Linux 系统调用 —— fork 内核源码剖析
陈心朔 人气:2系统调用流程简述
- fork() 函数是系统调用对应的 API,这个系统调用会触发一个int 0x80 的中断;
当用户态进程调用 fork() 时,先将 eax(寄存器) 的值置为 2(即 __NR_fork 系统调用号);
- 执行 int $0x80,cpu 进入内核态;
执行 SAVE_ALL,保存所有寄存器到当前进程内核栈中;

- 进入 sys_call,将 eax 的值压栈,根据系统调用号查找 system_call_table ,调用对应的函数;
函数返回,执行 RESTORE_ALL,恢复保存的寄存器;执行 iret,cpu 切换至用户态;

从 eax 中取出返回值,fork() 返回;
详见:系统调用的工作机制
fork 在内核中做了什么

当我们调用 fork()、clone()、vfork() 时,实际上在内核中调用的都是同一个函数 —— do_fork()

这里的三个系统调用的区别就在于调用 do_fork() 时传入的参数不同
do_fork() 中第一个参数 clone_flags 是一个 32bit 的标志,其中不同的 bit 置 1 代表不同的选项,表示新的子进程与父进程之间共享哪些资源
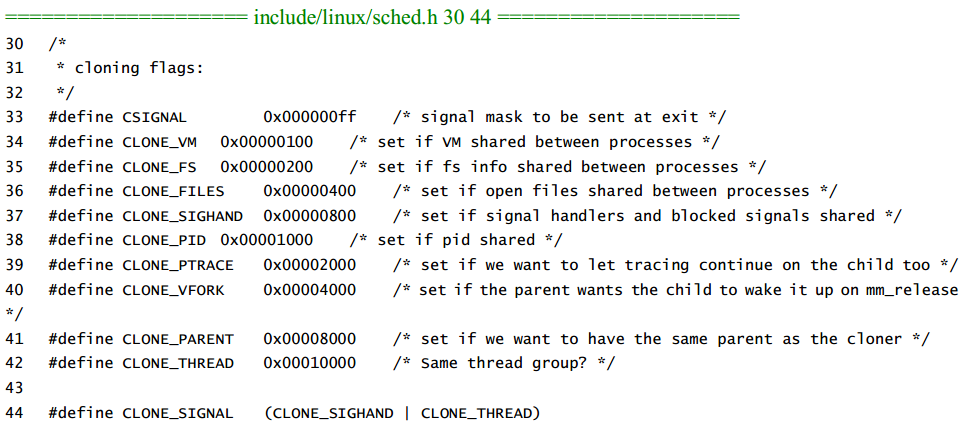
其中 sys_fork() 调用 do_fork() 只设置了 SIGCHLD 选项,sys_vfork() 设置了 CLONE_VM | CLONE_VFORK | SIGCHLD 选项,而 sys_clone() 的参数来自上层,通过 ebx 传入;
下面简述下 do_fork() 的执行过程
do_fork()
- 查找 pidmap_array 位图,为子进程分配新的 pid;
- 调用 copy_process() ,将新的 pid 传入参数,这个函数是创建进程的关键步骤,该函数返回新的 task_struct 地址;

copy_process()
- 创建 task_struct 结构体指针;
- 检查参数;
- 调用 dup_task_struct() ,将父进程 task_struct 传入参数,为子进程获取进程描述符;

