【原创】(十一)Linux内存管理slub分配器
LoyenWang 人气:2背景
Read the fucking source code!--By 鲁迅A picture is worth a thousand words.--By 高尔基
说明:
- Kernel版本:4.14
- ARM64处理器,Contex-A53,双核
- 使用工具:Source Insight 3.5, Visio
1. 概述
之前的文章分析的都是基于页面的内存分配,而小块内存的分配和管理是通过块分配器来实现的。目前内核中,有三种方式来实现小块内存分配:slab, slub, slob,最先有slab分配器,slub/slob分配器是改进版,slob分配器适用于小内存嵌入式设备,而slub分配器目前已逐渐成为主流块分配器。接下来的文章,就是以slub分配器为目标,进一步深入。
先来一个初印象:
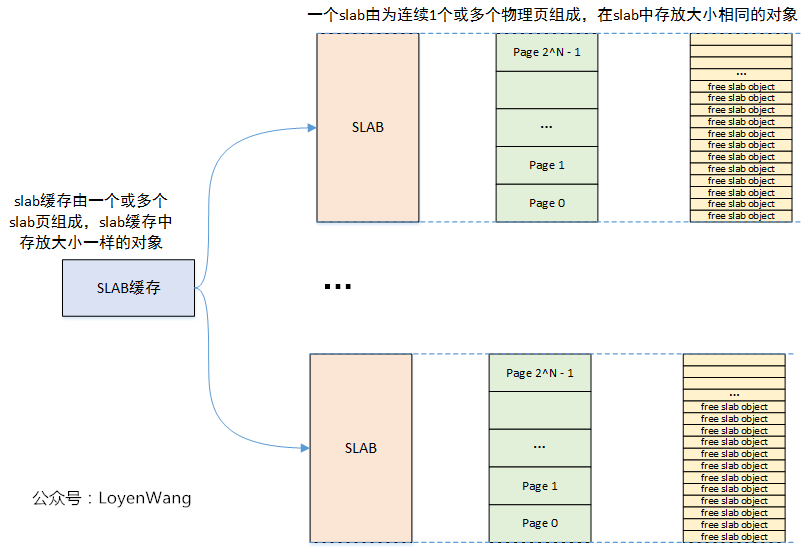
2. 数据结构
有四个关键的数据结构:
struct kmem_cache:用于管理SLAB缓存,包括该缓存中对象的信息描述,per-CPU/Node管理slab页面等;
关键字段如下:
/*
* Slab cache management.
*/
struct kmem_cache {
struct kmem_cache_cpu __percpu *cpu_slab; //每个CPU slab页面
/* Used for retriving partial slabs etc */
unsigned long flags;
unsigned long min_partial;
int size; /* The size of an object including meta data */
int object_size; /* The size of an object without meta data */
int offset; /* Free pointer offset. */
#ifdef CONFIG_SLUB_CPU_PARTIAL
/* Number of per cpu partial objects to keep around */
unsigned int cpu_partial;
#endif
struct kmem_cache_order_objects oo; //该结构体会描述申请页面的order值,以及object的个数
/* Allocation and freeing of slabs */
struct kmem_cache_order_objects max;
struct kmem_cache_order_objects min;
gfp_t allocflags; /* gfp flags to use on each alloc */
int refcount; /* Refcount for slab cache destroy */
void (*ctor)(void *); // 对象构造函数
int inuse; /* Offset to metadata */
int align; /* Alignment */
int reserved; /* Reserved bytes at the end of slabs */
int red_left_pad; /* Left redzone padding size */
const char *name; /* Name (only for display!) */
struct list_head list; /* List of slab caches */ //kmem_cache最终会链接在一个全局链表中
struct kmem_cache_node *node[MAX_NUMNODES]; //Node管理slab页面
};struct kmem_cache_cpu:用于管理每个CPU的slab页面,可以使用无锁访问,提高缓存对象分配速度;
struct kmem_cache_cpu {
void **freelist; /* Pointer to next available object */ //指向空闲对象的指针
unsigned long tid; /* Globally unique transaction id */
struct page *page; /* The slab from which we are allocating */ //slab缓存页面
#ifdef CONFIG_SLUB_CPU_PARTIAL
struct page *partial; /* Partially allocated frozen slabs */
#endif
#ifdef CONFIG_SLUB_STATS
unsigned stat[NR_SLUB_STAT_ITEMS];
#endif
};struct kmem_cache_node:用于管理每个Node的slab页面,由于每个Node的访问速度不一致,slab页面由Node来管理;
/*
* The slab lists for all objects.
*/
struct kmem_cache_node {
spinlock_t list_lock;
#ifdef CONFIG_SLUB
unsigned long nr_partial; //slab页表数量
struct list_head partial; //slab页面链表
#ifdef CONFIG_SLUB_DEBUG
atomic_long_t nr_slabs;
atomic_long_t total_objects;
struct list_head full;
#endif
#endif
};struct page:用于描述slab页面,struct page结构体中很多字段都是通过union联合体进行复用的。
struct page结构中,用于slub的成员如下:
struct page {
union {
...
void *s_mem; /* slab first object */
...
};
/* Second double word */
union {
...
void *freelist; /* sl[aou]b first free object */
...
};
union {
...
struct {
union {
...
struct { /* SLUB */
unsigned inuse:16;
unsigned objects:15;
unsigned frozen:1;
};
...
};
...
};
};
/*
* Third double word block
*/
union {
...
struct { /* slub per cpu partial pages */
struct page *next; /* Next partial slab */
#ifdef CONFIG_64BIT
int pages; /* Nr of partial slabs left */
int pobjects; /* Approximate # of objects */
#else
short int pages;
short int pobjects;
#endif
};
struct rcu_head rcu_head; /* Used by SLAB
* when destroying via RCU
*/
};
...
struct kmem_cache *slab_cache; /* SL[AU]B: Pointer to slab */
...
}图来了:

3. 流程分析
针对Slub的使用,可以从三个维度来分析:
- slub缓存创建
- slub对象分配
- slub对象释放
下边将进一步分析。
3.1 kmem_cache_create
在内核中通过kmem_cache_create接口来创建一个slab缓存。
先看一下这个接口的函数调用关系图:

kmem_cache_create完成的功能比较简单,就是创建一个用于管理slab缓存的kmem_cache结构,并对该结构体进行初始化,最终添加到全局链表中。kmem_cache结构体初始化,包括了上文中分析到的kmem_cache_cpu和kmem_cache_node两个字段结构。在创建的过程中,当发现已有的
slab缓存中,有存在对象大小相近,且具有兼容标志的slab缓存,那就只需要进行merge操作并返回,而无需进一步创建新的slab缓存。calculate_sizes函数会根据指定的force_order或根据对象大小去计算kmem_cache结构体中的size/min/oo等值,其中kmem_cache_order_objects结构体,是由页面分配order值和对象数量两者通过位域拼接起来的。在创建
slab缓存的时候,有一个先鸡后蛋的问题:kmem_cache结构体来管理一个slab缓存,而创建kmem_cache结构体又是从slab缓存中分配出来的对象,那么这个问题是怎么解决的呢?可以看一下kmem_cache_init函数,内核中定义了两个静态的全局变量kmem_cache和kmem_cache_node,在kmem_cache_init函数中完成了这两个结构体的初始化之后,相当于就是创建了两个slab缓存,一个用于分配kmem_cache结构体对象的缓存池,一个用于分配kmem_cache_node结构体对象的缓存池。由于kmem_cache_cpu结构体是通过__alloc_percpu来分配的,因此不需要创建一个相关的slab缓存。
3.2 kmem_cache_alloc
kmem_cache_alloc接口用于从slab缓存池中分配对象。
看一下大体的调用流程图:

从上图中可以看出,分配slab对象与Buddy System中分配页面类似,存在快速路径和慢速路径两种,所谓的快速路径就是per-CPU缓存,可以无锁访问,因而效率更高。
整体的分配流程大体是这样的:优先从per-CPU缓存中进行分配,如果per-CPU缓存中已经全部分配完毕,则从Node管理的slab页面中迁移slab页到per-CPU缓存中,再重新分配。当Node管理的slab页面也不足的情况下,则从Buddy System中分配新的页面,添加到per-CPU缓存中。
还是用图来说明更清晰,分为以下几步来分配:
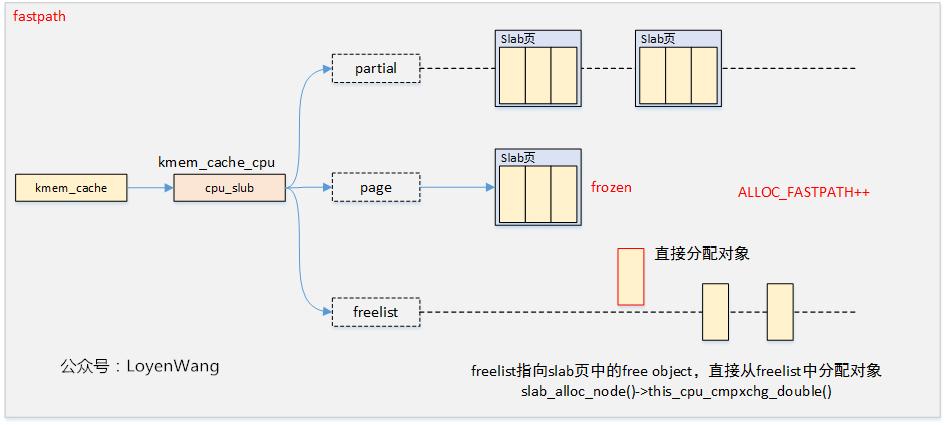
fastpath
快速路径下,以原子的方式检索per-CPU缓存的freelist列表中的第一个对象,如果freelist为空并且没有要检索的对象,则跳入慢速路径操作,最后再返回到快速路径中重试操作。
slowpath-1
将per-CPU缓存中page指向的slab页中的空闲对象迁移到freelist中,如果有空闲对象,则freeze该页面,没有空闲对象则跳转到slowpath-2。

slowpath-2
将per-CPU缓存中partial链表中的第一个slab页迁移到page指针中,如果partial链表为空,则跳转到slowpath-3。
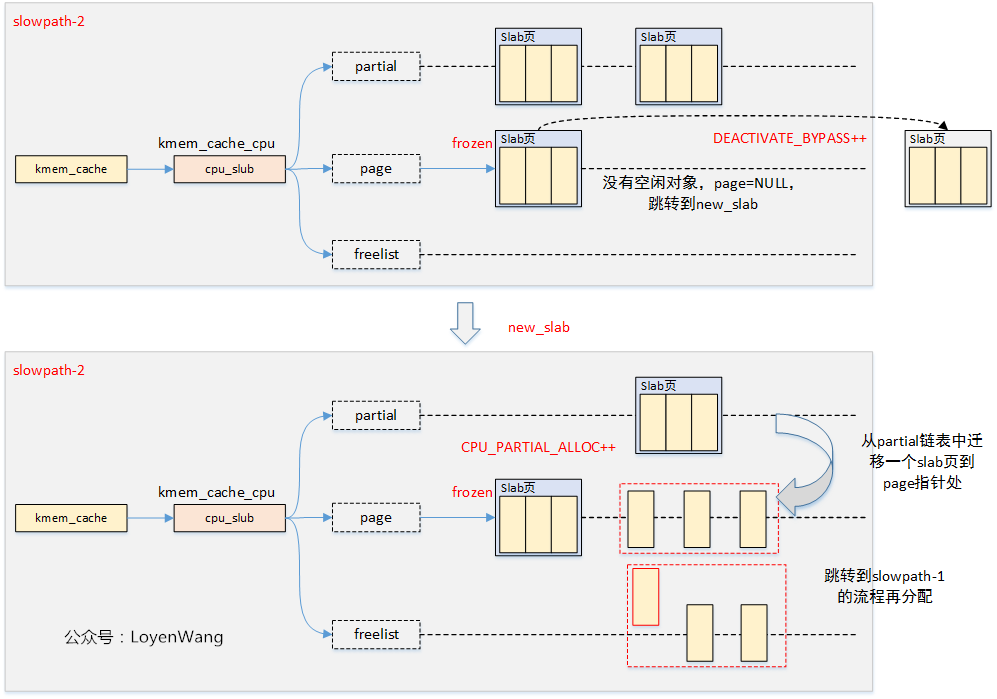
slowpath-3
将Node管理的partial链表中的slab页迁移到per-CPU缓存中的page中,并重复第二个slab页将其添加到per-CPU缓存中的partial链表中。如果迁移的slab中空闲对象超过了kmem_cache.cpu_partial的一半,则仅迁移slab页,并且不再重复。
如果每个Node的partial链表都为空,跳转到slowpath-4。

