将提前1一个的时候,在18:00的时候加上1天,如果是Period类,则加完后是第二天的18:00,他会自动处理时区提前产生的裂缝。
如果是Duration类,则加完后是第二天的19:00,它是精确的加上了24小时,又由于时区提前产生了1小时的裂缝,因此等于加上了25小时。
Period类的年数/月数/日数三个字段之间,互相不影响,每个都可以随意的为正数或负数。
Year类只存了一个年份、YearMonth类只存了年月、MonthDay类只存了月日,这些都是在特定情况下会用到的类,它们的情况和大多数人理解的一样。
常用的时间操作
如果要获取当前时间的话,用的都是now()方法,默认是本地时区,也可以指定别的时区,如下图27:

如果要从指定的数据构建的话,用的都是of()方法,如下图28:

如果要从字符串解析的话,用的都是parse()方法,如下图29:

如果要格式化的话,用的都是format()方法,如下图30:

如果要获取指定字段的值的话,用的都是get()方法,如下图31:

如果要比较时间的早晚或相等的话,用的都是is()方法,如下图32:

如果要加上一段时间的话,用的都是plus()方法,如下图33:

如果要减去一段时间的话,用的都是minus()方法,如下图34:

如果要设置字段为特定值的话,用的都是with()方法,如下图35:

如果要附加上一些本来不含有的额外信息的话,用的都是at()方法,如下图36:

以上这些方法的含义对于不同的类是一样的,而且常用的操作基本都包括了。真是比之前的Date好用太多了。
Java时间系统的设计者们建议我们如果可能的话尽量使用本地时间,即LocalDateTime/LocalDate/LocalTime,不要使用带有时区或时间偏移量的时间,那样会增加许多复杂性。
如果确实需要处理时区的话,把时区加到用户界面(UI)层来处理。
时间系统的很多类都被设计为值类型,就是在加、减一段时间和设置指定字段的值之后,并不是修改现有实例对象,而是产生了新的实例对象,所以都是线程安全的。
作者个人见解
Java8时间系统,从设计层面来看,很简单,其实越简单越好。从实现层面来看,实现原理也很简单,实现代码也不太复杂。
从API层面来看,常用操作都被支持,方法名称设计非常统一,比较人性化,不会出现每个类各自为政。
最后一点建议:
如果是自己单独使用的话,尽量使用Java8的日期时间,确实好用太多了。
如果是和ORM框架一起使用的话,提前测试一下,因为不一定支持,可能还要使用Date。
(END)
作者现任架构师,工作11年,Java技术栈,计算机基础,用心写文章,喜欢研究技术,崇尚简单快乐。追求以通俗易懂的语言解说技术,希望所有的读者都能看懂并记住。

>>> 热门文章集锦 <<<
毕业10年,我有话说
我是一个协程
我是一个跳表
线程池开门营业招聘开发人员的一天
递归 —— 你值得拥有
迄今为止最好理解的ZooKeeper入门文章
基于角色的访问控制(RBAC)
彻彻底底给你讲明白啥是SpringMvc异步处理
【面试】我是如何面试别人List相关知识的,深度有点长文
我是如何在毕业不久只用1年就升为开发组长的
爸爸又给Spring MVC生了个弟弟叫Spring WebFlux
【面试】我是如何在面试别人Spring事务时“套路”对方的
【面试】Spring事务面试考点吐血整理(建议珍藏)
【面试】吃透了这些Redis知识点,面试官一定觉得你很NB(干货 | 建议珍藏)
【面试】如果你这样回答“什么是线程安全”,面试官都会对你刮目相看(建议珍藏)
【面试】迄今为止把同步/异步/阻塞/非阻塞/BIO/NIO/AIO讲的这么清楚的好文章(快快珍藏)
【面试】一篇文章帮你彻底搞清楚“I/O多路复用”和“异步I/O”的前世今生(深度好文,建议珍藏)
【面试】如果把线程当作一个人来对待,所有问题都瞬间明白了
Java多线程通关———基础知识挑战
品Spring:帝国的基石
>>> 玩转SpringBoot系列文章 <<<
【玩转SpringBoot】配置文件yml的正确打开姿势
【玩转SpringBoot】用好条件相关注解,开启自动配置之门
【玩转SpringBoot】给自动配置来个整体大揭秘
【玩转SpringBoot】看似复杂的Environment其实很简单
【玩转SpringBoot】翻身做主人,一统web服务器
【玩转SpringBoot】让错误处理重新由web服务器接管
【玩转SpringBoot】SpringBoot应用的启动过程一览表
【玩转SpringBoot】通过事件机制参与SpringBoot应用的启动过程
【玩转SpringBoot】异步任务执行与其线程池配置
>>> 品Spring系列文章 <<<
品Spring:帝国的基石
品Spring:bean定义上梁山
品Spring:实现bean定义时采用的“先进生产力”
品Spring:注解终于“成功上位”
品Spring:能工巧匠们对注解的“加持”
品Spring:SpringBoot和Spring到底有没有本质的不同?
品Spring:负责bean定义注册的两个“排头兵”
品Spring:SpringBoot轻松取胜bean定义注册的“第一阶段”
品Spring:SpringBoot发起bean定义注册的“二次攻坚战”
品Spring:注解之王@Configuration和它的一众“小弟们”
品Spring:bean工厂后处理器的调用规则
品Spring:详细解说bean后处理器
品Spring:对@PostConstruct和@PreDestroy注解的处理方法
品Spring:对@Resource注解的处理方法
品Spring:对@Autowired和@Value注解的处理方法
品Spring:真没想到,三十步才能完成一个bean实例的创建
品Spring:关于@Scheduled定时任务的思考与探索,结果尴尬了
加载全部内容