小白学 Python 爬虫(34):爬虫框架 Scrapy 入门基础(二)
极客挖掘机 人气:2
人生苦短,我用 Python
前文传送门:
小白学 Python 爬虫(1):开篇
小白学 Python 爬虫(2):前置准备(一)基本类库的安装
小白学 Python 爬虫(3):前置准备(二)Linux基础入门
小白学 Python 爬虫(4):前置准备(三)Docker基础入门
小白学 Python 爬虫(5):前置准备(四)数据库基础
小白学 Python 爬虫(6):前置准备(五)爬虫框架的安装
小白学 Python 爬虫(7):HTTP 基础
小白学 Python 爬虫(8):网页基础
小白学 Python 爬虫(9):爬虫基础
小白学 Python 爬虫(10):Session 和 Cookies
小白学 Python 爬虫(11):urllib 基础使用(一)
小白学 Python 爬虫(12):urllib 基础使用(二)
小白学 Python 爬虫(13):urllib 基础使用(三)
小白学 Python 爬虫(14):urllib 基础使用(四)
小白学 Python 爬虫(15):urllib 基础使用(五)
小白学 Python 爬虫(16):urllib 实战之爬取妹子图
小白学 Python 爬虫(17):Requests 基础使用
小白学 Python 爬虫(18):Requests 进阶操作
小白学 Python 爬虫(19):Xpath 基操
小白学 Python 爬虫(20):Xpath 进阶
小白学 Python 爬虫(21):解析库 Beautiful Soup(上)
小白学 Python 爬虫(22):解析库 Beautiful Soup(下)
小白学 Python 爬虫(23):解析库 pyquery 入门
小白学 Python 爬虫(24):2019 豆瓣电影排行
小白学 Python 爬虫(25):爬取股票信息
小白学 Python 爬虫(26):为啥买不起上海二手房你都买不起
小白学 Python 爬虫(27):自动化测试框架 Selenium 从入门到放弃(上)
小白学 Python 爬虫(28):自动化测试框架 Selenium 从入门到放弃(下)
小白学 Python 爬虫(29):Selenium 获取某大型电商网站商品信息
小白学 Python 爬虫(30):代理基础
小白学 Python 爬虫(31):自己构建一个简单的代理池
小白学 Python 爬虫(32):异步请求库 AIOHTTP 基础入门
小白学 Python 爬虫(33):爬虫框架 Scrapy 入门基础(一)
引言
在上一篇文章 小白学 Python 爬虫(33):爬虫框架 Scrapy 入门基础(一) 中,我们简单的使用了 Spider 抓取到了我们需要的信息,我们简单的将我所需要的信息通过 print() 的方式打印了在了控制台上。
在我们实际使用爬虫的过程中,我们更多的是需要将数据保存起来,并不是直接输出至控制台,本篇文章接着讲我们如何将 Spider 抓取到的信息保存起来。
Item
Item 的主要目的是从非结构化源(通常是网页)中提取结构化数据。
Scrapy Spider可以将提取的数据作为Python字典返回。Python字典虽然方便且熟悉,但缺乏结构:很容易在字段名称中输入错误或返回不一致的数据,尤其是在具有许多蜘蛛的大型项目中。
为了定义常见的输出数据格式, Scrapy 提供了 Item 该类。 Item 对象是用于收集抓取数据的简单容器。它们提供了类似于字典的 API ,具有方便的语法来声明其可用字段。
接下来,我们来创建一个 Item 。
创建 Item 需要继承 scrapy.Item 类,并且定义类型为 scrapy.Field 的字段。