slowpath-4
从Buddy System中获取页面,并将其添加到per-CPU的page中。

3.2 kmem_cache_free
kmem_cache_free的操作,可以看成是kmem_cache_alloc的逆过程,因此也分为快速路径和慢速路径两种方式,同时,慢速路径中又分为了好几种情况,可以参考kmem_cache_alloc的过程。
调用流程图如下:

效果如下:
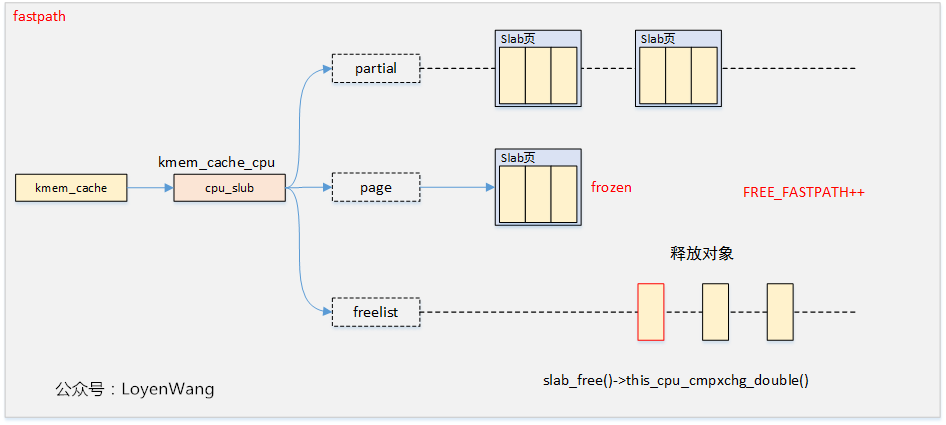
快速路径释放
快速路径下,直接将对象返回到freelist中即可。
put_cpu_partial
put_cpu_partial函数主要是将一个刚freeze的slab页,放入到partial链表中。
在put_cpu_partial函数中调用unfreeze_partials函数,这时候会将per-CPU管理的partial链表中的slab页面添加到Node管理的partial链表的尾部。如果超出了Node的partial链表,溢出的slab页面中没有分配对象的slab页面将会返回到伙伴系统。

add_partial
添加slab页到Node的partial链表中。

remove_partial
从Node的partial链表移除slab页。

具体释放的流程走哪个分支,跟对象的使用情况,partial链表的个数nr_partial/min_partial等相关,细节就不再深入分析了。
加载全部内容