dup_task_struct()
- 创建 task_struct 、thread_info 结构体指针;
struct task_struct *tsk;
struct thread_info *ti;- 调用 alloc_task_struct() 宏为新进程获取进程描述符,并保存至 tsk 中;
tsk = alloc_task_struct();
if (!tsk)
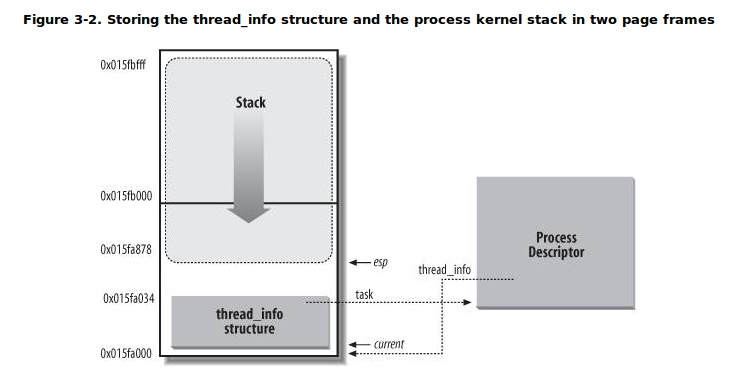
return NULL;- 调用 alloc_thread_info() 宏获取一块空闲内存区,保存在 ti 中(这块内存的大小为 8K/4k,用来存放新进程的 thread_info 结构体和内核栈)

struct task_struct
{
struct thread_info * thread_info; // 指向 thread_info 的指针
struct mm_struct * mm; // 进程地址空间
pid_t pid;
struct list_head children; // 子进程链表
...
}
struct thread_info
{
struct task_struct task; // 指向 task_struct 的指针
_u32 cpu; // 当前所在的cpu
mm_segment_t addr_limit; // 线程地址空间
// user_thread 0-0xBFFFFFFF
// kernel_thread 0-0xFFFFFFFF
...
}
// thread_info 和 stack 共享一块内存
union thread_union
{
struct thread_info thread_info;
unsigned long stack[THREAD_SIZE/sizeof(long)];
};- 复制进程描述符和 thread_info,并将两者中的互指指针初始化;
*ti = *current->thread_info;
ti->task = tsk;- 将新进程描述符的使用计数器 usage 置为2,表示描述符正在被使用而其对应的进程处于活动状态;
新进程的进程描述符创建完成,返回至 copy_process()
- 检查当前用户所拥有的进程数是否超过了限制的值(1024),有root权限除外;若超过了限制则返回错误码,否则增加用户拥有的进程计数;
atomic_inc(p->user->process);检查系统中的进程数量是否超过了 max_threads;
max_threads的数量由系统内存容量决定,所有的thread_info描述符和内核栈所占用空间不能超过系统内存的1/8;拷贝所有的进程信息:

- 其中最重要的是 copy_mm() ,该函数通过建立新进程所有页表和内存描述符来创建进程地址空间;

struct mm_struct
{
struct vm_area_struct * mmap; // 指向线性区对象的链表头
struct rb_root mm_rb; // 指向线性区对象的红黑树的根
pgd_t * pgd; // 指向页全局目录
atomic_t mm_users; // 次使用计数器,存放共享 mm_struct 数据结构轻量级进程的个数
atomic_t mm_count; // 主使用计数器,每当 mm_count 递减,内核就要检查它是否为0,如果是就要解除这个内存描述符
}copy_mm()
- 创建 mm_struct * mm, oldmm 结构体指针(内存描述符);
oldmm = current->mm; //oldmm 初始化为父进程的 mm_struct- 检查 clone_flags 是否设置了 CLONE_VM 位;
若设置了 CLONE_VM 位,则表示创建线程,与父进程共享地址空间
atomic_inc(&oldmm->mm_users); // 父进程的地址空间引用计数加一
mm = oldmm; // 将父进程地址空间赋给子进程- 否则,就要创建新的地址空间,并从当前进程复制 mm 的内容
mm = allocate_mm();
memcpy(mm, oldmm, sizeof(*mm));- 调用 dup_mmap() 复制父进程的线性区和页表