在前面一篇文章中,我们的目的想要获取的字段有 text 、 author 、 tags 。
那么,我们定义的 Item 类如下,这里直接修改 items.py 文件:
import scrapy
class QuoteItem(scrapy.Item):
text = scrapy.Field()
author = scrapy.Field()
tags = scrapy.Field()接下来就是我们如何要在 first_scrapy 项目中使用这个 Item 了,修改之前的 QuotesSpider 如下:
import scrapy
from first_scrapy.items import QuoteItem
class QuotesSpider(scrapy.Spider):
name = 'quotes'
allowed_domains = ['quotes.toscrape.com']
start_urls = ['http://quotes.toscrape.com/']
def parse(self, response):
quotes = response.css('.quote')
for quote in quotes:
item = QuoteItem()
item['text'] = quote.css('.text::text').extract_first()
item['author'] = quote.css('.author::text').extract_first()
item['tags'] = quote.css('.tags .tag::text').extract()
yield item接下来,我们可以通过最简单的命令行将我们刚才获取到的数据保存为 json 文件,命令如下:
scrapy crawl quotes -o quotes.json执行后可以看到在当前目录下生成了一个名为 quotes.json 的文件,具体内容如下:
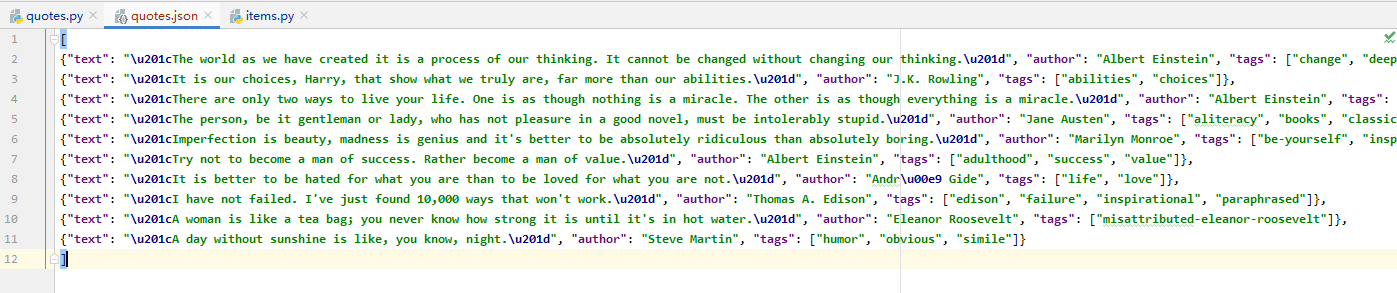
输出格式还支持很多种,例如 csv、xml、pickle、marshal 等,常见的输出语句如下:
scrapy crawl quotes -o quotes.csv
scrapy crawl quotes -o quotes.xml
scrapy crawl quotes -o quotes.pickle
scrapy crawl quotes -o quotes.marshal直到这里,我们简单的将获取到的数据导出成了 json 文件,这就结束了么?
当然没有,前一篇文章我们只是简单的获取了当前页面的内容,如果我们想抓取后续页面的内容怎么做呢?
当然,第一步我们需要先观察后面一页的链接:http://quotes.toscrape.com/page/2 。
接下来,我们需要构造一个访问下一页的请求,这时我们可以使用 scrapy.Request 。
这里我们使用 Request() 先简单的传入两个参数,实际上可以传入的参数远不止两个,这个我们后面再聊。
- url:此请求的URL
- callback:它是回调函数。当指定了该回调函数的请求完成之后,获取到响应,引擎会将该响应作为参数传递给这个回调函数。
那么接下来我们要做的就是使用选择器得到下一页链接并生成请求,使用 scrapy.Request 访问此链接,进行新一轮的数据抓取。
添加的代码如下:
next = response.css('.pager .next a::attr("href")').extract_first()
url = response.urljoin(next)
yield scrapy.Request(url=url, callback=self.parse)现在,改动后的 Spider 类整体代码如下:
# -*- coding: utf-8 -*-
import scrapy
from first_scrapy.items import QuoteItem
class QuotesSpider(scrapy.Spider):
name = 'quotes'
allowed_domains = ['quotes.toscrape.com']
start_urls = ['http://quotes.toscrape.com/']
def parse(self, response):
quotes = response.css('.quote')
for quote in quotes:
item = QuoteItem()
item['text'] = quote.css('.text::text').extract_first()
item['author'] = quote.css('.author::text').extract_first()
item['tags'] = quote.css('.tags .tag::text').extract()
yield item
next = response.css('.pager .next a::attr("href")').extract_first()
url = response.urljoin(next)
yield scrapy.Request(url=url, callback=self.parse)再次使用命令执行这个 Spider ,得到的结果如下(注意,如果前面生成过 json 文件,记得删除后再运行,否则会直接追加写):
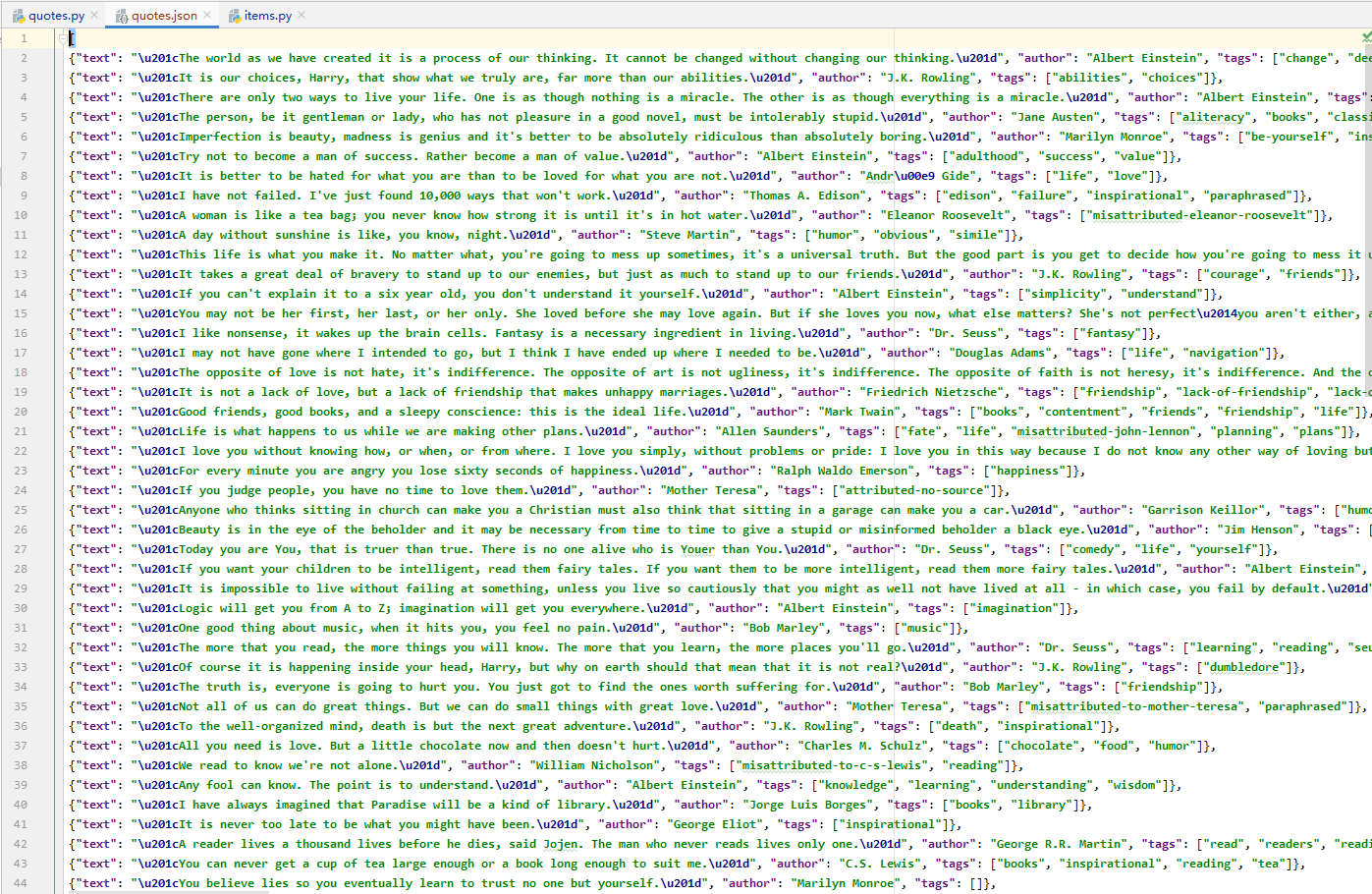
可以看到,数据增加了许多,说明我们抓取后续页面的数据成功。
到这里就结束了么?怎么可能,我们这里只是简单的将数据保存在了 json 文件中,并不方便我们的取用,这里我们可以将数据保存在我们所需要的数据库中。
Item Pipeline
当我们想将数据保存在数据库中时,可以使用 Item Pipeline ,Item Pipeline 为项目管道。
这个管道的典型用途有:
- 清洗 HTML 数据
- 验证爬取数据,检查爬取字段
- 查重并丢弃重复内容
- 将爬取结果储存到数据库
本示例选择保存的数据为 MongoDB ,接下来,我们会将前面查询出来的数据保存在 MongoDB 中。
emmmmmmmmmm,如果要问小编 MongoDB 怎么安装的话,简单来讲,直接使用 Docker 进行安装,只需几个简单的命令即可:
docker pull mongo (拉取镜像 默认最新版本)
docker images (查看镜像)
docker run -p 27017:27017 -td mongo (启动镜像)
docker ps (查看启动的镜像)如果不出意外,以上这几句话执行一下就可以了。连接工具可以使用 Navicat 。
这里我们直接修改 pipelines.py 文件,之前使用命令自动生成的内容可以全都删掉,写入以下内容:
# -*- coding: utf-8 -*-
from scrapy.exceptions import DropItem
class TextPipeline(object):
def process_item(self, item, spider):
if item['text']:
return item
else:
return DropItem('Missing Text')这里我们实现了 process_item() 方法,其参数是 item 和 spider。