dup_mmap()
- 复制父进程每个 vm_area_struct 线性区描述符,插入到子进程的线性区链表和红黑树中;
struct vm_area_struct
{
struct mm_struct * vm_mm; // 指向线性区所在的内存描述符
unsigned long vm_start; // 当前线性区起始地址
unsigned long vm_end; // 线性区尾地址
struct vm_area_struct * vm_next; // 下一个线性区
pgprot_t vm_page_prot; // 线性区访问权限
struct rb_node vm_rb; // 用于红黑树搜索的节点
}- 用 copy_page_range() 创建新的页表,在新的 vm_area_struct 中链接并复制父进程的页表条目;
copy_page_range()
- 创建新的页表;
- 复制父进程的页表来初始化子进程的新页表;
私有/可写的页( VM_SHARED 标志关闭/ VM_MAYWRITE 标志打开)所对应的权限父子进程都设为只读,以便于 Copy-on-write 机制处理。
新进程的线性区和页表复制完成,返回至copy_process()
调用 copy_thread() 用父进程的内核栈初始化子进程的内核栈
copy_thread()
将eax的值强制设为0(fork / clone 系统调用的返回值)
childregs->eax = 0;sched_fork()
- 调用 sched_fork() 完成对新进程调度程序数据结构的初始化,将新进程状态设为 TASK_RUNNING
- 为了公平起见,父子进程共享父进程的时间片
进程创建完成,返回至 do_fork()
- 如果设置 CLONE_STOPPED,就将子进程设置 TASK_STOPPED 状态并挂起;
否则调用 wake_up_new_task() 调整父子进程的调度参数;
wake_up_new_task()
- 如果父子进程运行在同一个 cpu 上,并且不能共享同一组页表 (CLONE_VM 位为 0),就把子进程插入运行队列中的父进程之前;
如果子进程创建之后调用 exec 执行新程序,就可以避免写时拷贝机制执行不必要的页面复制;
否则,如果运行在不同的cpu上,或父子共享同一组页表,就将子进程插入运行队列的队尾。
返回至 do_fork()
- 返回子进程的 pid
2017/8/3 补充
fork() 和 vfork() 参数是写死的,而 clone() 是可选的,它可以选择当前创建的进程哪些部分是共享的,哪些部分是独立的;
vfork() 是历史的产物,当调用 fork() 的时候,需要将父进程的线性区和页表都拷贝一份,而调用 exec() 执行新程序后,又要把所有页表删除重置新的页表,建立映射关系,效率很低;
所以要有 vfork(),vfork() 的 clone_flags 位置了 CLONE_VM ,表示共享父进程的地址空间,vfork() 中创建的进程没有分配自己的地址空间,而是通过一个 mm_struct 指针指向父进程的地址空间,这个进程是为了在之后调用 exec() 执行新的程序;
而在有了 Copy-on-write 技术后,fork() 出的子进程只创建了自己的地址空间,然后用父进程的地址空间初始化,每个页表的项置为父进程的页表项,共享父进程的物理页面,并将所有 私有/可写 页面改为只读;
当我们改变父子进程的数据后,cpu 在运行过程中会发生一个缺页错误,cpu 转交控制权给操作系统,操作系统查找 VMA 发现该页权限为只读,但所在段又是可写的,产生一个矛盾,这就是识别 Copy-on-write 的方法,接着 OS 给子进程分配一个新的物理页,并将页表该页的地址修改成新的物理页地址;
这样 fork() 后再调用 exec() 就不用那么麻烦了,可以直接将新的物理页与子进程的虚拟空间建立映射
小结
综上,fork 在创建子进程时,主要做了这些工作
- 为子进程分配新的 pid,并通过父进程 PCB(task_struct)创建新的子进程 PCB
- 检查进程数是否达到上限(分别检查用户限制和系统限制)
- 拷贝所有的进程信息(打开的文件 / 信号处理 / 进程地址空间等),这里需要拷贝的选项由调用 do_fork() 时传入的参数 clone_flags 决定
- 用父进程的内核栈初始化子进程的内核栈,设置子进程的返回值为 0(eax = 0)
- 设置新进程的状态(TASK_RUNNING / TASK_STOPPED),调整父子进程调度
- 父进程 fork 返回子进程的 pid
加载全部内容