这里简单判断了当前的 text 是否存在,如果不存在则直接抛出 DropItem 异常,如果存在则直接返回 item 。
接下来,我们将处理后的 item 存入 MongoDB,定义另外一个 Pipeline。同样在 pipelines.py 中,我们实现另一个类 MongoPipeline,内容如下所示:
import pymongo
class MongoPipeline(object):
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls, crawler):
return cls(mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DB')
)
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def process_item(self, item, spider):
name = item.__class__.__name__
self.db[name].insert(dict(item))
return item
def close_spider(self, spider):
self.client.close()MongoPipeline 类实现了 API 定义的另外几个方法。
- from_crawler,这是一个类方法,用 @classmethod 标识,是一种依赖注入的方式,方法的参数就是 crawler,通过 crawler 这个我们可以拿到全局配置的每个配置信息,在全局配置 settings.py 中我们可以定义 MONGO_URI 和 MONGO_DB 来指定 MongoDB 连接需要的地址和数据库名称,拿到配置信息之后返回类对象即可。所以这个方法的定义主要是用来获取 settings.py 中的配置的。
- open_spider,当 Spider 被开启时,这个方法被调用。在这里主要进行了一些初始化操作。
- close_spider,当 Spider 被关闭时,这个方法会调用,在这里将数据库连接关闭。
最主要的 process_item() 方法则执行了数据插入操作。
定义好 TextPipeline 和 MongoPipeline 这两个类后,我们需要在 settings.py 中使用它们。MongoDB 的连接信息还需要定义。
在 settings.py 中加入如下内容:
ITEM_PIPELINES = {
'first_scrapy.pipelines.TextPipeline': 300,
'first_scrapy.pipelines.MongoPipeline': 400,
}
MONGO_URI='localhost'
MONGO_DB='first_scrapy'再次执行爬取命令:
scrapy crawl quotes执行结果如下:
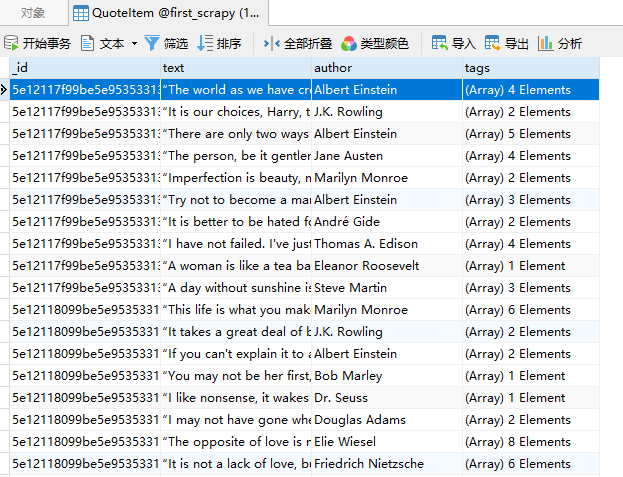
可以看到,在 MongoDB 中创建了一个 QuoteItem 的表,表中保存了我们刚才抓取到的数据。
示例代码
本系列的所有代码小编都会放在代码管理仓库 Github 和 Gitee 上,方便大家取用。
示例代码-Github
示例代码-Gitee
参考
https:/https://img.qb5200.com/download-x/docs.scrapy.org/en/latest/topics/request-response.html
https:/https://img.qb5200.com/download-x/docs.scrapy.org/en/latest/topics/items.html
https://cuiqingcai.com/8337.html
加载全部内容